使用 EKS Cluster Health 資訊監控你的叢集健康狀態
作為 AWS 用戶,監控 Elastic Kubernetes Service (EKS) 叢集的健康狀態對於確保其穩定性和性能至關重要。在過去,通常需要在 EKS 叢集遇到問題(例如,無法升級叢集)時才會發現 EKS 叢集出現了一些非預期的錯誤,並沒有一種很好的方式或是監控能夠直接了解可能破壞 EKS 叢集的因素。但最近,Amazon EKS 在 EKS 控制台和 API 中引入了一個小變更,提供了對叢集健康狀態的增強可見性,讓 EKS 用戶可以更好地了解其叢集的健康狀態。
這個更新是什麼?
在 2023 年 12 月 28 日,Amazon EKS 宣布支援叢集健康狀態詳細資訊1。
這項健康狀態資訊有助於 EKS 用戶快速診斷、排除和解決叢集問題。因為底層基礎設施或配置問題可能導致 EKS 叢集受損,並阻止 EKS 應用更新或升級到較新的 Kubernetes 版本(例如:意外刪除 EKS 叢集關聯的 Subnet 或是 Security Group)。一般來說,EKS 用戶負責配置叢集基礎設施,例如 IAM Role 和 VPC 以及 Subnet 等。這項更新減少了 EKS 用戶需要花費大量時間和精力在進行基礎設施問題上除錯的時間,使運行穩健的 Kubernetes 環境變得更加容易。
在本篇內容,我們將討論這個新功能以及如何利用這項健康狀態資訊有效監控您的 EKS 叢集。
監控您的 EKS 叢集的健康狀態
為什麼要監控 EKS 叢集健康狀態
監控 EKS 叢集健康狀態能幫助您隨時了解叢集的整體健康狀態。若通過接收即時通知,可以快速識別任何問題或潛在問題,並立即響應且採取行動解決。這種主動的方法有助於防止任何 EKS 運行環境中非預期的錯誤,確保 EKS 叢集的順利運行。
DescribeCluster API 呼叫
監控 EKS 叢集健康狀態的第一種方法是利用 DescribeCluster API。這個 API 呼叫返回的內容中新增了一個新的欄位,用於了解有關叢集的詳細健康資訊,包括其當前狀態、幾種不同的錯誤碼2和任何發現的問題,幫助 EKS 用戶了解有關叢集的健康狀態和性能的洞察。以下是使用 AWS CLI 命令輸出的一個範例:
$ aws eks describe-cluster --name eks --region eu-west-1
{
"cluster": {
"name": "eks",
