EKS Load Balancing 最佳实践:Service、NLB、ALB 与 IP Targets
在 Amazon EKS 上做 Load Balancing,看起来很简单;但只要开始追踪一个 request 到底经过哪些节点、最后打到哪个 Pod,事情就会变得复杂。
Kubernetes LoadBalancer Service 可以创建 AWS Load Balancer,kube-proxy 可能又在节点上重新转发一次,Ingress controller 也可能再加一层 routing。每一层本身都合理,但叠在一起之后,就可能造成额外 hop、流量分配不均,以及更难排查的网络问题。
这篇把我过去三篇 EKS Load Balancing 系列整理成单篇,也补上目前在 EKS 上更推荐的做法:
- 使用 AWS Load Balancer Controller 或 EKS Auto Mode 来集成 AWS 原生 Load Balancer。
- 当 Load Balancer 应该直接打到 Pod 时,优先使用 IP targets。
- 只有在明确需要其行为时,才使用 instance targets 或 NGINX Ingress。
- 除非应用程序确实需要 session affinity,否则避免启用 sticky behavior。
- 让 Pods 平均分布在 Availability Zones,让 Load Balancer 有健康且均衡的 targets。
为什么默认 Service 路径会增加复杂度
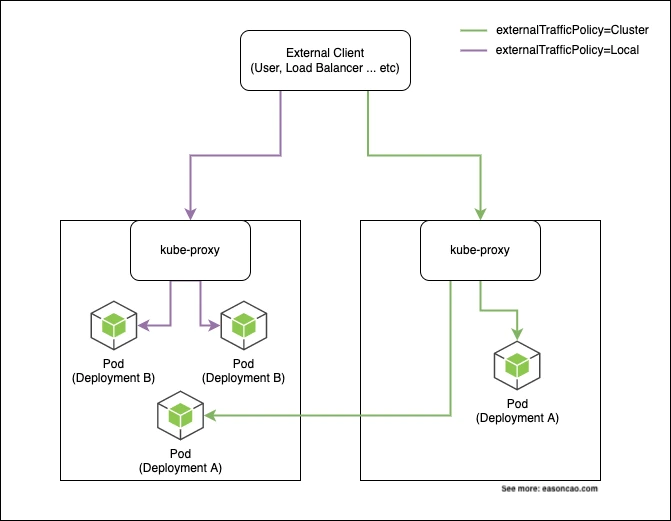
Kubernetes Service 为 Pod 前面提供稳定的网络入口。当 Service 对外暴露时,Kubernetes 还需要决定外部流量要如何抵达被 Service selector 选中的 Pods。这里最重要的字段是 spec.externalTrafficPolicy。
Kubernetes 支持两种设置:
Cluster:流量可以被转发到集群中任意节点上的 Pod。Local:流量只会发送到收到 request 的那台节点上的本地 Pod。
Local 不代表 Kubernetes 完全停止 Service 层级的 load balancing。如果同一台节点上有多个符合条件的 Pods,kube-proxy 仍然可以在这些本地 endpoints 之间分配流量。关键差异在于,流量不会再被转发到其他节点上的 Pods。
默认情况下,kube-proxy 会通过 iptables 或 IPVS 在节点上实现 Service load balancing。以 iptables mode 来说,节点上会生成类似下面这种按概率分配的规则:
