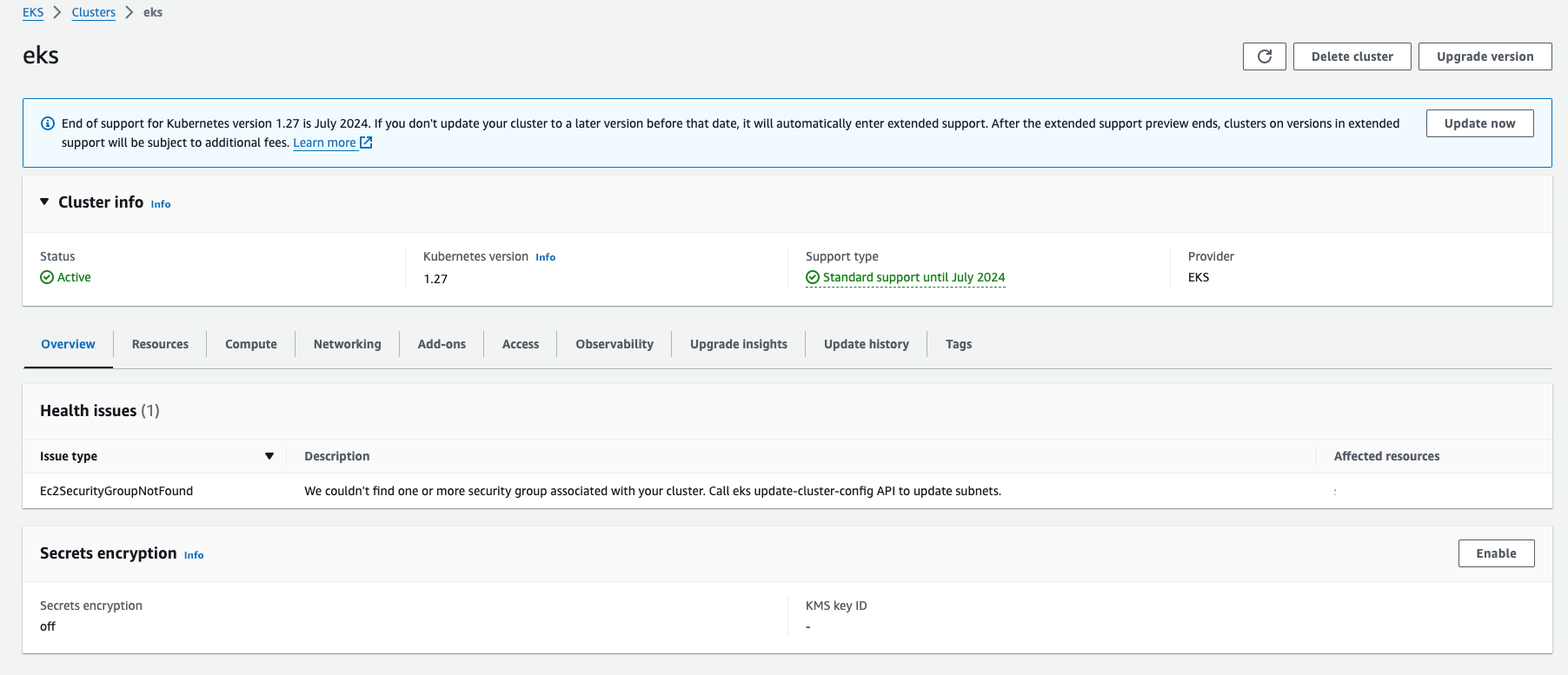
使用 EKS Cluster Health 信息监控你的集群健康状态
作为 AWS 用户,监控 Elastic Kubernetes Service (EKS) 集群的健康状态对于确保其稳定性和性能至关重要。在过去,通常需要在 EKS 集群遇到问题(例如,无法升级集群)时才会发现 EKS 集群出现了一些非预期的错误,并没有一种很好的方式或是监控能够直接了解可能破坏 EKS 集群的因素。但最近,Amazon EKS 在 EKS 控制台和 API 中引入了一个小变更,提供了对集群健康状态的增强可见性,让 EKS 用户可以更好地了解其集群的健康状态。
这个更新是什么?