"arn": "arn:aws:eks:eu-west-1:11222334455:cluster/eks",
"createdAt": "2024-01-23T20:51:44.751000+00:00",
"version": "1.27",
}
"health": {
"issues": []
}
}
}
程式設計開發者可以透過這項 API 變更設計屬於自己的監控邏輯,並且使用程式化的邏輯完成特定的自動化工作。
EKS 控制台
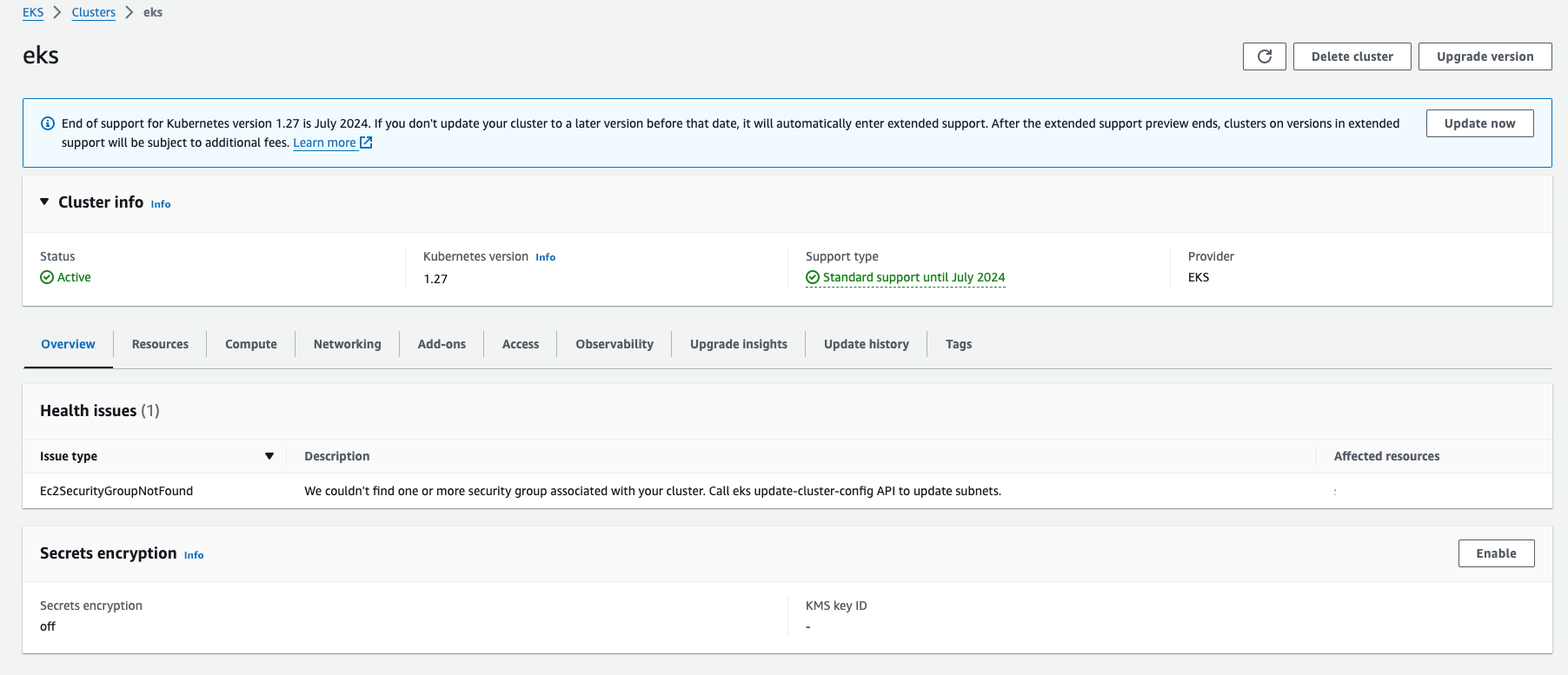
除了上述的 API 操作,也可以通過 EKS Console 介面監控 EKS 叢集的健康狀態。在 EKS 控制台中,新增加了一個新的區塊會顯示整體叢集的健康狀態,並且獲取有關叢集健康狀態的即時資訊。
整合 Slack 通知進行監控
目前,EKS 這項更新並未支援主動通知或 CloudWatch 事件,這意味著如果需要透過可程式化邏輯了解目前的健康狀態,您需要手動調用 API。如果要要設定 EKS 叢集健康狀態的監控並接收通知,除了自己寫程式邏輯並且定時運行,也可以考慮使用 EventBridge 服務進行整合。EventBridge 是由 AWS 提供的一項服務,可讓您在不同的 AWS 服務和外部應用程序之間進行事件的觸發操作,甚至設置定時事件來觸發操作 (類似 cron job)。在現階段,一種簡單的做法是可以通過設定 EventBridge Scheduler 來觸發 AWS Lambda (Lambda function),在 Lambda function 可以執行自行撰寫的程式邏輯,可以透過這項服務進行 DescribeCluster API 呼叫,並且整合其他應用,便於在叢集健康狀態有變更或更新時收到即時通知。
下面是我實施的簡單解決方案:
解決方案概述
- 建立一個 Lambda 函數(MoninitorEKSClusterHealth)並且在程式中使用
DescribeClusterAPI 呼叫檢查 EKS 叢集是否有健康問題狀態 - 關聯 Slack 頻道與 AWS ChatBot,並且在與 AWS ChatBot 整合的過程中會一同建立一個 SNS Topic 用於發送任何通知
- 使用 EventBridge Scheduler 設置定時觸發條件,定期呼叫 Lambda 函數(MoninitorEKSClusterHealth)。如果叢集有健康問題,它會在執行期間拋出錯誤。
