管理 Kubernetes Webhook 故障:从诊断到解决方案
在现代云原生架构中,Kubernetes Admission Webhook 扮演着至关重要的角色,允许我们扩展和自定义 Kubernetes 的行为,而无需修改核心代码。然而,这种强大的功能也带来了潜在的风险 — 当 webhook 发生故障时,可能会对整个集群造成严重影响,甚至导致系统性的服务中断。
作为一名在容器技术领域的实践者,我曾协助处理过多起因 webhook 故障导致的生产环境事件。这些经验让我深刻认识到,了解 webhook 的运作机制、掌握故障诊断技巧,以及实施适当的监控策略,对于维护 Kubernetes 集群的稳定性至关重要。因此,本篇内容将着重于分享从诊断到解决方案的全面指南,包含实际案例分析和预防措施。通过这些内容,希望能够帮助更多 Kubernetes 管理员在面对 webhook 相关问题时,能够迅速找到根本原因并采取适当的解决方案。
本篇内容同时也摘要总结分享至 Kubernetes Community Day (KCD) Taipei 2025 演讲 1。
Kubernetes Admission Webhook 概述
Kubernetes Admission Control 是 Kubernetes 中的一种机制,允许在资源被存储到 etcd 之前拦截和修改 API 请求。而 Kubernetes Admission Webhook 则属于动态扩展机制的一部分,允许开发者自定义和扩展 Kubernetes 的控制逻辑。这种机制通过 HTTP 回调的方式,使外部服务能够参与到资源管理决策中,在资源被持久化到 etcd 之前进行验证或修改。
Kubernetes 提供了许多原生内建的 Admission 插件,可以通过 Kubernetes API Server 的 --enable-admission-plugins 参数启用,例如:
kube-apiserver --enable-admission-plugins=NamespaceLifecycle,LimitRanger...
例如,在本文撰写时,最新版本为 Kubernetes 1.33,预设启用了以下 Admission 插件:
CertificateApprovalCertificateSigningCertificateSubjectRestrictionDefaultIngressClassDefaultStorageClassDefaultTolerationSecondsLimitRangerMutatingAdmissionWebhookNamespaceLifecyclePersistentVolumeClaimResizePodSecurityPriorityResourceQuotaRuntimeClassServiceAccountStorageObjectInUseProtectionTaintNodesByConditionValidatingAdmissionPolicyValidatingAdmissionWebhook
为了扩增 Kubernetes 的功能性,额外的 MutatingAdmissionWebhook 以及 ValidatingAdmissionWebhook 为 Kubernetes 动态扩展 Kubernetes API 的关键机制。它们能够在资源被 Kubernetes API Server 处理的过程中拦截请求,执行额外的逻辑,例如验证资源规格是否符合组织政策,或者自动修改资源配置以符合特定需求。
在实际应用中,Admission Webhook 被广泛用于多个场景:
- 镜像安全扫描:确保只有经过安全扫描的容器镜像才能部署到集群
- 命名空间管理:自动为资源添加特定的标签或注释
- Sidecar 注入:自动注入监控和日志收集的 sidecar 容器
许多开源项目依赖 webhook 来提供功能,如 Istio(用于 sidecar 注入)、Cert-manager(自动化证书管理)、Kyverno 和 Gatekeeper(策略控制)等。
假设你需要根据 Pod 的标签来自动加上对应的注释。比如说,当一个 Pod 带有标签 app=nginx 时,你需要自动加上一个叫做 foo 的注释,其值为 stack。但如果 app 标签的值是 mongo,则注释的值应该是不同的。这本质上需要一个查找表来将 X 值映射到 Y 值,这通常不太容易实现。而使用 Kyverno,不仅可以取代这些客制化的注释工具,还可以利用原生的 Kubernetes 资源如 ConfigMap 来定义这个对照表,并动态套用相对应的值。这里的动态操作,便涉及了 Kubernetes Admission Webhook 的运作机制。以下是一个 Kyverno 规则示例,它可以根据 Pod 的标签动态地添加注释:
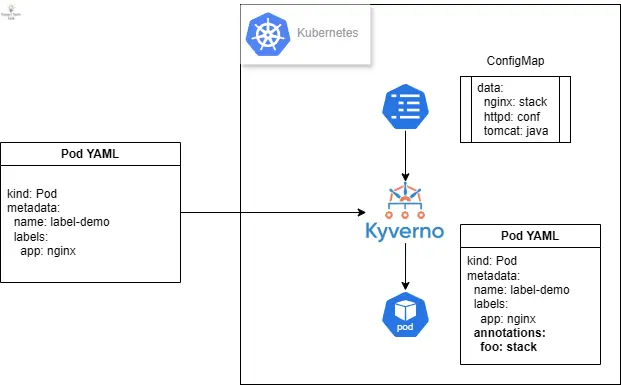
首先,我们需要一个作为参考表的 ConfigMap。这就是一个标准的 ConfigMap,其中每个键 (Key) 都有对应的值 (Value),形成标签和注释之间的映射关系。
apiVersion: v1
kind: ConfigMap
metadata:
name: resource-annotater-reference
namespace: default
data:
httpd: conf
nginx: stack
tomcat: java
接下来,我们需要一个包含变更逻辑的策略。以下是一个范例,它做了几件事。首先,它使用了 Kyverno 中称为 context 的概念来提供对现有 ConfigMap 的引用。其次,它使用 JMESPath 表达式 来执行参考并插入名为 foo 的注释值。
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: resource-annotater
spec:
background: false
rules:
- name: add-resource-annotations
context:
- name: LabelsCM