-A KUBE-SVC-XXXXX -m statistic --mode random --probability 0.20000000019 -j KUBE-SEP-AAAAAA
-A KUBE-SVC-XXXXX -m statistic --mode random --probability 0.25000000000 -j KUBE-SEP-BBBBBB
-A KUBE-SVC-XXXXX -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-CCCCCC
-A KUBE-SVC-XXXXX -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-DDDDDD
-A KUBE-SVC-XXXXX -j KUBE-SEP-EEEEEE
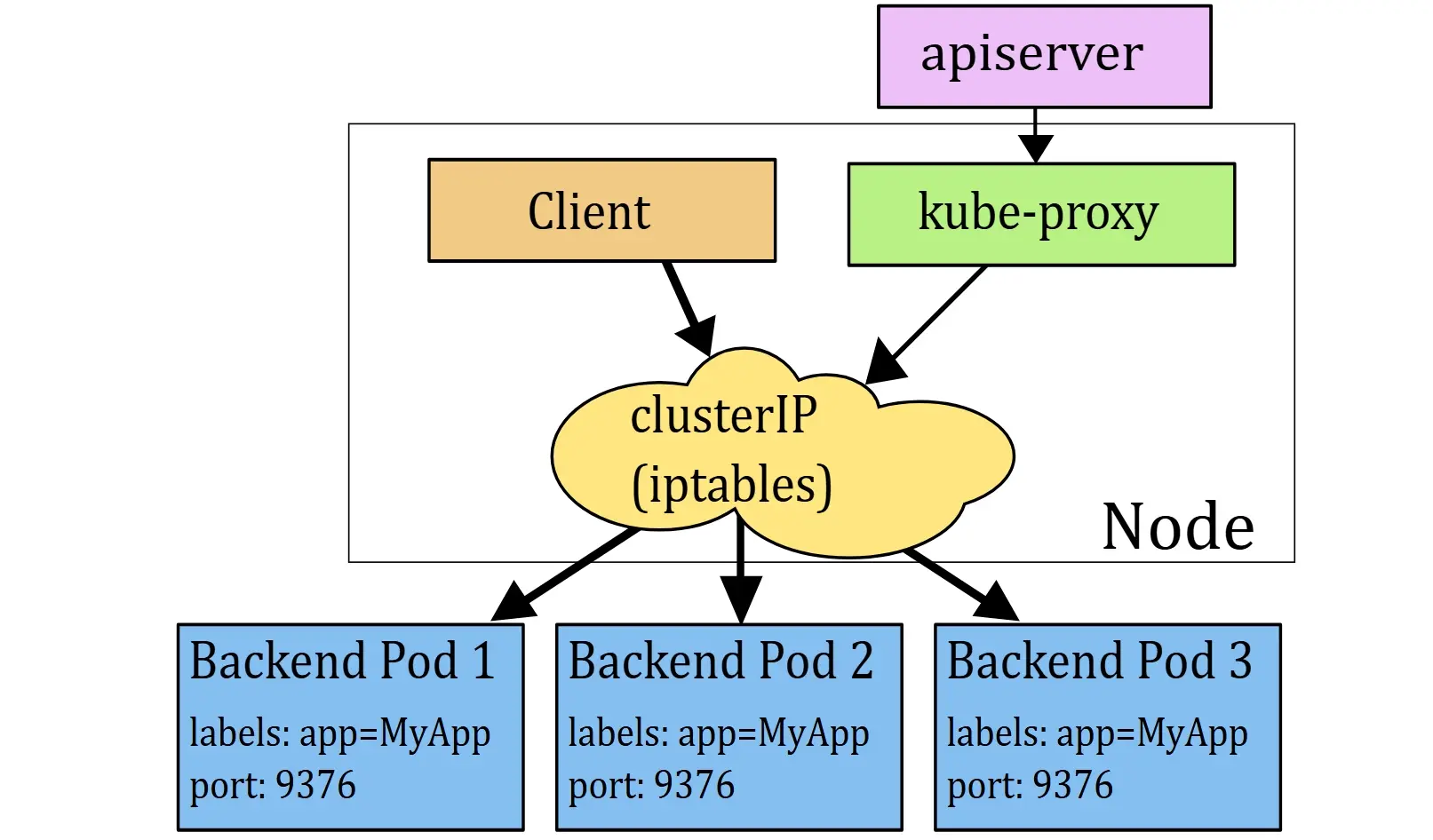
这代表 AWS Load Balancer 可能先把流量发送到某个节点,接着 Kubernetes 又在该节点上把 request 重新转发到某个 Pod。这个第二段 hop,常常就是排查问题时最容易被忽略的地方。
以下是很常见的 Service:
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
labels:
app: nginx
spec:
type: LoadBalancer
ports:
- port: 80
protocol: TCP
selector:
app: nginx
如果使用 instance targets,Load Balancer 注册的是节点。流量可能走这两种路径:
client -> Load Balancer -> Node-1 (NodePort) -> Pod-1 on Node-1
client -> Load Balancer -> Node-1 (NodePort) -> Pod-3 on Node-2
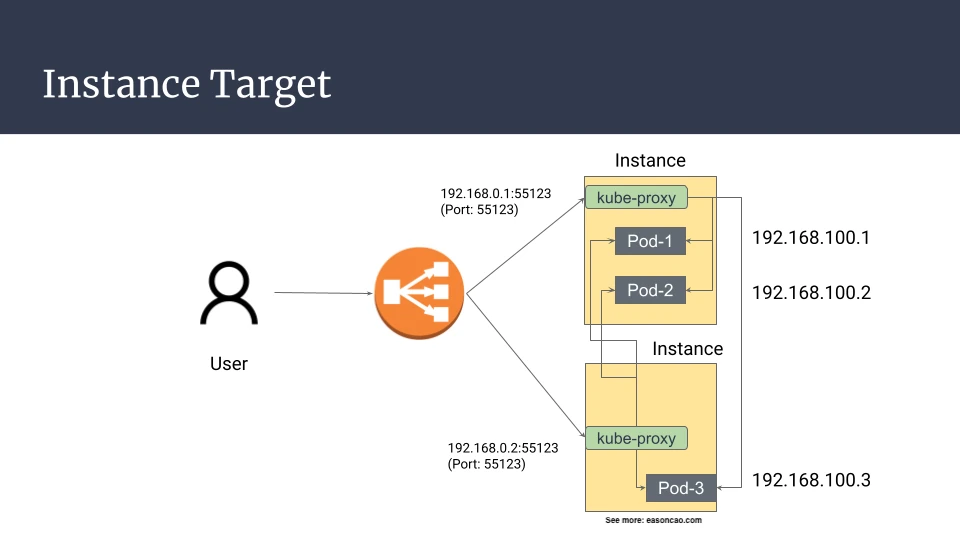
第二种路径可以工作,但它多了一段 node-to-node forwarding。如果 Node-1 在转发流量到 Pod-3 的过程中发生网络问题或被移除,即使 Pod-3 所在节点仍然健康,已建立的连接也可能中断。
externalTrafficPolicy: Local 可以避免跨节点转发,但会带来另一个取舍:没有本地 backend Pod 的节点,应该会在 Load Balancer health check 中失败,因为该节点没有本地 endpoint 可以服务 request。
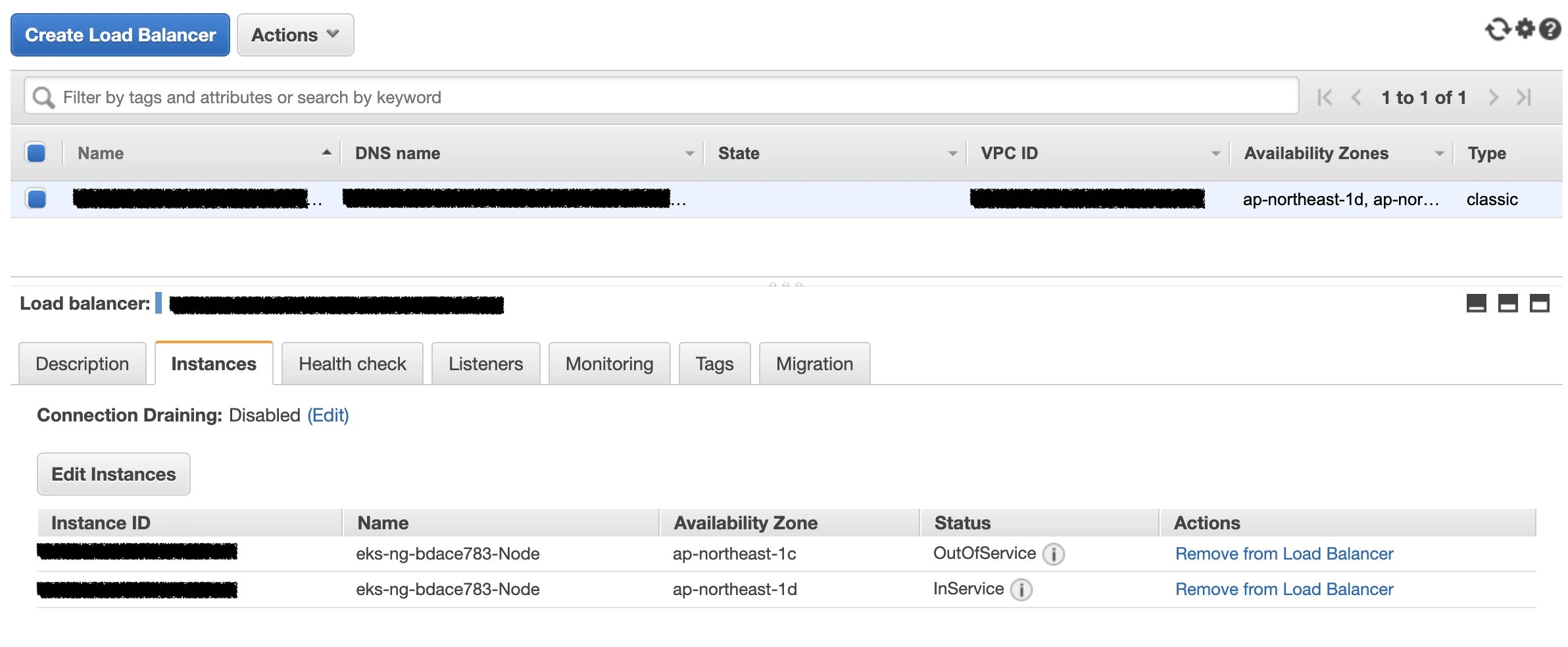
这是预期行为。真正的问题是流量分配会高度依赖 Pod 被调度到哪里。如果只有一台节点有本地 Pods,健康流量就会集中到那台节点。