- 建立 CloudWatch alarm 以監控 Lambda 函數(MoninitorEKSClusterHealth)的錯誤,並在有錯誤事件時,觸發指定的 SNS Topic (這會直接進行即時的 Slack 通知)
建立 Lambda 函數
第一步是建立一個 Lambda 函數 (在這裡稱為 MoninitorEKSClusterHealth),這個小程式可以幫助我們了解 EKS 叢集的健康狀態並捕獲任何錯誤,以下是我使用 Python 的一個簡單範例:
import json
import boto3
def describe_eks_cluster(cluster_name):
eks_client = boto3.client('eks')
response = eks_client.describe_cluster(name=cluster_name)
health_issues = response['cluster']['health']['issues']
if len(health_issues) > 0:
raise Exception("Cluster has health issues: {0}".format(health_issues))
return response
def lambda_handler(event, context):
cluster_name = event['eks-cluster-name']
cluster_info = ''
cluster_info = describe_eks_cluster(cluster_name)
print(cluster_info)
return {
'statusCode': 200,
'body': 'success'
}
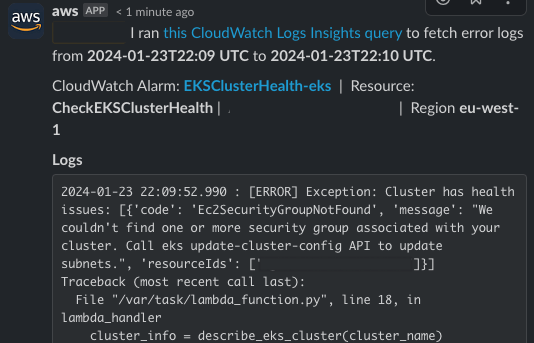
使用 DescribeCluster API 當叢集有健康問題時,API 回應會在健康問題的欄位中返回詳細資訊。例如,在一個關聯 Security Group 被意外刪除的 EKS 叢集中存在健康問題狀態,以下是從我的 MoninitorEKSClusterHealth 函數的紀錄檔中捕獲的錯誤訊息。它表明事件中存在一個與叢集健康問題相關的異常。具體的錯誤是 Ec2SecurityGroupNotFound:
[ERROR] Exception: Cluster has health issues:
['code': 'Ec2SecurityGroupNotFound',