configMap:
name: resource-annotater-reference
namespace: default
preconditions:
- key: "{{request.object.metadata.labels.app}}"
operator: NotEquals
value: ""
- key: "{{request.operation}}"
operator: Equals
value: "CREATE"
match:
resources:
kinds:
- Pod
mutate:
overlay:
metadata:
annotations:
foo: "{{LabelsCM.data.{{ request.object.metadata.labels.app }}}}"
最后,让我们用一个简单的 Pod 定义来测试。在这个定义中,输入是一个名为 app 的标签,其值为 nginx。
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: mypod
spec:
automountServiceAccountToken: false
containers:
- name: busybox
image: busybox:1.28
args:
- "sleep"
- "9999"
建立这资源后,检查 Pod 注释就会看到 Kyverno 根据传入的 app 标签值,写入了从 ConfigMap 中找到的对应值。
$ kubectl get po mypod -o jsonpath='{.metadata.annotations}' | jq
{
"foo": "stack",
"policies.kyverno.io/patches": "add-resource-annotations.resource-annotater.kyverno.io: removed /metadata/creationTimestamp\n"
}
Kubernetes Admission Webhook 工作流程
在了解基础的 Kubernetes Admission Webhook 概念后,让我们来看看 Webhook 的工作流程。在典型的 API 请求处理过程中,当用户或系统组件向 Kubernetes API Server 发送请求时,该请求会经过一系列的处理步骤。首先,请求会通过认证(Authentication)和授权(Authorization)检查,确保请求者有权执行该操作。接着,请求会进入准入控制(Admission Control)阶段,其中包括 Mutating Webhook 和 Validating Webhook 的处理。
Admission Webhook 主要分为两种类型:
- 验证型 (Validating) Webhook:负责验证资源请求是否符合特定规则,可以接受或拒绝请求,但不能修改请求内容。
- 修改型 (Mutating) Webhook:除了可以验证请求外,还能修改请求内容,例如新增预设值或注入额外配置。
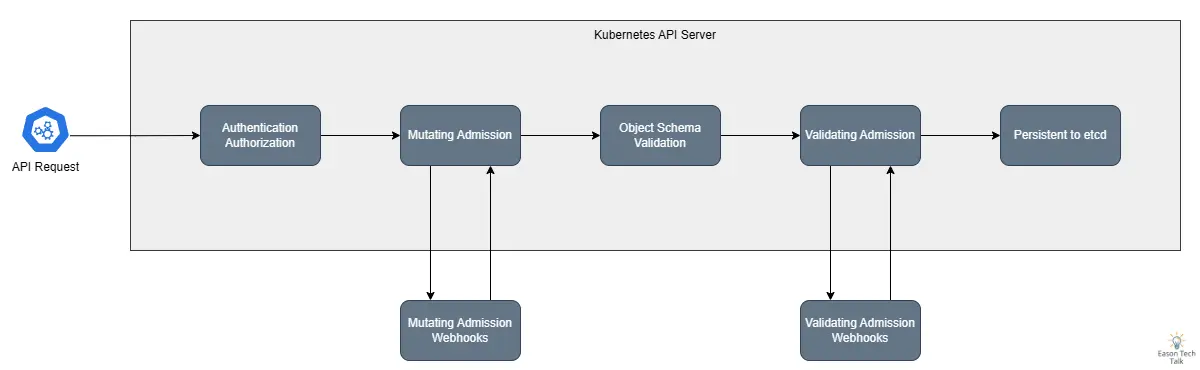
在 API 服务器的请求处理流程中,当一个请求到达时,首先会进行身份验证和授权检查,然后会依序经过所有已注册的 Mutating Webhook。这些 Webhook 可以对请求进行修改,例如新增标签、注释或是注入 Sidecar 容器。完成修改后,请求会进入 Validating Webhook 阶段,在这个阶段中,Webhook 只能验证请求是否符合特定规则,但不能进行任何修改。最后,如果所有的 Webhook 都通过,请求才会被永久保存到 etcd 中。
在这背后,API Server 将会主动调用并且触发对应的 Webhook 服务。例如,当用户尝试创建 Pod 资源时,API Server 将会请求 Webhook 服务进行验证或修改。Webhook 服务收到请求后,会根据预定的逻辑处理该请求,并返回结果给 API Server。API Server 根据 Webhook 的回应决定是否继续处理该请求,或者返回错误给用户。这种请求与回应的循环构成了 Webhook 的基本工作流程。
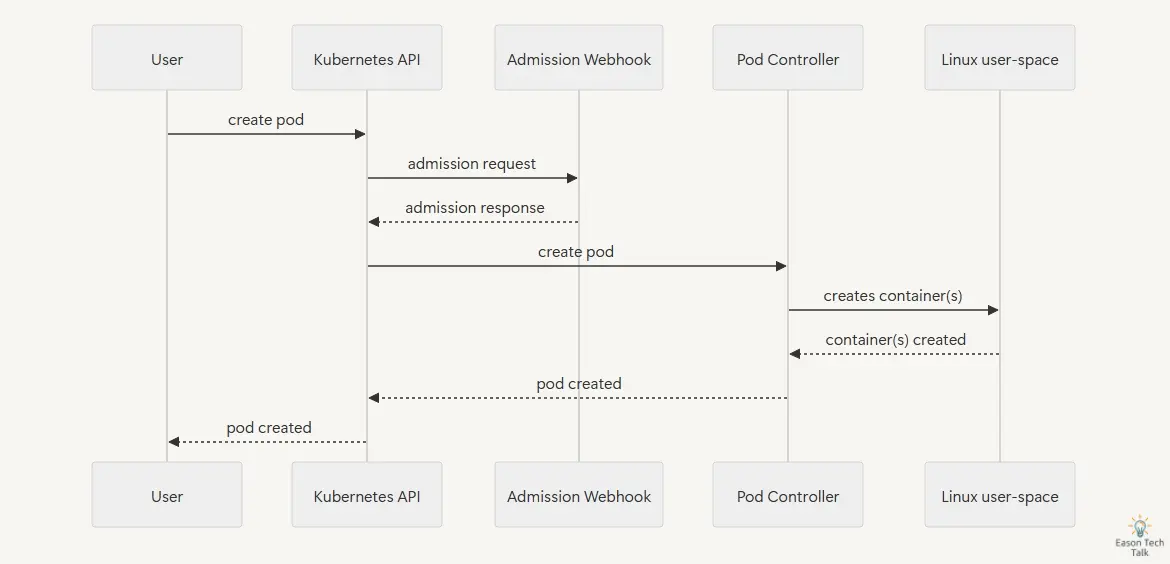
其中,作为 Webhook 服务的应用程序需要返回 AdmissionReview 类型的回应数据 (200 HTTP status code),数据结构为 Content-Type: application/json。这个回应告诉 API Server 该请求是被允许还是被拒绝,以及可能需要的修改内容。以下是两个典型的 AdmissionReview回应范例,分别代表接受和拒绝请求的情况。
接受请求的 webhook 回应示例:
{
"apiVersion": "admission.k8s.io/v1",
"kind": "AdmissionReview",
"response": {
"uid": "<value from request.uid>",
"allowed": true
}
}
拒绝请求的 webhook 最小回应示例 (Validating webhook):
{
"kind": "AdmissionReview",
"apiVersion": "admission.k8s.io/v1",
"response": {
"uid": "9e8992f7-5761-4a27-a7b0-501b0d61c7f6",
"allowed": false,
"status": {
"message": "pod name contains \"offensive\"",
"code": 403
}
}
}
那 Kubernetes API Server 是如何具体得知在执行特定 API 操作时,要触发哪个 Webhook 呢?这就轮到 MutatingWebhookConfiguration 和 ValidatingWebhookConfiguration 这两类资源定义来发挥作用了。这两类配置告诉 API Server 哪些 Webhook 服务应该在什么情况下被触发。这些配置资源包含了 Webhook 的 URL、验证选项、匹配规则以及错误处理策略等重要信息。