在 2023 年 12 月 28 日,Amazon EKS 宣布支持集群健康状态详细信息1。
这项健康状态信息有助于 EKS 用户快速诊断、排除和解决集群问题。因为底层基础设施或配置问题可能导致 EKS 集群受损,并阻止 EKS 应用更新或升级到较新的 Kubernetes 版本(例如:意外删除 EKS 集群关联的 Subnet 或是 Security Group)。一般来说,EKS 用户负责配置集群基础设施,例如 IAM Role 和 VPC 以及 Subnet 等。这项更新减少了 EKS 用户需要花费大量时间和精力在进行基础设施问题上调试的时间,使运行稳健的 Kubernetes 环境变得更加容易。
在本篇内容,我们将讨论这个新功能以及如何利用这项健康状态信息有效监控您的 EKS 集群。
监控您的 EKS 集群的健康状态
为什么要监控 EKS 集群健康状态
监控 EKS 集群健康状态能帮助您随时了解集群的整体健康状态。若通过接收即时通知,可以快速识别任何问题或潜在问题,并立即响应且采取行动解决。这种主动的方法有助于防止任何 EKS 运行环境中非预期的错误,确保 EKS 集群的顺利运行。
DescribeCluster API 调用
监控 EKS 集群健康状态的第一种方法是利用 DescribeCluster API。这个 API 调用返回的内容中新增了一个新的字段,用于了解有关集群的详细健康信息,包括其当前状态、几种不同的错误码2和任何发现的问题,帮助 EKS 用户了解有关集群的健康状态和性能的洞察。以下是使用 AWS CLI 命令输出的一个范例:
$ aws eks describe-cluster --name eks --region eu-west-1
{
"cluster": {
"name": "eks",
"arn": "arn:aws:eks:eu-west-1:11222334455:cluster/eks",
"createdAt": "2024-01-23T20:51:44.751000+00:00",
"version": "1.27",
}
"health": {
"issues": []
}
}
}
程序设计开发者可以通过这项 API 变更设计属于自己的监控逻辑,并且使用程序化的逻辑完成特定的自动化工作。
EKS 控制台
除了上述的 API 操作,也可以通过 EKS Console 界面监控 EKS 集群的健康状态。在 EKS 控制台中,新增加了一个新的区块会显示整体集群的健康状态,并且获取有关集群健康状态的即时信息。
整合 Slack 通知进行监控
