
JobSet 问题排查:解决 “follower pod node selector not set” 报错
在使用 JobSet 运行 multi-slice TPU 或 GPU 分布式训练时,JobSet 的 leader-follower 机制会先调度 leader Pod,再通过 mutating webhook 读取 leader 所在节点上的 topology label,并把对应的 nodeSelector patch 到 follower Pod 上,以确保同一组 Pod 被调度到同一个拓扑域。这个设计在正常情况下运行良好,但如果底层加速器资源不足,leader Pod 一直卡在 Pending 无法调度,你就可能看到这样一条让人困惑的错误:
admission webhook "vpod.kb.io" denied the request: follower pod node selector not set
直觉上,你可能会先去检查 follower Pod 的 node selector 配置,但真正的问题并不在那里。经过数小时排查后,我发现这条报错其实是一种诊断假象。它掩盖了真正的根因,让你以为是 JobSet 配置写错了,而实际情况很可能只是基础设施容量不足,导致 leader Pod 根本调度不起来。之所以会出现这条误导性报错,是因为 pkg/webhooks/pod_webhook.go 中的 validating webhook 在验证顺序上有一个很微妙的问题:它先检查 follower 的 NodeSelector,却没有先确认 leader 是否已经完成调度。
在定位到这个问题后,我开了 Issue #1187,并提交了两个 PR,从不同层面进行修复。本文会结合这次真实的排障经历,拆解 JobSet 的 leader-follower 调度机制、mutating 与 validating webhook 的交互关系,以及为什么只要调整一下验证顺序,就能把误导性的报错变成真正有帮助的诊断信息。
本文中的代码引用基于 JobSet
main分支在 PR #1159 重构之后的实现。该 PR 将原先分散在pod_mutating_webhook.go和pod_admission_webhook.go中的逻辑合并为单一的pod_webhook.go,并采用 controller-runtime 的admission.Defaulter与admission.Validator接口。在release-0.11及更早版本中,相同逻辑仍分布在两个文件里,但验证顺序的问题是一样的。
JobSet Leader-Follower 机制概览
当 JobSet 处理 TPU multi-slice 或任何需要 exclusive placement 的工作负载时,会采用 leader-follower 调度模型。核心逻辑很简单:先调度 leader Pod(completion index 0),然后在 follower Pod 被创建并进入 admission 流程时,由 mutating webhook 读取 leader 所在节点的 topology label,再把对应的 nodeSelector patch 到 follower Pod 上,从而保证 follower 会被调度到同一个 topology domain。
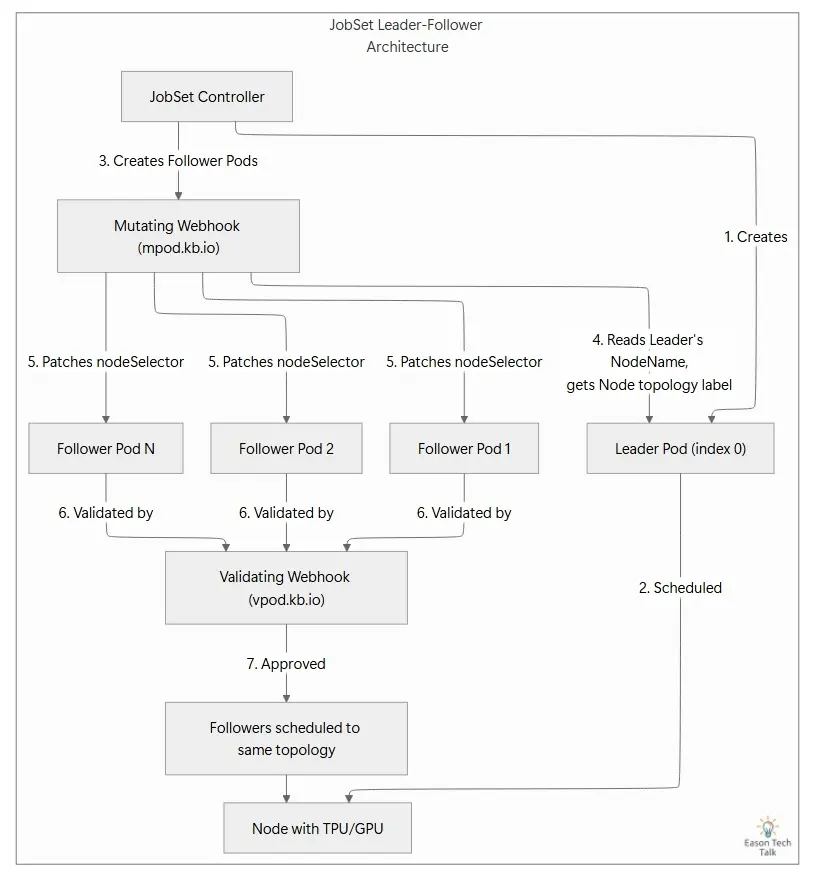
整个流程依赖以下两个 webhook 的协同工作。
Mutating Webhook:负责 Patch Node Selector
JobSet 的 mutating webhook(mpod.kb.io)会拦截每一个 Pod 创建请求。对于使用 exclusive placement 的 follower Pod,它会调用 setNodeSelector:
- 首先通过
leaderPodForFollower找到对应的 leader Pod,然后检查 leader 的Spec.NodeName是否已经被设置。 - 如果 leader 已经调度完成,webhook 就会调用
topologyFromPod获取 leader 所在节点上的 topology label,例如 node pool 名称,并把这个值 patch 到 follower Pod 的nodeSelector中。 - 但如果 leader 还处于
Pending,也就是Spec.NodeName为空,mutating webhook 就会直接返回nil,不做任何 patch。代码注释也明确说明了:拒绝 follower 的责任交给 validating webhook。
func (p *podWebhook) setNodeSelector(ctx context.Context, pod *corev1.Pod) error {
log := ctrl.LoggerFrom(ctx)
// Find leader pod (completion index 0) for this job.