以下展示了一个基本的验证型 webhook (Validating webhook),它会:
- 监控所有 Pod 的建立操作
- 通过指定的服务发送请求到 webhook 服务 (webhook-service)
- 如果 webhook 服务失败,根据 failurePolicy 决定是否允许请求通过
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: pod-policy.example.com
webhooks:
- name: pod-policy.example.com
rules:
- apiGroups: [""]
apiVersions: ["v1"]
operations: ["CREATE"]
resources: ["pods"]
clientConfig:
service:
name: webhook-service
namespace: default
path: "/validate"
failurePolicy: Fail
自定义 Mutating webhook 的设定也十分类似,以下用 AWS Load Balancer Controller 实现自动注入 Pod readinessGates 的功能为例,其设定如下:
$ kubectl describe MutatingWebhookConfiguration/aws-load-balancer-webhook
Name: aws-load-balancer-webhook
Namespace:
Labels: app.kubernetes.io/instance=aws-load-balancer-controller
app.kubernetes.io/name=aws-load-balancer-controller
app.kubernetes.io/version=v2.7.2
API Version: admissionregistration.k8s.io/v1
Kind: MutatingWebhookConfiguration
Webhooks:
Admission Review Versions:
v1beta1
Client Config:
Service:
Name: aws-load-balancer-webhook-service
Namespace: kube-system
Path: /mutate-v1-pod
Port: 443
Failure Policy: Fail
Match Policy: Equivalent
Name: mpod.elbv2.k8s.aws
Namespace Selector:
Match Expressions:
Key: elbv2.k8s.aws/pod-readiness-gate-inject
Operator: In
Values:
enabled
Object Selector:
Match Expressions:
Key: app.kubernetes.io/name
Operator: NotIn
Values:
aws-load-balancer-controller
Rules:
API Versions:
v1
Operations:
CREATE
Resources:
pods
...
这个 AWS Load Balancer Controller 的 MutatingWebhookConfiguration 展示了几个关键设定项:
- Client Config:定义 API Server 与 webhook 服务的通信方式:
- 指向
kube-system命名空间中的aws-load-balancer-webhook-service - 使用
/mutate-v1-pod路径处理 Pod 变更 - 通过 443 端口进行安全通信
- 指向
- Failure Policy:设为
Fail,表示 webhook 无回应时 API Server 会拒绝请求。这是重要的安全措施,但可能在故障时阻碍资源创建。 - 命名空间选择器 (Namespace Selector):仅处理带有标签
elbv2.k8s.aws/pod-readiness-gate-inject: enabled的命名空间中的资源。这提供精细控制,让管理员可选择需要此功能的命名空间。 - 对象选择器 (Object Selector):排除标签为
app.kubernetes.io/name: aws-load-balancer-controller的资源,避免 webhook 处理 AWS Load Balancer Controller 本身,防止循环依赖问题。 - 规则定义 (Rules):指定仅处理 Pod 资源的建立 (
CREATE) 操作,进一步限制其作用范围。
这个设定明确界定了 webhook 的行为边界,确保它只在需要的地方生效(特定标签的命名空间中的新建 Pod)。
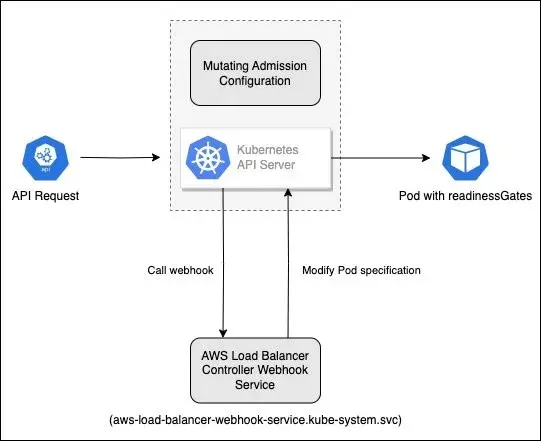
以下是具体 API 请求经由 API Server 触发和更改 Pod 规格的流程:
- 用户建立标记了
elbv2.k8s.aws/pod-readiness-gate-inject: enabled的命名空间 - 当在此命名空间中建立 Pod 时,API Server 会检查 MutatingWebhookConfiguration
- API Server 发现 Pod 建立操作符合 webhook 规则,发送请求到 AWS Load Balancer Controller webhook 服务 (借助 kube-dns 解析
aws-load-balancer-webhook-service.kube-system.svc对应的服务 Cluster IP 地址) - Webhook 服务收到请求后,检查 Pod 规格并注入所需的 readinessGates 配置