目前,EKS 这项更新并未支持主动通知或 CloudWatch 事件,这意味着如果需要通过可程序化逻辑了解目前的健康状态,您需要手动调用 API。如果要要设定 EKS 集群健康状态的监控并接收通知,除了自己写程序逻辑并且定时运行,也可以考虑使用 EventBridge 服务进行整合。EventBridge 是由 AWS 提供的一项服务,可让您在不同的 AWS 服务和外部应用程序之间进行事件的触发操作,甚至设置定时事件来触发操作 (类似 cron job)。在现阶段,一种简单的做法是可以通过设定 EventBridge Scheduler 来触发 AWS Lambda (Lambda function),在 Lambda function 可以执行自行撰写的程序逻辑,可以通过这项服务进行 DescribeCluster API 调用,并且整合其他应用,便于在集群健康状态有变更或更新时收到即时通知。
下面是我实施的简单解决方案:
解决方案概述
- 创建一个 Lambda 函数(MoninitorEKSClusterHealth)并且在程序中使用
DescribeClusterAPI 调用检查 EKS 集群是否有健康问题状态 - 关联 Slack 频道与 AWS ChatBot,并且在与 AWS ChatBot 整合的过程中会一同创建一个 SNS Topic 用于发送任何通知
- 使用 EventBridge Scheduler 设置定时触发条件,定期调用 Lambda 函数(MoninitorEKSClusterHealth)。如果集群有健康问题,它会在执行期间抛出错误。
- 创建 CloudWatch alarm 以监控 Lambda 函数(MoninitorEKSClusterHealth)的错误,并在有错误事件时,触发指定的 SNS Topic (这会直接进行即时的 Slack 通知)
创建 Lambda 函数
第一步是创建一个 Lambda 函数 (在这里称为 MoninitorEKSClusterHealth),这个小程序可以帮助我们了解 EKS 集群的健康状态并捕获任何错误,以下是我使用 Python 的一个简单范例:
import json
import boto3
def describe_eks_cluster(cluster_name):
eks_client = boto3.client('eks')
response = eks_client.describe_cluster(name=cluster_name)
health_issues = response['cluster']['health']['issues']
if len(health_issues) > 0:
raise Exception("Cluster has health issues: {0}".format(health_issues))
return response
def lambda_handler(event, context):
cluster_name = event['eks-cluster-name']
cluster_info = ''
cluster_info = describe_eks_cluster(cluster_name)
print(cluster_info)
return {
'statusCode': 200,
