
Kueue 快速上手:在 Kubernetes 上排队管理共享 GPU/TPU 资源
这篇文章会帮助你在 10 分钟内理解 Kueue 是什么、为什么需要它,以及如何在共享 GPU/TPU 集群上使用它。
为什么只靠 Kubernetes 还不够?
Kubernetes 本身可以通过 Job 或 CronJob 运行批处理工作负载,但它并不擅长管理批任务的资源分配和等待逻辑。Kubernetes 很擅长把 Pod 调度到节点上,却不擅长控制 batch workload 的 admission(准入)时机。
以 AI/ML 训练任务为例,通常需要大量计算资源(如 GPU 或 TPU)。在多团队共享 GPU/TPU 的集群中,Kubernetes 原生调度机制很容易出现这些问题:
- 缺少排队机制:资源不足时,Job 可能直接失败,或 Pod 长时间处于 Pending,而不是按策略等待。
- 缺少配额治理:单个团队可能占满所有 GPU/TPU,其他团队只能排队空等。
- 缺少优先级准入:低优先级实验可能阻塞高优先级生产训练任务。
- 缺少公平分配:无法保证各团队获得合理资源份额。
Kueue(发音类似 queue)就是为了解决这些问题而设计的 Kubernetes 原生作业排队系统(job queueing system)。它会先将 Job 暂存(hold)在队列中,只有当配额范围内资源充足时,才放行(admit)该 Job。
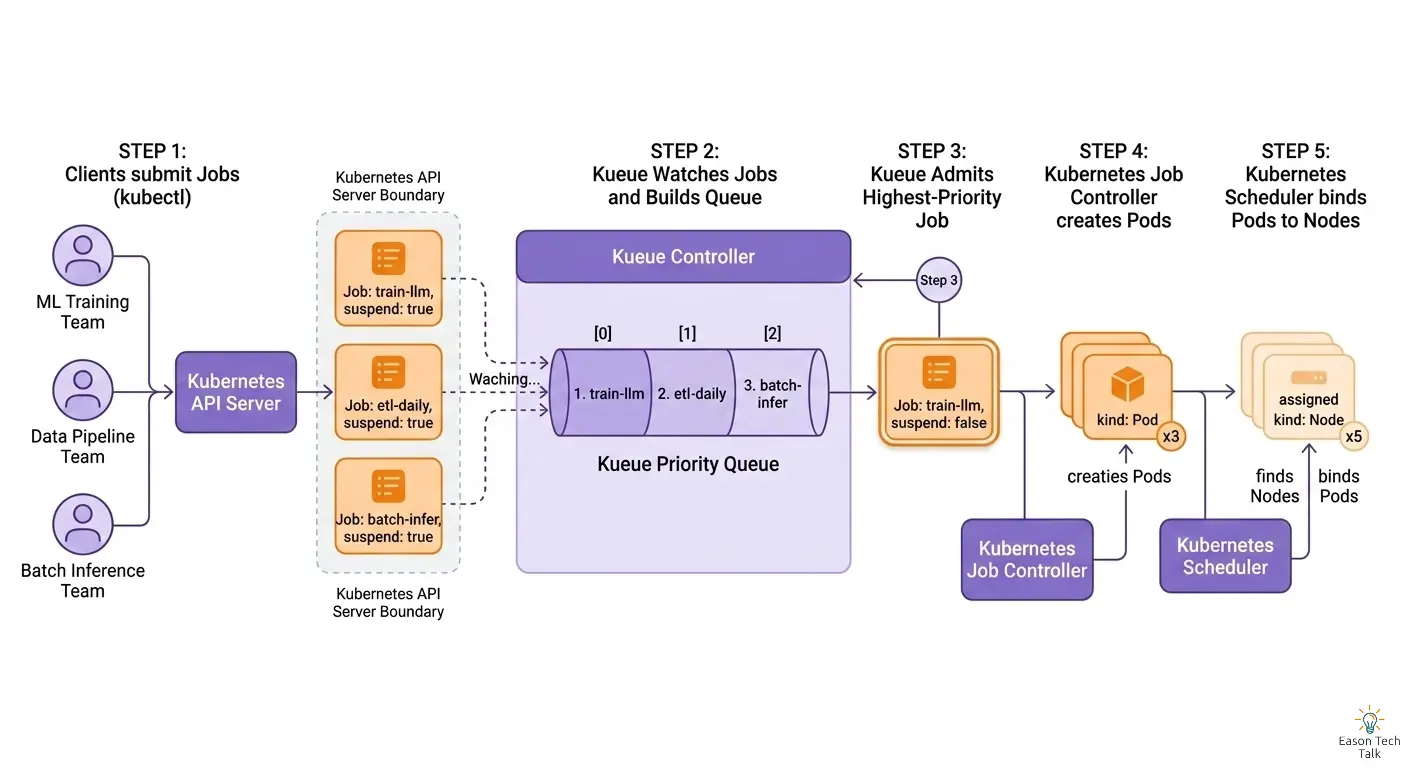
什么是 Kueue?