- API Server 接收修改后的 Pod 规格,将其保存到 etcd 中
从以上的讨论中,我们可以看到 Kubernetes Admission Webhook 的工作流程相当复杂,涉及到多个组件之间的通信和协作。当用户或系统发起一个请求创建资源时,该请求需要经过一系列的检查和处理才能最终被执行。这个过程中的任何环节出现问题,都可能导致整个工作流程受阻,进而影响集群的正常运作。
常见的 Webhook 故障模式
基于实际案例分析,我总结了几种常见的 webhook 故障模式:
1. 网络连接问题
网络连接问题是 webhook 最常见的故障之一。当集群内的网络通信出现问题时,可能导致 webhook 服务无法正常响应 API Server 的请求。例如,以下是一个典型的错误信息,表明 API Server 无法找到 webhook 服务:
error when patching "istio-gateway.yaml": Internal error occurred: failed calling webhook "validate.kyverno.svc-fail": failed to call webhook: Post "https://kyverno-svc.default.svc:443/validate/fail?timeout=10s": context deadline exceeded
这些问题可能源于 DNS 解析失败、网络延迟过高、CNI 错误,或是服务发现机制失效等情况。以 Amazon EKS 环境为例,以下是一个常见 Webhook 服务在云原生环境中的数据流,它揭示了 API Server 如何通过云端基础设施连接到 webhook 服务:
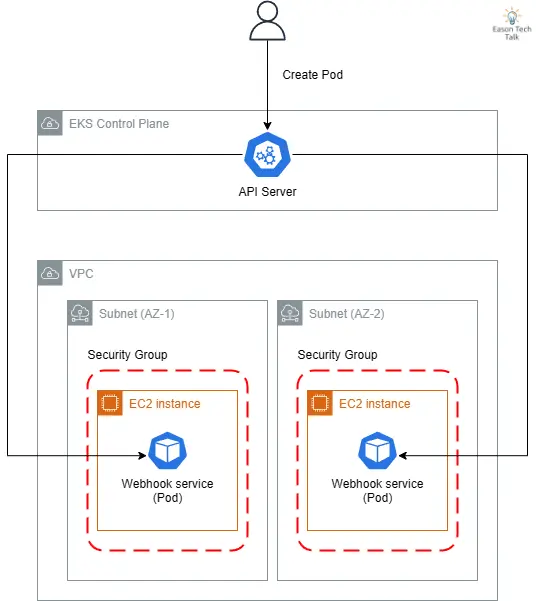
- API Server 位于 AWS 管理的 EKS Control Plane,而 webhook 服务则运行在客户 VPC 的 EC2 实例上
- 为实现高可用性,webhook 服务通常部署在不同可用区 (AZ-1, AZ-2) 的子网中
- 安全组限制了进出 webhook 服务的网络流量
此架构中可能出现的网络连接问题包括:子网路由错误、安全组规则限制、DNS 解析失败 (CoreDNS)、系统层网络问题 (例如 kube-proxy 无法正确工作设定 iptables 或 ipvs 规则影响到目标 Pod) 等,任何一环出现问题都可能导致 webhook 调用失败,进而影响整个集群的正常运作。在故障诊断时,这些网络路径都是需要检查的重点。
2. 证书过期和 TLS 问题
证书过期和 TLS 问题是另一个常见的故障点。当 webhook 的 TLS 证书过期或配置不当时,API Server 将无法与 webhook 服务建立安全连接。这种情况特别棘手,因为证书即将过期的问题往往不易被及时发现。
举例来说,在我协助客户案例的经验中,AWS Load Balancer Controller 过去的版本曾因常遇到证书过期,而导致新的 Ingress 资源无法创建。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedDeployModel 53m (x9 over 63m) ingress (combined from similar events): Failed deploy model due to Internal error occurred: failed calling webhook "mtargetgroupbinding.elbv2.k8s.aws": Post "https://aws-load-balancer-webhook-service.kube-system.svc:443/mutate-elbv2-k8s-aws-v1beta1-targetgroupbinding?timeout=30s": x509: certificate has expired or is not yet valid: current time 2022-03-03T07:37:16Z is after 2022-02-26T11:24:26Z
为了解决此问题,最新版本在使用 Helm 安装时,会通过内建的 genCA 方法自动产生有效期超过十年的自签证书。
若你的集群环境采用 Cert-manager 等套件来轮替 TLS 证书,则需要特别注意证书更新机制是否正常运作,并确保在证书到期前有充足的处理时间,实施自动化的证书轮替机制,以减少人为干预的需求。
3. 延迟和性能下降 (Control Plane)
控制平面层延迟和性能下降是另一个重要的故障来源。当 Kubernetes Master Node 服务响应时间过长,或者服务本身处理能力下降时,可能导致请求超时。这种情况通常发生在大规模负载过高,或者底层资源(如 CPU、内存)不足时,可能会导致请求堆积和超时。
以内建的 ResourceQuota 为例,作为内建 Kubernetes Admission Controller 的一部分,其工作流程与 Webhook 非常相似。当用户尝试建立或更新资源时,API Server 会调用 ResourceQuota Admission Controller 检查是否违反资源配额限制。这个过程中,API Server 需要计算资源的当前使用量并进行比较,对应的资源限制状态将会更新至 etcd。
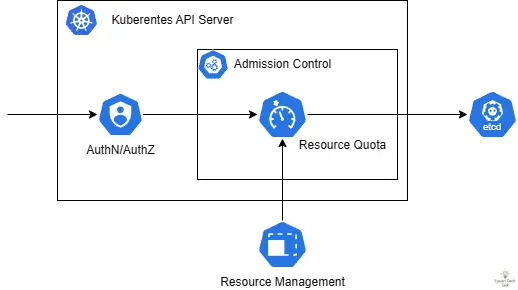
一个有趣的案例是 ResourceQuota 因为 Kubernetes Controller Manager 负载过高无法正确工作,常见于 Kubernetes 资源过多或是 CPU 处理速度过慢导致。由于 ResourceQuota 属于预设 Validating Admission Plugin 的一部分,当其监控逻辑出现问题时,可能会影响到整个集群的资源配额执行。这种情况下,集群可能无法正确限制资源使用,导致超额配置或资源分配不均。以下是一个实际案例,展示了 ResourceQuota Controller 因为同步超时而影响集群运作的情况:
E0119 11:37:53.532226 1 shared_informer.go:243] unable to sync caches for garbage collector
E0119 11:37:53.532261 1 garbagecollector.go:228] timed out waiting for dependency graph builder sync during GC sync (attempt 73)
I0119 11:37:54.680276 1 request.go:645] Throttling request took 1.047002085s, request: GET:https://10.150.233.43:6443/apis/configuration.konghq.com/v1beta1?timeout=32s
I0119 11:37:54.831942 1 shared_informer.go:240] Waiting for caches to sync for garbage collector
I0119 11:38:04.722878 1 request.go:645] Throttling request took 1.860914441s, request: GET:https://10.150.233.43:6443/apis/acme.cert-manager.io/v1alpha2?timeout=32s
E0119 11:38:04.861576 1 shared_informer.go:243] unable to sync caches for resource quota
E0119 11:38:04.861687 1 resource_quota_controller.go:447] timed out waiting for quota monitor sync
在这个范例中,我们可以看到 API Server 发出请求到 ResourceQuota 控制器时,可能会因为控制平面负载过高而导致处理延迟,使得套用的 ResourceQuota 更新与 etcd 的记录不一致,比如套用新的内存上限 (52Gi) 但无法在新的资源中同步套用 (62Gi)。
$ kubectl get quota webs-compute-resources -n webs -o yaml
spec:
hard:
pods: "18"
limits.cpu: "26"
limits.memory: "52Gi"
status: {}
$ kubectl describe namespace webs
Name: webs
Labels: team=webs
webs.tree.hnc.x-k8s.io/depth=0
Annotations: <none>
Status: Active
Resource Quotas
Name: webs-compute-resources
Resource Used Hard
-------- --- ---
Resource Limits
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 2 150m 500m -
Container memory 16Mi 18Gi 32Mi 64Mi -
新建立的 Pod 事件仍参考旧有的内存限制 (62Gi),但后续的更新显示限制已降至 52Gi,然而系统行为仍然参考旧的限制值。这种不一致性可能导致资源配置混乱,甚至阻碍新 Pod 的建立。在高负载环境中,控制平面组件之间的同步延迟会更加严重。
creating: pods "workspace-7cc88789c5-fmcxm" is forbidden: exceeded quota: compute-resources, requested: limits.memory=10Gi, used: limits.memory=60544Mi, limited: limits.memory=62Gi
4. 资源限制和扩展性问题 (Data Plane)
当 webhook 服务的资源配置不足,或者无法有效地进行水平扩展时,可能会导致服务不稳定。例如,如果 webhook Pod 的内存限制设置过低,可能会导致 OOM(Out of Memory)错误;或者如果没有正确配置 HPA(Horizontal Pod Autoscaling),在高负载时可能无法及时扩展来处理增加的请求量。
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: pod-resources-example
spec:
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
containers:
- name: memory-demo-ctr
image: nginx
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
连锁故障案例
连锁故障是指当一个核心组件的 webhook 出现问题时,可能会触发一连串的系统性故障。以下是几个实际案例:
系统资源耗尽故障案例
在一个真实案例中,Webhook 服务因为因为节点资源不足发生的错误。核心问题由于节点的内存不足加上磁盘空间接近满触发驱逐事件 (Eviction):
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
example-pod-1234 0/1 Evicted 0 5m
example-pod-5678 0/1 Evicted 0 10m
example-pod-9012 0/1 Evicted 0 7m
example-pod-3456 0/1 Evicted 1 15m
example-pod-7890 0/1 Evicted 0 3m
最终导致新的 Pod 无法创建,造成整个服务不可用。
$ kubectl get events -n curl
...