'body': 'success'
}
使用 DescribeCluster API 当集群有健康问题时,API 响应会在健康问题的字段中返回详细信息。例如,在一个关联 Security Group 被意外删除的 EKS 集群中存在健康问题状态,以下是从我的 MoninitorEKSClusterHealth 函数的记录文件中捕获的错误消息。它表明事件中存在一个与集群健康问题相关的异常。具体的错误是 Ec2SecurityGroupNotFound:
[ERROR] Exception: Cluster has health issues:
['code': 'Ec2SecurityGroupNotFound',
'message': "We couldn't find one or more security group associated with your cluster. Call eks update-cluster-config API to update subnets.",
'resourceIds': ['sg-XXXXXXX']
Traceback (most recent call last):
File "/var/task/Lambda_function.py", line 18, in lambda_handler
cluster_info = describe_eks_cluster(cluster_name)
File "/var/task/lambda_function.py", line 10, in describe_eks_cluster raise Exception("Cluster has health issues: {01" format(health_issues))
在 Python 程序中设计逻辑中,当发现有 EKS 集群健康问题抛出异常错误是关键,因为这种错误可以在 AWS Lambda 提供的 CloudWatch metric 生成错误,并且方便我们在后续能直接通过创建 AWS Lambda 的 CloudWatch alarm 来监控状态。
在 AWS EventBridge Scheduler 中创建定期排程触发规则
监控 EKS 集群健康状态的下一步是在 AWS EventBridge Scheduler 中创建一个新的规则以定期触发执行我们在 AWS Lambda 上部署的应用程序。我同时也指定了在 AWS Lambda 函数中定义的 eks-cluster-name 参数,指定要监控的 EKS 集群名称,以便在触发我在 AWS Lambda 上部署的应用程序时知道我要检查哪个 EKS 集群。
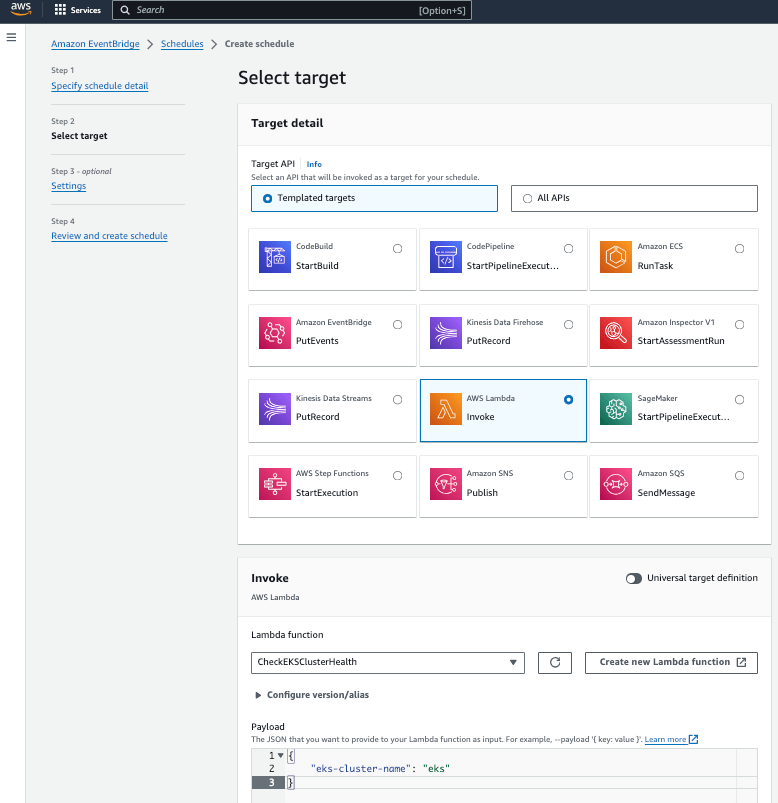