为什么流量会不均
流量不均通常发生在这种场景:AWS Load Balancer 对注册的节点分配得很平均,但节点背后的 Pods 并没有平均收到流量。
在一个测试中,我让四个 backend Pods 返回自己的 Pod IP,方便统计每次 request 是由哪个 Pod 响应:
$ kubectl get pod -o wide
NAME READY STATUS IP
nginx-deployment-594764c789-5s668 1/1 Running 192.168.42.171
nginx-deployment-594764c789-9k949 1/1 Running 192.168.39.194
nginx-deployment-594764c789-b292m 1/1 Running 192.168.29.24
nginx-deployment-594764c789-s226c 1/1 Running 192.168.15.158
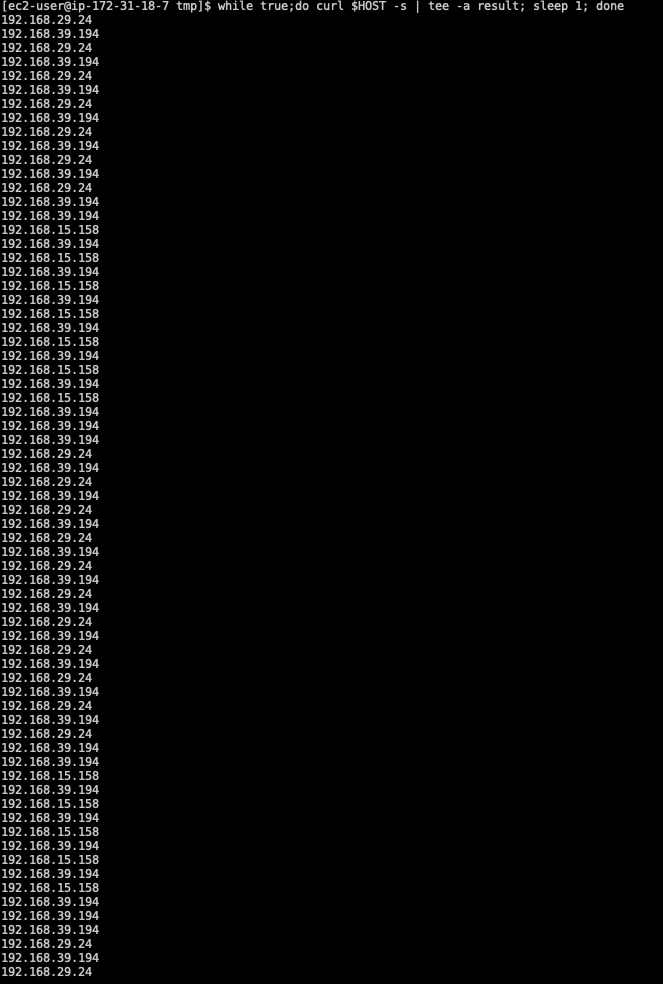
发送 79 次 HTTP requests 后,结果并不均匀:
192.168.42.171:12 次192.168.39.194:33 次192.168.29.24:23 次192.168.15.158:10 次
这不代表 Elastic Load Balancing 出了问题。它代表 Load Balancer 正在把流量分配到它注册的 targets,而 targets 后面又有 Kubernetes Service networking 再做一次 routing。当某个节点收到 request 后,最后会选到哪个 Pod,是 Kubernetes Service networking 决定的,不是 AWS Load Balancer 决定的。
规模越大,这个问题越难处理。更多 Services 和 endpoints 代表更多节点层级的 forwarding state、更多 conntrack 压力,以及更难在事故中厘清的数据包路径。
使用 IP Targets 直接把流量发送到 Pods
在使用 Amazon VPC CNI plugin 的 Amazon EKS 中,运行在 EC2 nodes 上的 Pods 会取得 VPC 可路由的 secondary private IP。这让 ALB 或 NLB target group 可以直接注册 Pod IP。
这个选项适用于 Application Load Balancer 与 Network Load Balancer 的 target groups。Classic Load Balancer 不支持 IP targets。Instance targets 在某些 node-level 设计中仍然合理,但当应用程序 workload 是由 Kubernetes Pods 承载时,IP targets 通常更符合 EKS 的网络模型。