23m Normal SuccessfulCreate replicaset/curl-9454cc476 Created pod: curl-9454cc476-khp45
22m Warning FailedCreate replicaset/curl-9454cc476 Error creating: Internal error occurred: failed calling webhook "namespace.sidecar-injector.istio.io": failed to call webhook: Post "https://istiod.istio-system.svc:443/inject?timeout=10s": dial tcp 10.96.44.51:443: connect: connection refused
Node-pressure Eviction 发生在当节点面临资源压力(例如内存不足、磁盘空间不足或磁盘 I/O 压力)时。Kubelet 会根据预设或自定义的阈值监控这些资源,当超过阈值时,节点会被标记为有压力状态,并开始驱逐 Pod 以释放资源。这种情况下,优先级较低的 Pod 会先被驱逐,直到节点资源压力降低到安全水平。然而,如果驱逐进程未能及时停止,可能会连锁影响到关键的 webhook 服务 Pod,导致它们也被驱逐。当 webhook 服务不可用时,API Server 无法完成任何受该 webhook 关联的资源操作,进而导致整个集群的功能受限。在高压力环境下,这种连锁反应可能会迅速扩散,从单个节点问题演变为全集群服务中断。
Kubernetes Controller Manager 阻塞故障案例
在这个案例中,Controller Manager 因为无法与 webhook 服务建立连接而陷入重试循环,导致系统性能下降。从日志可以看出,控制器尝试同步作业时遇到了 webhook 调用失败的问题:
I0623 12:15:42.123456 1 job_controller.go:256] Syncing Job default/example-job
E0623 12:15:42.124789 1 job_controller.go:276] Error syncing Job "default/example-job": Internal error occurred: failed calling webhook "validate.jobs.example.com": Post "https://webhook-service.default.svc:443/validate?timeout=10s": dial tcp 10.96.0.42:443: connect: connection refused
W0623 12:15:42.125000 1 controller.go:285] Retrying webhook request after failure
E0623 12:15:52.130123 1 job_controller.go:276] Error syncing Job "default/example-job": Internal error occurred: failed calling webhook "validate.jobs.example.com": Post "https://webhook-service.default.svc:443/validate?timeout=10s": dial tcp 10.96.0.42:443: connect: connection refused
W0623 12:15:52.130456 1 controller.go:285] Retrying webhook request after failure
在这个案例中,原先只是单一个 Webhook 故障导致 Pod 无法建立的错误,然而,引爆连锁故障的关键在于这个案例也同时部署了大量的 Kubernetes Jobs,这些 Kubernetes Jobs 会连续不断地被重新建立,每一次 Job 建立都会触发 webhook 调用。
当 webhook 服务不可用时,Job Controller 会进入重试循环。Job Controller 同时属于 Kubernetes Controller Manager 的一部分,Kubernetes Controller Manager 本身的设计为一个无穷回圈,不断的运行其他控制器。随着 Job 数量增加,Job Controller 的资源消耗急剧上升 (CPU),因为回圈大部分时间都在处理 Job Controller 的工作,进而影响到其他 Kubernetes Controller Manager 核心功能的正常运作。
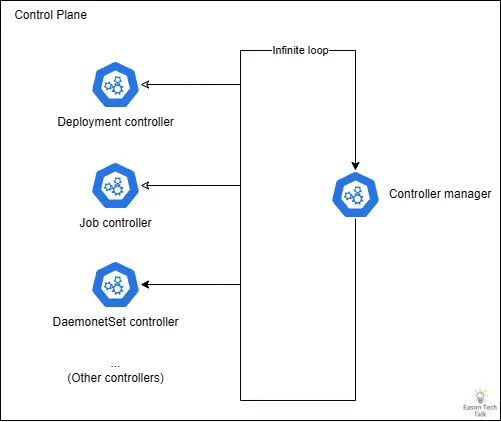
这种情况特别严重的是,当 Kubernetes Controller Manager 的处理能力被大量 Job Controller 触发的 webhook 重试请求占用时,它无法有效地执行其他关键控制器,如 Deployment、StatefulSet 或 DaemonSet。
当 Kubernetes Controller Manager 反复尝试与不可用的 webhook 服务通信,导致控制回圈被阻塞。随着重试次数增加,越来越多的请求堆积,这种阻塞效应会迅速扩散,特别是当涉及核心组件(如 CNI 插件依赖地的 DaemonSet Controller)时,CNI 无法正确部署,可能导致新扩展出来的节点无法正确初始化 (处于 NotReady 状态),即使有足够的硬件资源也无法恢复服务。
Calico + Kyverno 案例
如果有关键组件 (例如 CNI) 与 Webhook 服务存在依赖关系时,更要特别注意 Webhook 故障对于集群可用性的影响,否则一个简单的 Webhook 故障可能会导致更严重的连锁效应。