Kueue 是一个 Kubernetes Controller,位于 Job 提交与 Kubernetes Scheduler 之间。它不会替代 Scheduler,而是决定你的 Job “什么时候”可以开始执行。
如果把 Kubernetes 看作集群的“操作系统”,那 Kueue 就像空中交通管制塔台(traffic control tower),决定哪架航班(工作负载)何时起飞。
Kueue 提供的核心能力:
- 配额管理(Quota Management):为各团队设置资源使用上限
- 基于优先级的调度(Priority-based Scheduling):高优先级工作优先获得资源
- 公平共享(Fair Sharing):在多团队之间公平分配 GPU/TPU
- 资源感知准入(Resource-aware Admission):仅在资源充足时才准入 Job
Kueue vs Job vs JobSet:三者关系
常见问题:“我已经用了 JobSet,还需要 Kueue 吗?”
答案是需要,因为两者解决的是不同层面的问题,配合使用效果最好。
| 层级 | 工具 | 职责 |
|---|---|---|
| Pod 调度 | Kubernetes 原生 Scheduler | 将 Pod 分配到具体 Node 上运行 |
| Job 编排 | JobSet | 将多个存在依赖关系的 Job 作为一个单元统一管理(例如 1 个 leader + 3 个 worker 协同启动) |
| Job 准入 | Kueue | 基于配额、优先级和公平共享策略,决定 Job 何时允许执行 |
- 仅使用 Job:单一批处理任务,无队列治理。适合专用集群上的简单场景。
- 仅使用 JobSet:支持多角色分布式工作负载编排,但缺少集群级资源治理。
- 仅使用 Kueue:为独立 Job 提供排队与配额控制。
- Kueue + JobSet:完整方案,同时具备复杂分布式编排能力和集群级资源治理能力,适合大规模 TPU/GPU 训练。
一句话总结:JobSet 管“怎么跑”,Kueue 管“什么时候能跑”。
核心概念
在写 YAML 之前,先理解 Kueue 的四个核心抽象:
| 概念 | 说明 | 类比 |
|---|---|---|
| ResourceFlavor | 定义集群可用资源类型(如 TPU v6e 1x1 topology、A100 GPU、纯 CPU 节点),并通过 Node Label 映射到实际节点 | 菜单:厨房能提供哪些菜 |
| ClusterQueue | 集群级队列;为每种 ResourceFlavor 设置资源配额(nominalQuota),控制可并发消耗的总资源量 |
厨房:控制总产能 |
| LocalQueue | Namespace 级队列;用户提交入口,会把请求转发到对应 ClusterQueue 做配额检查 | 服务员:接单并转交厨房 |