更简洁的路径会变成:
client -> NLB or ALB -> Pod IP
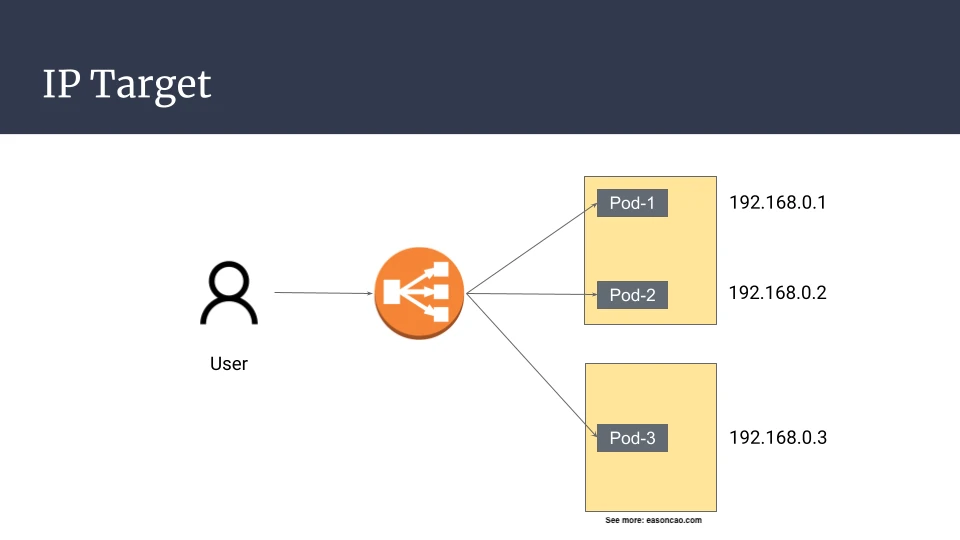
如果用 AWS Load Balancer Controller 管理 Network Load Balancer,可以使用像这样的 Service:
apiVersion: v1
kind: Service
metadata:
name: my-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "ip"
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
protocol: TCP
selector:
app: my-app
如果是 Application Load Balancer,则可在 Ingress 上使用 IP target mode:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: game-2048
name: ingress-2048
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
使用 IP targets 时,Load Balancer 会直接把流量转发到 Pod IP。在同样类型的测试中,四个 NLB 后方的 Pods 收到的流量更平均:
192.168.17.15:10 次192.168.27.143:12 次192.168.22.126:14 次192.168.14.48:13 次
这也是我在大多数 EKS workload 上,偏好使用 IP target mode 的主要原因。
IP Targets 仍可能看起来不均的情况
IP target mode 移除了 Kubernetes Service 额外转发那一层,但不代表所有情况下 request count 都会完全一致。以下情况仍可能让流量看起来不均:
- client 缓存了过期的 Load Balancer DNS 结果;
- 启用了 sticky sessions 或 source-IP affinity;
- targets 没有平均分布在 Availability Zones;
- workload 主要是长连接 TCP;
- WebSocket 连接长时间保持开启;
- clients 重复使用少数几条 persistent HTTP connections。