在这个案例提供的审计记录档中,显示 Calico 网络组件和 Kyverno 策略引擎之间的相互阻塞导致了严重的集群可用性问题。当 Calico 需要更新服务配置时,Kyverno 的 webhook 无法正常回应,因为它没有可用的端点。这种死锁状态使关键的网络元件无法更新,最终导致整个集群的网络功能受损或完全失效。
{
"kind": "Event",
"apiVersion": "audit.k8s.io/v1",
"level": "RequestResponse",
"stage": "ResponseComplete",
"requestURI": "/api/v1/namespaces/calico-system/services/calico-typha",
"verb": "update",
"responseStatus": {
"metadata": {},
"status": "Failure",
"message": "Internal error occurred: failed calling webhook \"validate.kyverno.svc-fail\": failed to call webhook: Post \"https://kyverno-svc.kyverno.svc:443/validate/fail?timeout=10s\": no endpoints available for service \"kyverno-svc\"",
"reason": "InternalError",
"details": {
"causes": [{
"message": "failed calling webhook \"validate.kyverno.svc-fail\": failed to call webhook: Post \"https://kyverno-svc.kyverno.svc:443/validate/fail?timeout=10s\": no endpoints available for service \"kyverno-svc\""
}]
},
"code": 500
},
}
这种错误轻则影响网络策略 (NetworkPolicy) 无法正常工作,顶多影响一些 Pod 的网络通信,然而,严重点则可能导致整个集群网络完全失效。当 Calico 网络元件无法更新或重新配置时,整个集群的网络功能可能会被瘫痪,节点间的通信完全中断,新节点也无法加入集群。
监控与侦测策略
前面我们探讨了一些 webhook 故障的模式,在了解到 webhook 故障所带来的可能影响后,下面要继续讨论一些可以考虑实行的一些错误侦测和监控策略。
1. 关键指标监控
Kubernetes 预设提供了许多内建以 Prometheus 格式呈现的关键指标 2,涉及 Admission Webhook 相关的指标通常有以下几项:
webhook_rejection_count: 追踪被拒绝的webhook请求数量,异常增加可能表示配置问题或服务不稳定。webhook_request_total: 记录所有请求总数,帮助了解流量趋势并识别潜在异常模式。webhook_fail_open_count: 记录因故障而自动通过的请求数,对设置 failurePolicy: Ignore 的 webhook 尤其重要。
这些指标可以通过访问 /metrics 路径采集,常见通过 Prometheus、Datadog 或其他支持 Prometheus 格式的监控系统来收集和分析。以下是一个通过 kubectl 命令检查 API Server 相关指标的范例:
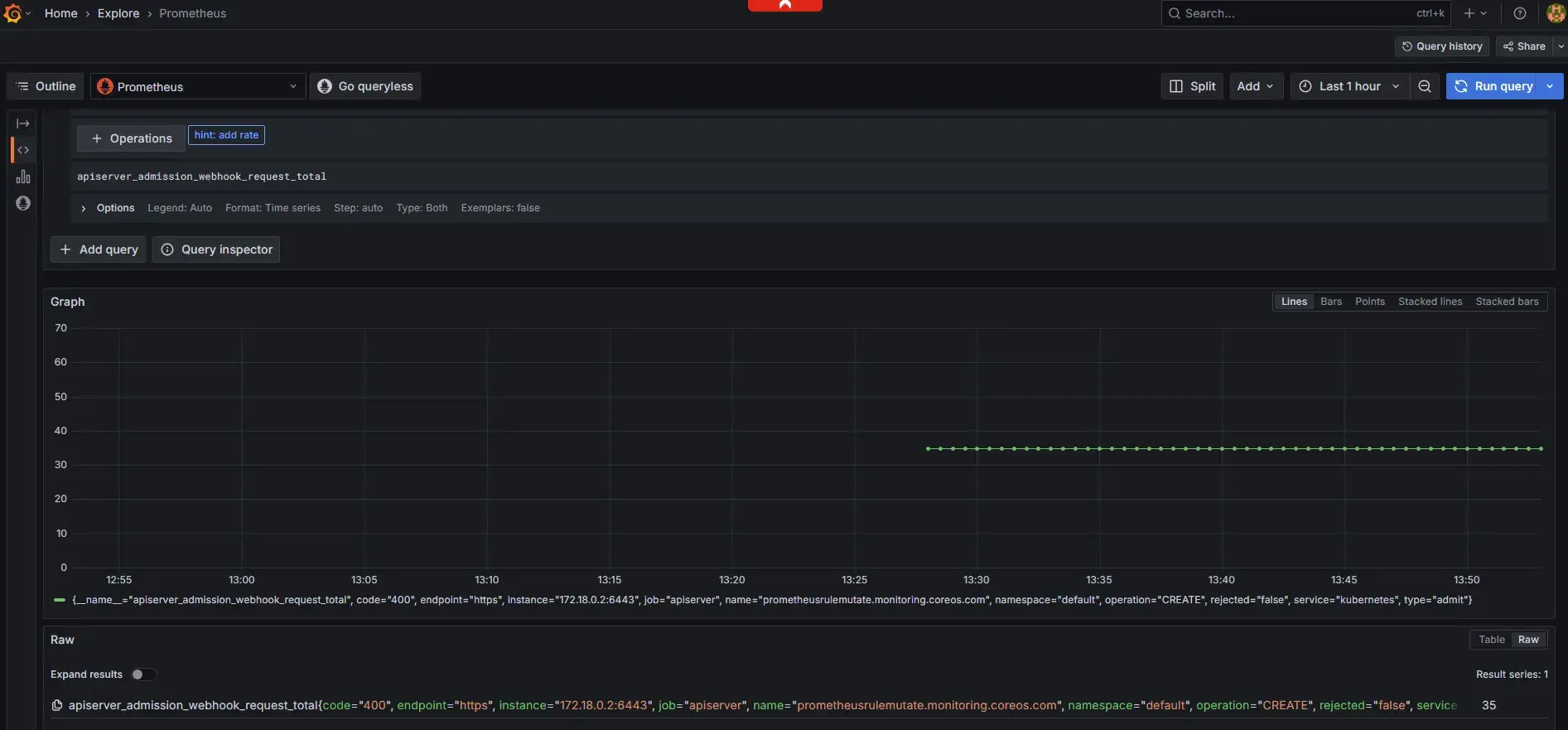
$ kubectl get --raw /metrics | grep "apiserver_admission_webhook"
apiserver_admission_webhook_request_total{code="400",name="mpod.elbv2.k8s.aws",operation="CREATE",rejected="true",type="admit"} 17
$ kubectl get --raw /metrics | grep "apiserver_admission_webhook_rejection"
apiserver_admission_webhook_rejection_count{error_type="calling_webhook_error",name="mpod.elbv2.k8s.aws",operation="CREATE",rejection_code="400",type="admit"} 17
一些开源的社区整合方案则包含 kube-prometheus-stack 套件,可以通过 Helm 工具快速的安装套件,提供完整的 Prometheus 和 Grafana 监控解决方案,包含预设的 API Server 和 Webhook 相关指标仪表板。这种整合式方案不仅能帮助我们监控 webhook 的运作状态,还能在潜在问题发生前提供预警。
此外,针对关键性的应用和服务,可以参考是否提供对应的 Prometheus 或对应指标监控应用的可用性,建立特定的监控指标和警报阈值。同时监控相关的资源使用情况,如 CPU、内存使用率,以及网络延迟等指标。
2. 记录档分析
除了 API server 指标,你也可以通过记录档分析来主动过滤和发现可能的调用失败错误。当遇到 webhook 相关问题时,分析API server的日志可以提供宝贵的线索。从 API Server 触发 webhook 的操作中便可以窥知一二,Kubernetes 在 Mutating 以及 Validating 阶段存在 dispatcher.go 副程序进行触发操作,在目前版本中 (Kubernetes v1.33),皆以 failed to call webhook 作为错误信息输出 3 4:
if err != nil {
var status *apierrors.StatusError
if se, ok := err.(*apierrors.StatusError); ok {
status = se
} else {