| Workload | Kueue 对 Job/JobSet 的内部封装对象;当 Job 带有 kueue.x-k8s.io/queue-name 时自动创建 |
订单小票:跟踪请求状态 |
什么时候该用 Kueue?
| 适用场景 | 为什么需要 Kueue | 典型示例 |
|---|---|---|
| 多团队共享集群 | 多团队竞争有限 GPU/TPU,需要配额治理与公平共享 | ML 团队 A 与团队 B 共用同一套 8 张 A100 |
| 高价值加速器资源 | TPU/GPU 不应因准入策略不佳而闲置,Kueue 可提升利用率 | TPU v6e 单价高,闲置 1 小时就会浪费成本 |
| 批处理工作负载(Batch) | 训练、数据处理流水线、CI/CD 等任务可接受排队等待 | 高峰期排队,低峰期自动执行 |
| 云成本控制 | 通过硬配额(hard quota)防止过度申请,降低不必要支出 | 限制单团队最多使用 16 个 TPU chips |
| Multi-slice TPU 训练 | JobSet 负责多节点编排,Kueue 控制准入时机 | 使用 3 个 TPU slice 进行 Multislice JAX 训练 |
只要你的集群中有多个团队提交 batch jobs,就应当认真考虑 Kueue。若你已使用 JobSet 做多节点训练,叠加 Kueue 就能补齐资源治理能力。
工作机制:Admission 流程
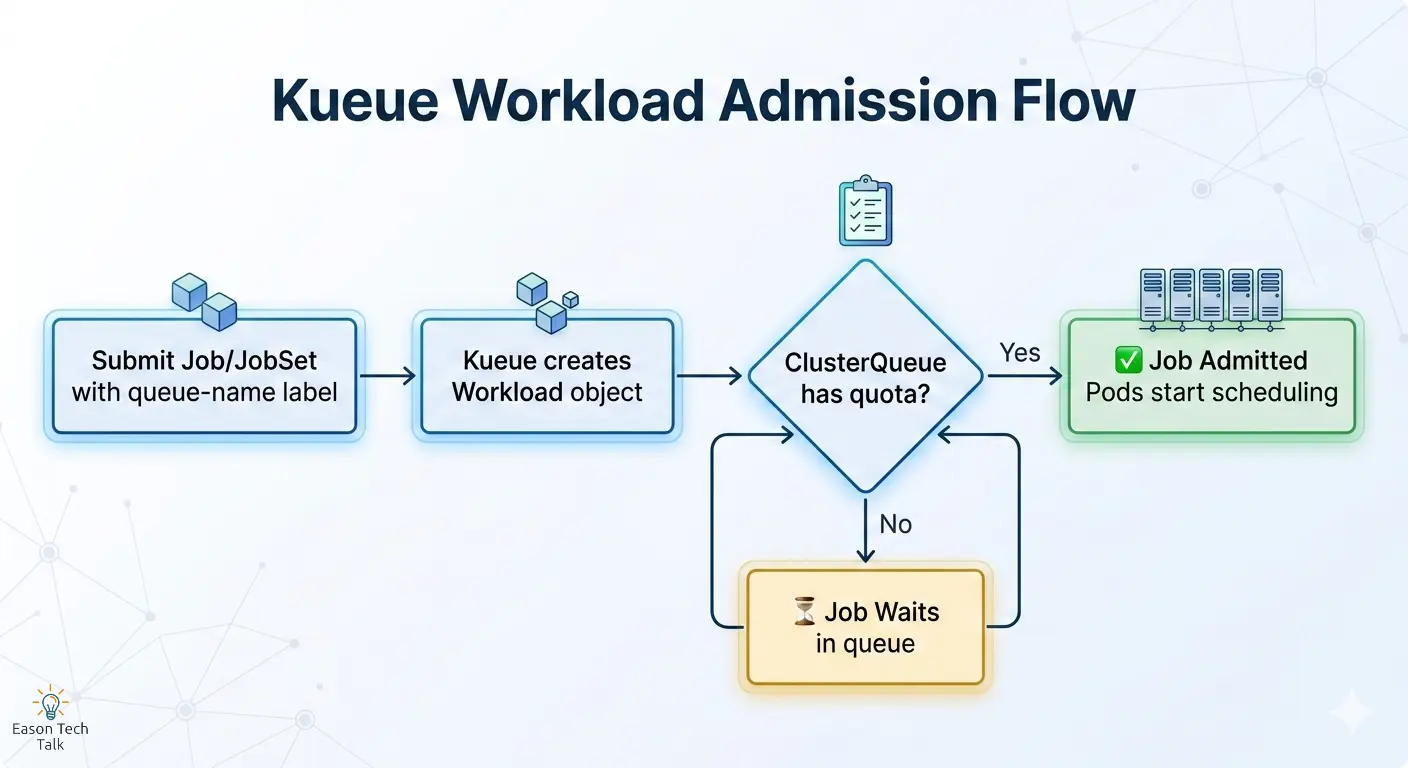
- 提交 Job 或 JobSet,并添加
kueue.x-k8s.io/queue-name指向目标 LocalQueue - Kueue 自动创建 Workload 对象,并检查 ClusterQueue 的可用配额
- 配额充足:Job 被 admitted(准入),Pod 开始进入调度流程
- 配额不足:Job 在队列中等待,直到资源释放
快速实操:3 步配置 Kueue
下面示例使用 CPU 与内存作为配额资源,可在任意标准 Kubernetes 集群中直接验证 Kueue 的行为,无需 GPU 或 TPU。
架构总览
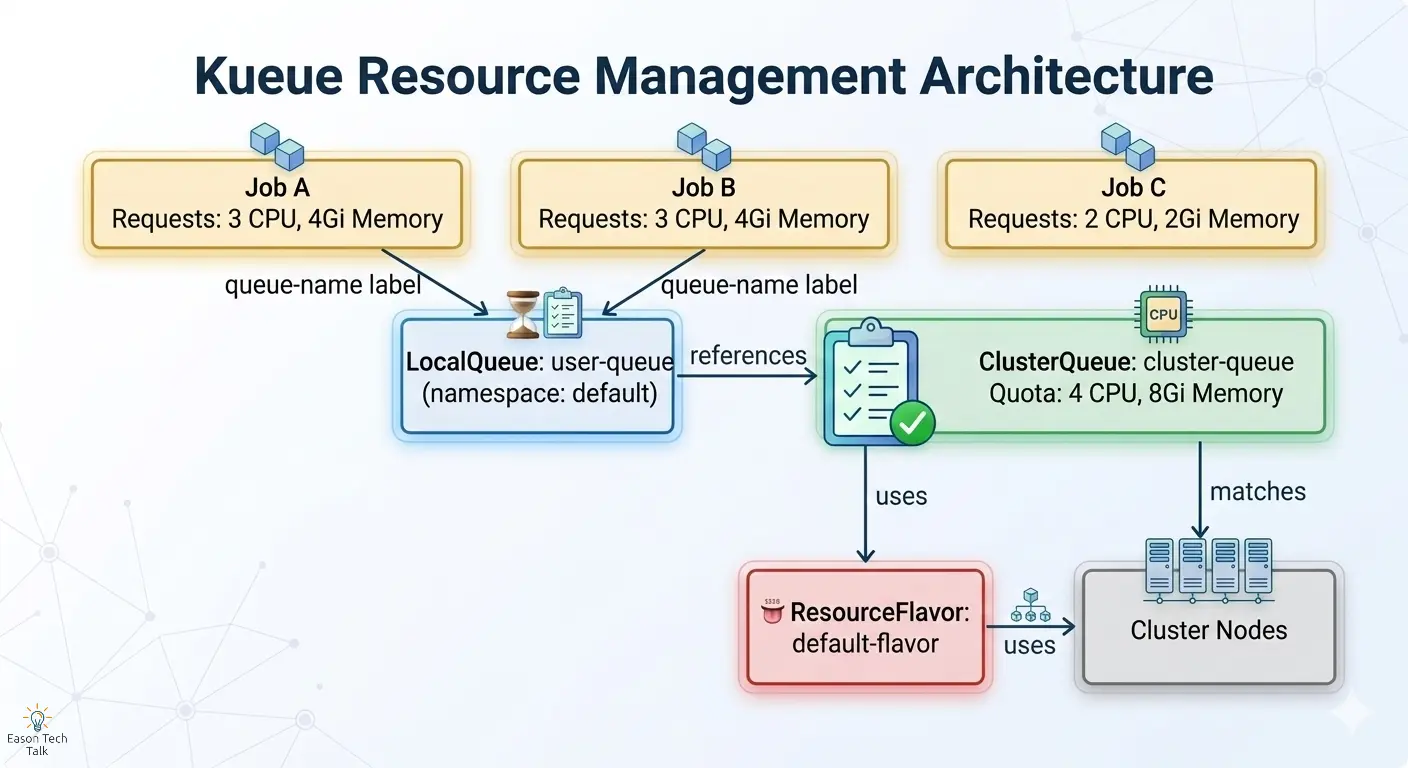
步骤一:安装 Kueue
# 安装 Kueue
helm install kueue oci://registry.k8s.io/kueue/charts/kueue \
--namespace kueue-system \
--create-namespace \
--wait --timeout 300s
步骤二:配置 ResourceFlavor + ClusterQueue + LocalQueue
# ResourceFlavor:使用 default flavor(不限制特定节点)
apiVersion: kueue.x-k8s.io/v1beta2
kind: ResourceFlavor