解法要看 workload。对短连接、stateless HTTP 流量来说,IP targets 加上均衡的 Pod placement 通常就能解决实践中的问题。对长连接服务来说,应该观察 active connections 和 target utilization,而不只是 request count。
Amazon EKS 上的 Controller 选项
Kubernetes In-Tree Load Balancer Controller
早期在 AWS 上创建一个单纯的 type: LoadBalancer Service,通常会由 Kubernetes in-tree AWS cloud provider code 处理。它很适合快速实验,但功能跟 Kubernetes release cycle 绑定,也较难快速支持新的 AWS Load Balancer 功能。
对现代 EKS cluster 来说,如果需要 AWS Load Balancer 集成,优先考虑 AWS Load Balancer Controller 或 EKS Auto Mode。除非有明确兼容性需求,否则旧的 in-tree 路径应视为 legacy。
NGINX Ingress Controller
当你需要 NGINX 在 request path 中提供能力时,NGINX Ingress Controller 很有价值,例如高级 rewrite、controller-level 设置、自定义 routing,或是让多个 Ingress objects 共用一层 NGINX。
在 AWS 上,常见做法是通过 LoadBalancer Service 暴露 NGINX,通常背后会创建 NLB:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: tcp
service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: "true"
service.beta.kubernetes.io/aws-load-balancer-type: external
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: instance
name: ingress-nginx-controller
namespace: ingress-nginx
spec:
externalTrafficPolicy: Local
type: LoadBalancer
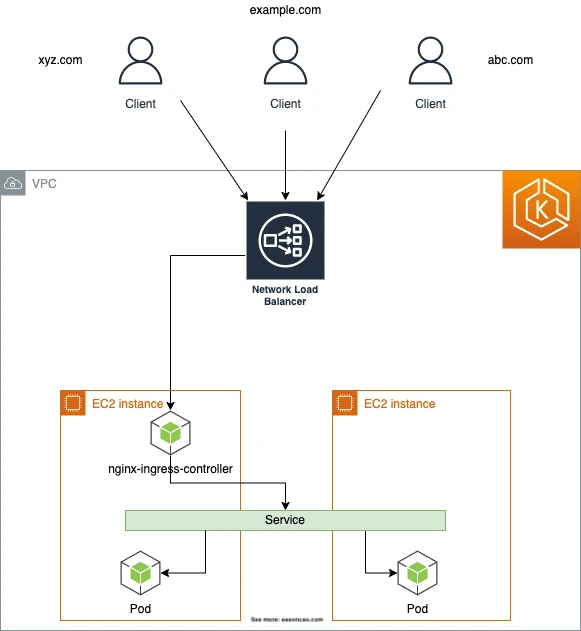
这是合理架构,但要清楚它做了什么:AWS Load Balancer 先把流量发送到 NGINX,NGINX 再把流量 route 到 Services 和 Pods。当你需要 NGINX 行为时,这层很有用;如果 ALB 或 NLB 已经能满足 routing 需求,这层就不一定必要。