status = apierrors.NewServiceUnavailable("error calling webhook")
}
return &webhookutil.ErrCallingWebhook{WebhookName: h.Name, Reason: fmt.Errorf("failed to call webhook: %w", err), Status: status}
}
因此,我们可以通过上述输出作为关键字。当 Webhook 发生故障时,API Server 通常会记录详细的错误信息,包括连接超时、TLS 错误或服务不可用等问题。并且在云原生环境中配置集中式日志收集与分析系统。
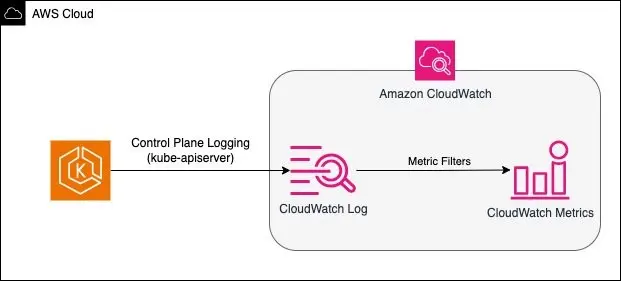
以下是在 AWS CloudWatch Log Insight 中过滤 API Server 日志的范例查询,这个简单的查询示例过滤了所有包含 failed to call webhook 的 kube-apiserver 日志 5:
fields @timestamp, @message, @logStream
| filter @logStream like /kube-apiserver/
| filter @message like 'failed to call webhook'
以下是以 CloudWatch 为例,将过滤的结果转换成指标,用于监控或是设定告警等 5。
若是自建或是私有地端的 Kubernetes 集群环境,同样地也可以持续过滤这些 API Server 日志,整合自动告警机制,即时发送通知捕捉这些错误。
3. 健康状态监控
定期检查 webhook 服务的健康状态是预防问题的第一道防线:
- 设置基本的 Liveness Probe 和 Readiness Probe
- 监控服务的响应时间和错误率
- 追踪 webhook 服务的资源使用情况(CPU、内存等)
最佳实践
在本节中,我们将探讨防止和应对 Kubernetes Webhook 故障的最佳实践。这些建议来自于实际生产环境中的经验,旨在帮助您建立更稳健的 Kubernetes 环境。以下是几个关键领域的最佳实践建议:
1. 资源配置最佳化
- 为 webhook 服务设置适当的资源请求和限制
- 为关键 webhook 服务运行多个副本并且实施水平自动扩展(HPA)以应对负载变化
- 使用 Pod Disruption Budget 确保服务可用性
2. 安全性考量
- 定期轮换 TLS 证书,尤其是在使用自签证书的情况下
- 使用 cert-manager 实施自动化的证书管理时,务必关注证书的有效期限和更新状态
3. 其他优化考量
- 在专用命名空间 (Namespace) 中运行自定义 webhook 服务,避免故障时影响所有 Namespace (例如:正确使用 namespaceSelector 和 objectSelector 等避免故障时影响所有资源,甚至造成 deadlock)
- 对于 Kubernetes v1.30 之后的版本,考虑使用 ValidatingAdmissionPolicy 取代传统的验证 webhook,降低外部应用的依赖,以改善系统稳定性
这是一个简易的 ValidatingAdmissionPolicy 范例,描述当建立或更新 Deployment 时,副本数量应小于或等于五个。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicy
metadata:
name: "demo-policy.example.com"
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
validations:
- expression: "object.spec.replicas <= 5"
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: "demo-binding-test.example.com"
spec:
policyName: "demo-policy.example.com"
validationActions: [Deny]
matchResources:
namespaceSelector:
matchLabels:
environment: test
这类资源可以在 Kubernetes Control Plane 层面完成您原本依赖外部 Webhook 服务的机制,无需调用外部 Webhook,从而降低因外部因素导致无法调用 Webhook 的风险。
📝 註:MutatingAdmissionPolicy 与 ValidatingAdmissionPolicy 类似,但提供修改资源的能力,目前在 Kubernetes v1.32 版本中处于 Alpha 阶段。这项功能将使得开发者能够直接在 Kubernetes API 中定义资源修改规则,而无需部署和维护外部 webhook 服务,进一步减少系统故障点。详细信息,请参考 KEP-39626。
总结
Kubernetes Admission Webhook 提供了强大的扩展能力,但同时也引入了潜在的风险点。通过了解常见的故障模式、实施有效的监控策略、采用最佳实践,我们可以显著提高系统的稳定性和可靠性。
本篇文章已经详细介绍了 Kubernetes Webhook 的故障管理,从基本概念到诊断方法,再到监控策略和最佳实践。我们看到了如何识别常见的故障模式,以及如何通过指标监控和日志分析来预防问题。特别值得注意的是,随着 Kubernetes 的发展,像 ValidatingAdmissionPolicy 这样的新功能正在减少对外部 webhook 的依赖,从而提高系统的稳定性。
希望这篇文章能为你提供有价值的见解和实用的工具,帮助你更有效地管理 Kubernetes 环境中的 webhook 服务。
📧 订阅 EasonTechTalk:获得技术洞察与实战分享
如果你对了解云端技术和相关趋势有兴趣,欢迎订阅 EasonTechTalk 电子报以取得更新,让我们一起在技术路上持续精进!
参考资源