'message': "We couldn't find one or more security group associated with your cluster. Call eks update-cluster-config API to update subnets.",
'resourceIds': ['sg-XXXXXXX']
Traceback (most recent call last):
File "/var/task/Lambda_function.py", line 18, in lambda_handler
cluster_info = describe_eks_cluster(cluster_name)
File "/var/task/lambda_function.py", line 10, in describe_eks_cluster raise Exception("Cluster has health issues: {01" format(health_issues))
在 Python 程式中設計邏輯中,當發現有 EKS 叢集健康問題拋出例外錯誤是關鍵,因為這種錯誤可以在 AWS Lambda 提供的 CloudWatch metric 生成錯誤,並且方便我們在後續能直接透過建立 AWS Lambda 的 CloudWatch alarm 來監控狀態。
在 AWS EventBridge Scheduler 中建立定期排程觸發規則
監控 EKS 叢集健康狀態的下一步是在 AWS EventBridge Scheduler 中建立一個新的規則以定期觸發執行我們在 AWS Lambda 上部署的應用程式。我同時也指定了在 AWS Lambda 函數中定義的 eks-cluster-name 參數,指定要監控的 EKS 叢集名稱,以便在觸發我在 AWS Lambda 上部署的應用程式時知道我要檢查哪個 EKS 叢集。
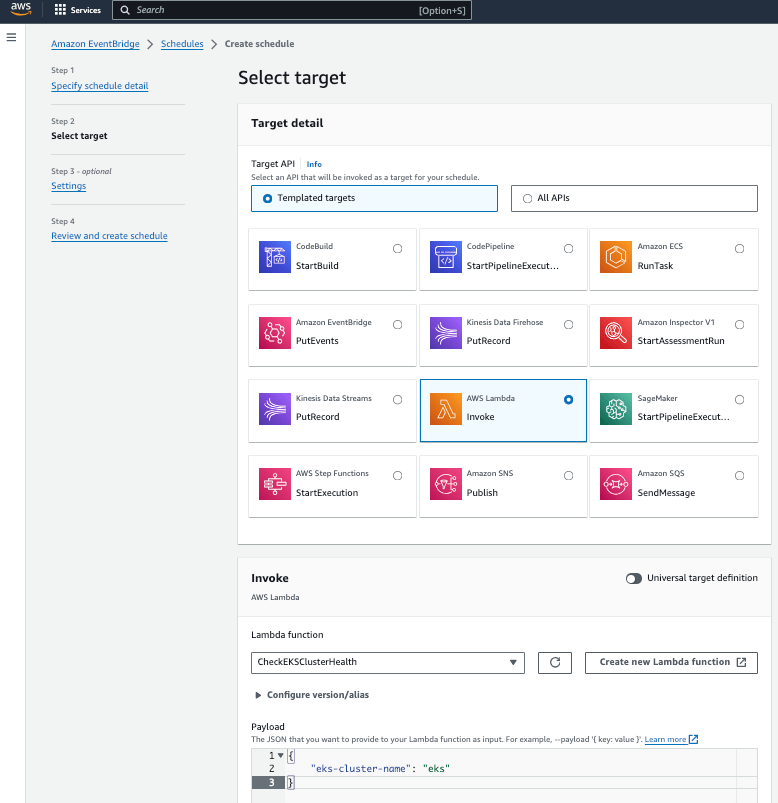
此外,在我的環境中,為了避免短時間同時產生大量的 API 請求呼叫,我以 60 分鐘為觸發條件 (視情況甚至可以考慮 24 小時或是更長),大部分情況下並不會短時間內大量變更 AWS 資源的網路拓撲、資源組態和設定 (例如通常可能只發生在每日的尖峰工作時段、例行的部署變更維護窗口或特定時間的部署行為),短時間進行這項健康問題檢查並不是一個很理想的設計,這可能會產生大量不必要的運算資源和 Lambda 運行費用。
設置 CloudWatch Alarm 警報