当你想要一个集中式 routing layer 服务多个 namespaces、需要 NGINX 特有的 request handling,或希望多个 Ingress objects 共用同一个 NLB-backed entry point 时,NGINX Ingress 仍然很适合。重点是要把这层 proxy 视为有意设计,而不是无意识的默认选项。
AWS Load Balancer Controller
AWS Load Balancer Controller 会通过 AWS APIs,从 Kubernetes objects 管理 ALB、NLB、target groups、listeners、rules 等资源。它从过去的 ALB Ingress Controller 演进而来,目前同时支持 ALB 和 NLB 使用场景。
不同于 NGINX Ingress,AWS Load Balancer Controller 本身不是 data path 上的 gateway。它会根据 Kubernetes objects 去 reconcile AWS resources,之后由 Load Balancer 将流量发送到已注册的 targets。搭配 IP target mode 时,这些 targets 可以直接是 Pods。
当你想同时保留 Kubernetes manifests 的操作方式,又想使用 AWS 原生 Load Balancer 功能时,这通常是最好的默认选项:
- ALB:适合 HTTP/HTTPS routing、host/path rules、TLS termination 与 Web application traffic。
- NLB:适合 TCP/UDP、固定 IP 需求、高吞吐量,或需要保留 source IP 的场景。
- IP target mode:适合让 Load Balancer 直接打到 Pods。
- TargetGroupBinding:适合把 Kubernetes workloads 接到已有 target groups。
- IngressGroup:适合让多个 Ingress resources 共用同一个 ALB。
EKS Auto Mode
EKS Auto Mode 可以自动为 LoadBalancer Service 创建与配置 NLB,降低安装与运维 controller 的工作量。若你的 cluster 使用 Auto Mode,请先确认支持的 annotations 与行为,再直接沿用旧版 AWS Load Balancer Controller 示例。
整体设计原则仍然一样:明确决定流量应该打到 nodes 还是 Pod IPs。
实践建议