此外,在我的环境中,为了避免短时间同时产生大量的 API 请求调用,我以 60 分钟为触发条件 (视情况甚至可以考虑 24 小时或是更长),大部分情况下并不会短时间内大量变更 AWS 资源的网络拓扑、资源组态和设定 (例如通常可能只发生在每日的尖峰工作时段、例行的部署变更维护窗口或特定时间的部署行为),短时间进行这项健康问题检查并不是一个很理想的设计,这可能会产生大量不必要的运算资源和 Lambda 运行费用。
设置 CloudWatch Alarm 警报
一旦设定好一个定期触发规则和可以返回 EKS 健康状态的应用程序来报告集群健康情况,我们可以设置一个 CloudWatch Alarm 警报,并且仅监控这个 Lambda 函式 (MoninitorEKSClusterHealth) 以捕捉任何错误。在我的环境中,我设定了一个 CloudWatch Alarm,并且监控 Lambda 函式 (MoninitorEKSClusterHealth) 下的 Erros 指标(该指标属于 AWS/Lambda 命名空间):
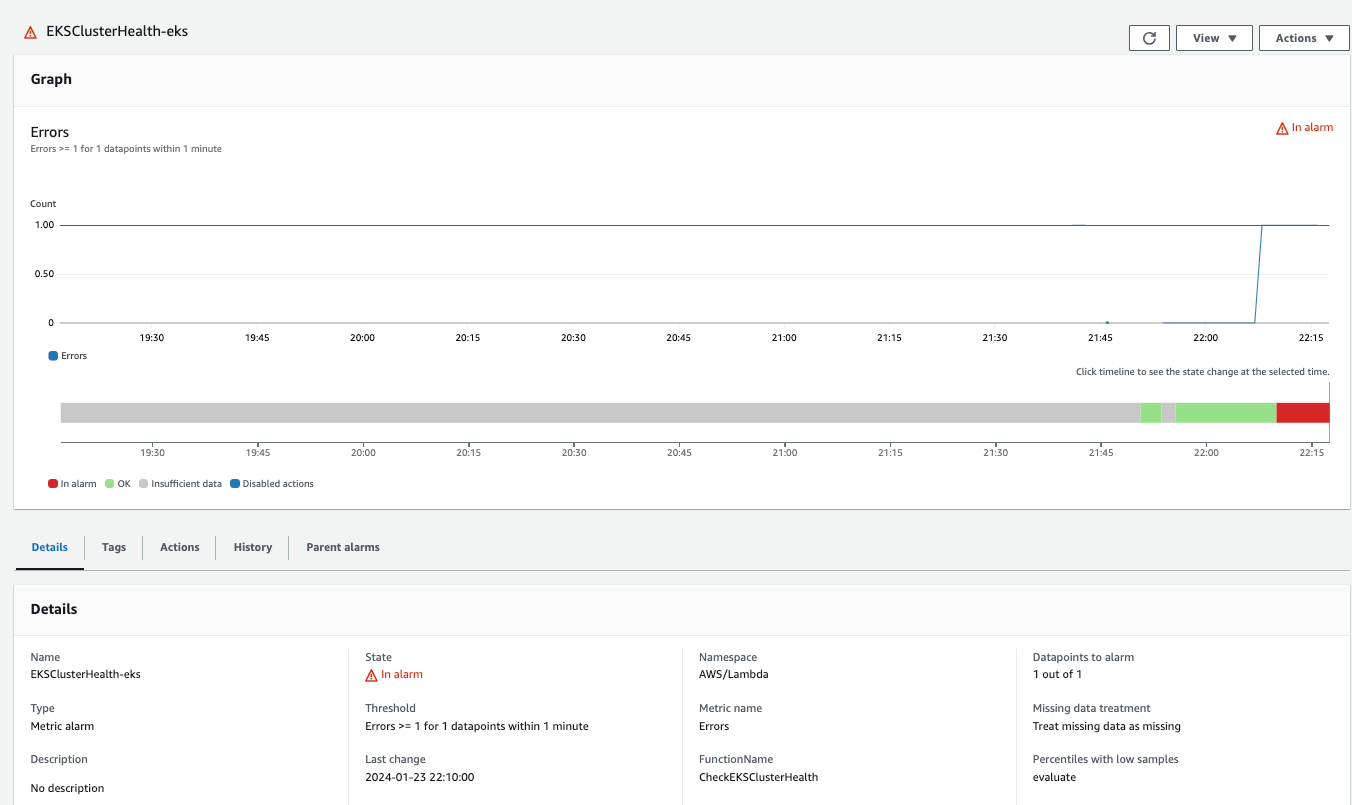
并且在发生警报时触发动作是将消息通知传递至先前 AWS ChatBot 整合的过程中一同创建的一个 SNS Topic。
如果 EKS 集群有任何健康问题,Lambda 函式在执行时将抛出错误,并且 CloudWatch Alarm 警报将会翻转为 In alarm 状态,通过 CloudWatch Alarm 警报,将会将通知发送至我们指定的 SNS Topic,实时通过 AWS ChatBot 触发 Slack 通知。在我的账号中,我已经预先设定了 AWS ChatBot (Slack chatbot) 并订阅了一个 SNS Topic3。帮助我可以在 EKS 集群发生健康问题时,获得更新并立即采取行动来解决 EKS 集群的任何问题。
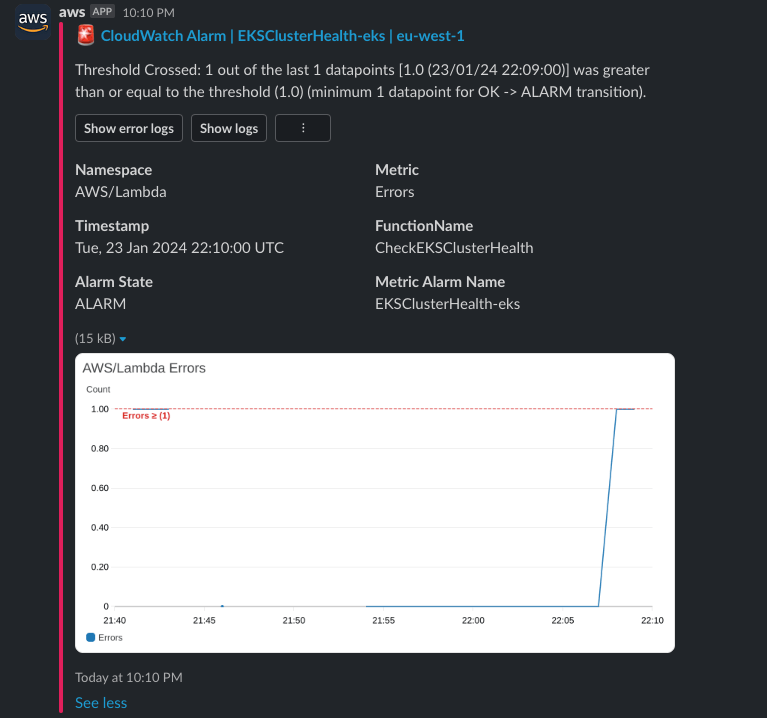
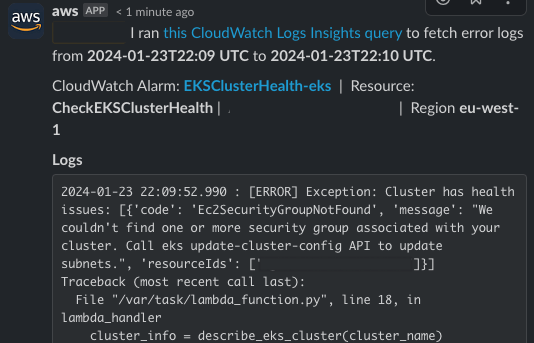
AWS Chatbot 还提供查看 Lambda 函式的错误日志的功能,在我们的应用程序中会直接显示 DescribeCluster API 的详细信息,这对于能在数分钟内通过 Slack 的聊天窗口能直接了解为什么 EKS 集群出现健康问题非常有用:
总结
总结此篇内容,监控您的 EKS 集群的健康状态对于维护其稳定性、性能和安全性至关重要。通过这项功能性的更新,利用 DescribeCluster API 调用或查看 EKS 控制台上的信息,可以随时了解 EKS 集群过去难以察觉的设定问题或是其他非预期错误,能够更容易发现并且采取行动解决。
此外,这篇内容不但介绍了如何使用 DescribeCluster API 调用的相关细节,并且也分享了如何通过整合不同 AWS 服务,包含 EventBridge、AWS Lambda 和 CloudWatch 等,在集群健康状态发生变化时,能够获得实时的 Slack 消息通知,节省调试时间并且简化维运 EKS 工作。
参考资料