一旦設定好一個定期觸發規則和可以回傳 EKS 健康狀態的應用程式來報告叢集健康狀況,我們可以設置一個 CloudWatch Alarm 警報,並且僅監控這個 Lambda 函式 (MoninitorEKSClusterHealth) 以捕捉任何錯誤。在我的環境中,我設定了一個 CloudWatch Alarm,並且監控 Lambda 函式 (MoninitorEKSClusterHealth) 下的 Erros 指標(該指標屬於 AWS/Lambda 命名空間):
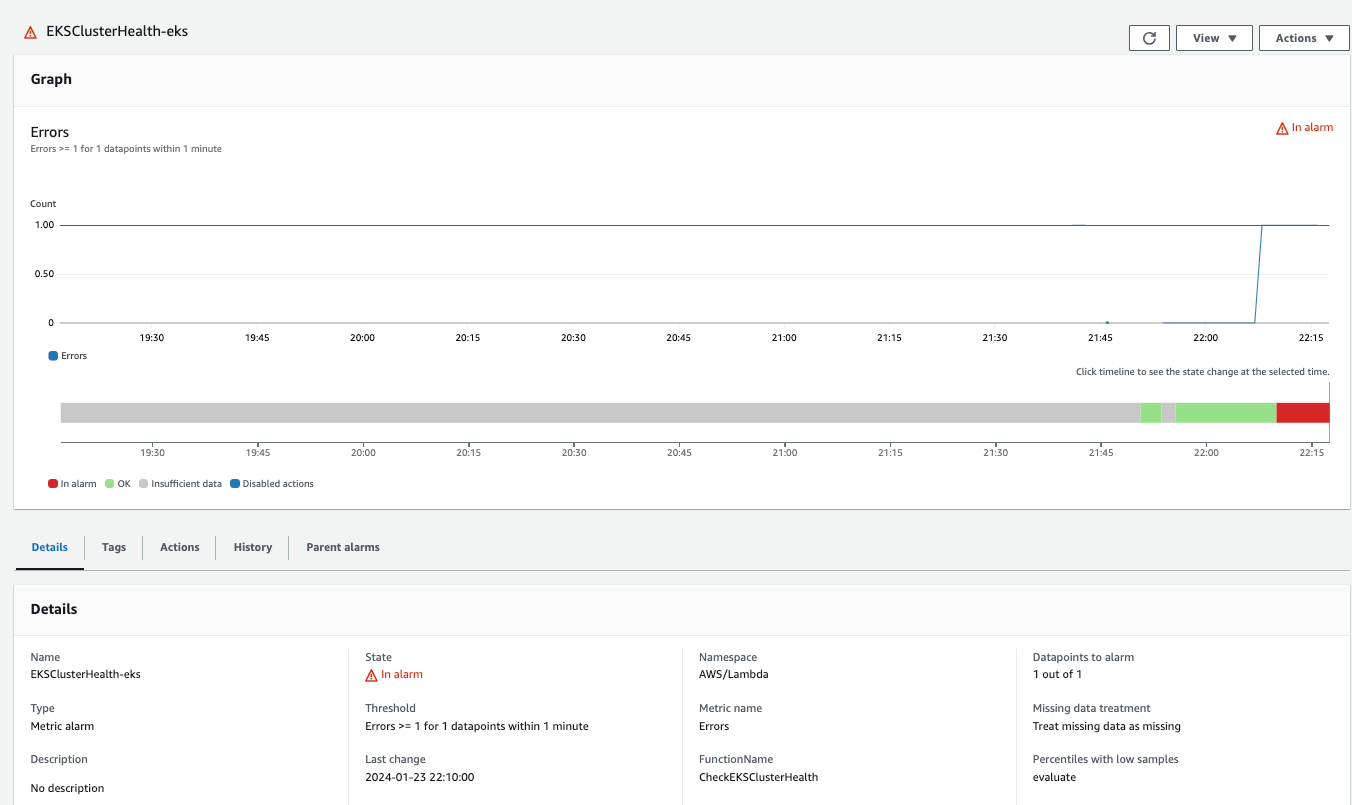
並且在發生警報時觸發動作是將訊息通知傳遞至先前 AWS ChatBot 整合的過程中一同建立的一個 SNS Topic。
如果 EKS 叢集有任何健康問題,Lambda 函式在執行時將拋出錯誤,並且 CloudWatch Alarm 警報將會翻轉為 In alarm 狀態,透過 CloudWatch Alarm 警報,將會將通知傳送至我們指定的 SNS Topic,實時透過 AWS ChatBot 觸發 Slack 通知。在我的帳號中,我已經預先設定了 AWS ChatBot (Slack chatbot) 並訂閱了一個 SNS Topic3。幫助我可以在 EKS 叢集發生健康問題時,獲得更新並立即採取行動來解決 EKS 叢集的任何問題。
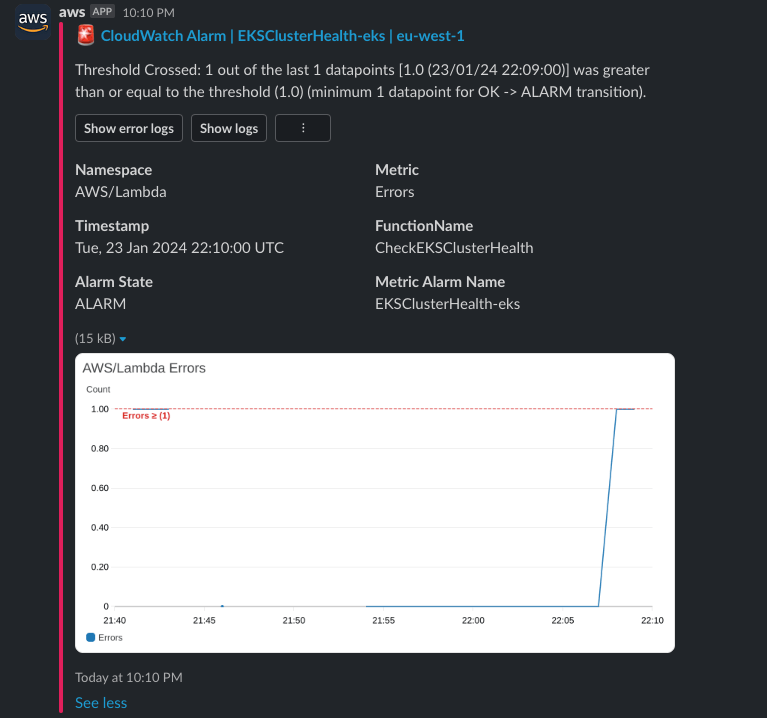
AWS Chatbot 還提供查看 Lambda 函式的錯誤日誌的功能,在我們的應用程式中會直接顯示 DescribeCluster API 的詳細資訊,這對於能在數分鐘內透過 Slack 的聊天視窗能直接瞭解為什麼 EKS 叢集出現健康問題非常有用:
總結
總結此篇內容,監控您的 EKS 叢集的健康狀態對於維護其穩定性、性能和安全性至關重要。通過這項功能性的更新,利用 DescribeCluster API 呼叫或檢視 EKS 控制台上的資訊,可以隨時瞭解 EKS 叢集過去難以察覺的設定問題或是其他非預期錯誤,能夠更容易發現並且採取行動解決。
此外,這篇內容不但介紹了如何使用 DescribeCluster API 呼叫的相關細節,並且也分享了如何透過整合不同 AWS 服務,包含 EventBridge、AWS Lambda 和 CloudWatch 等,在叢集健康狀態發生變化時,能夠獲得實時的 Slack 訊息通知,節省除錯時間並且簡化維運 EKS 工作。
參考資料