可行时,优先让应用程序 Pods 使用 IP targets。在 EKS 搭配 VPC CNI 时,Pod IP 在 VPC 内可路由,因此 ALB 与 NLB 通常可以直接把流量发送到 Pods,移除节点层级 Service forwarding 的额外 hop。
只有在你明确需要 node-level targeting 时,才使用 instance targets。这可能适合基础设施组件、DaemonSet 类型流量,或无法直接使用 Pod targets 的场景。
当你需要 NGINX 出现在 data path 中时,才使用 NGINX Ingress。不要只是因为“Kubernetes 应该要有 Ingress controller”就加一层 NGINX。在 AWS 上,通过 AWS Load Balancer Controller 使用 ALB Ingress,常常就能在不多跑一层 reverse proxy 的情况下完成 HTTP routing。
除非应用程序需要,否则避免 sticky sessions。Stickiness 有其用途,但它会直接影响流量平均分配。对 ALB 和 NLB 来说,先检查 target group attributes,再判断是否是 Kubernetes 或 ELB 算法问题。
让 Pods 分布在 Availability Zones。可以使用 topology spread constraints、Pod anti-affinity 或调度规则,确保每个启用的 Load Balancer zone 都有健康 backend capacity。
Health check 要刻意设计。externalTrafficPolicy: Local、instance targets 和 node-local endpoints 可能让部分节点 health check 失败,这不一定是故障,但必须符合你的可用性模型。
结论
EKS Load Balancing 最常见的误解,是以为流量只经过一个 Load Balancer。实际上,许多 clusters 会先由 AWS 做一次 load balancing,接着又由 Kubernetes 在节点上做一次 routing。第二层 routing 有它的用途,但也会增加 hop、隐藏最后的 Pod selection,并让流量分配看起来更难理解。
对大多数 AWS-native EKS workloads 来说,更简洁的设计是使用 AWS Load Balancer Controller 或 EKS Auto Mode,搭配 IP targets、均衡的 Pod placement,以及避免不必要的 stickiness。只有在 NGINX Ingress 或 instance targets 的行为正是你需要的设计时,才把它们放进路径中。
参考资料