metadata:
name: default-flavor
spec: {} # 空 spec 表示任意节点都可匹配
---
# ClusterQueue:设置 CPU 与内存总配额
apiVersion: kueue.x-k8s.io/v1beta2
kind: ClusterQueue
metadata:
name: cluster-queue
spec:
namespaceSelector: {} # 允许所有 namespace
queueingStrategy: BestEffortFIFO
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: default-flavor
resources:
- name: "cpu"
nominalQuota: 4 # 总计可用 4 个 CPU cores
- name: "memory"
nominalQuota: 8Gi # 总计可用 8Gi 内存
---
# LocalQueue:用户提交工作负载的入口
apiVersion: kueue.x-k8s.io/v1beta2
kind: LocalQueue
metadata:
namespace: default
name: user-queue
spec:
clusterQueue: cluster-queue
步骤三:提交带 Kueue Label 的 Job
提交两个 Job,每个请求 3 个 CPU。由于 ClusterQueue 总配额只有 4 个 CPU,第一个 Job 会立即被 admitted,第二个会进入队列等待,直到第一个完成并释放资源。
# Job 1:请求 3 CPU + 4Gi 内存
apiVersion: batch/v1
kind: Job
metadata:
generateName: sample-job-
labels:
kueue.x-k8s.io/queue-name: user-queue # 指向 LocalQueue
spec:
template:
spec:
containers:
- name: worker
image: busybox:1.36
command: ["sh", "-c", "echo 'Hello from Kueue!'; sleep 30"]
resources:
requests:
cpu: "3"
memory: "4Gi"
restartPolicy: Never
backoffLimit: 0
你可以通过以下命令观察 Kueue 的行为:
# 查看 ClusterQueue 状态(配额使用情况)
kubectl get clusterqueue cluster-queue -o wide
# 查看 Workload 对象(确认哪些 Job 已 admitted,哪些在等待)
kubectl get workloads -n default
GKE AI 系列文章