leaderPod, err := p.leaderPodForFollower(ctx, pod)
if err != nil {
log.Error(err, "finding leader pod for follower")
// Return no error, validation webhook will reject creation of this follower pod.
return nil
}
// If leader pod is not scheduled yet, return error to retry pod creation until leader is scheduled.
if leaderPod.Spec.NodeName == "" {
// Return no error, validation webhook will reject creation of this follower pod.
return nil
}
// Get the exclusive topology value for the leader pod (i.e. name of nodepool, rack, etc.)
topologyKey, ok := pod.Annotations[jobset.ExclusiveKey]
if !ok {
return fmt.Errorf("pod missing annotation: %s", jobset.ExclusiveKey)
}
topologyValue, err := p.topologyFromPod(ctx, leaderPod, topologyKey)
if err != nil {
log.Error(err, "getting topology from leader pod")
return err
}
// Set node selector of follower pod so it's scheduled on the same topology as the leader.
if pod.Spec.NodeSelector == nil {
pod.Spec.NodeSelector = make(map[string]string)
}
log.V(2).Info(fmt.Sprintf("setting nodeSelector %s: %s to follow leader pod %s", topologyKey, topologyValue, leaderPod.Name))
pod.Spec.NodeSelector[topologyKey] = topologyValue
return nil
}
这种行为本身是符合预期的。因为 leader 还没调度到具体节点时,JobSet 就无法知道对应的 node topology label,自然也没有任何值可供 patch。
Validating Webhook:负责校验 Follower Pod 是否合法
在 mutating webhook 执行完之后,vpod.kb.io validating webhook 会继续执行 ValidateCreate。在 pkg/webhooks/pod_webhook.go 里,这段验证流程包含两个关键检查:
- NodeSelector 检查:确认 follower Pod 是否已经带有 node selector
- Leader 调度状态检查:确认 leader Pod 是否已经完成调度
// ValidateCreate validates that follower pods (job completion index != 0) part of a JobSet using exclusive
// placement are only admitted after the leader pod (job completion index == 0) has been scheduled.
func (p *podWebhook) ValidateCreate(ctx context.Context, pod *corev1.Pod) (admission.Warnings, error) {
...
// Do not validate anything else for leader pods, proceed with creation immediately.
if placement.IsLeaderPod(pod) {
return nil, nil
}
// If a follower pod node selector has not been set, reject the creation.
if pod.Spec.NodeSelector == nil {
return nil, fmt.Errorf("follower pod node selector not set")
}
if _, exists := pod.Spec.NodeSelector[topologyKey]; !exists {
return nil, fmt.Errorf("follower pod node selector for topology domain not found. missing selector: %s", topologyKey)
}
// For follower pods, validate leader pod exists and is scheduled.
leaderScheduled, err := p.leaderPodScheduled(ctx, pod)
if err != nil {
return nil, err
}
if !leaderScheduled {
return nil, fmt.Errorf("leader pod not yet scheduled, not creating follower pod. this is an expected, transient error")
}
return nil, nil
}
问题的关键就在于这两个检查的顺序。当 validating webhook 先检查 NodeSelector,再去检查 leader 是否已调度时,最终返回的错误信息就不再指向真正的原因。更有诊断价值的 transient error 会被完全遮蔽,用户只能看到一条很误导的失败信息。
验证顺序遮蔽了真正的错误
问题现象
我在 GKE 上运行一个 multi-slice TPU 训练任务时,所有 follower Pod 都被拒绝,报错如下:
admission webhook "vpod.kb.io" denied the request: follower pod node selector not set
与此同时,在 webhook server 的日志里,mutating webhook 有时还会输出另一条信息量更高的报错。当 leader Pod 甚至还没创建出来时,leaderPodForFollower 会返回一个 error,并记录成:
ERROR admission finding leader pod for follower
{"error": "expected 1 leader pod (example-job-0-0), but got 0. this is an expected, transient error"}
这两条信息的差别很关键。大多数用户在事件或报错输出里只会看到 validating webhook 返回的第一条,于是自然会怀疑是 follower Pod 配置有问题。而第二条来自 mutating webhook 的信息,才是真正对排障有帮助的线索。在权限更严格的环境里,详细的 mutating webhook 日志往往只有 cluster admin 才能看到,因此普通用户更容易被 admission 错误所误导。
根因:验证顺序有问题
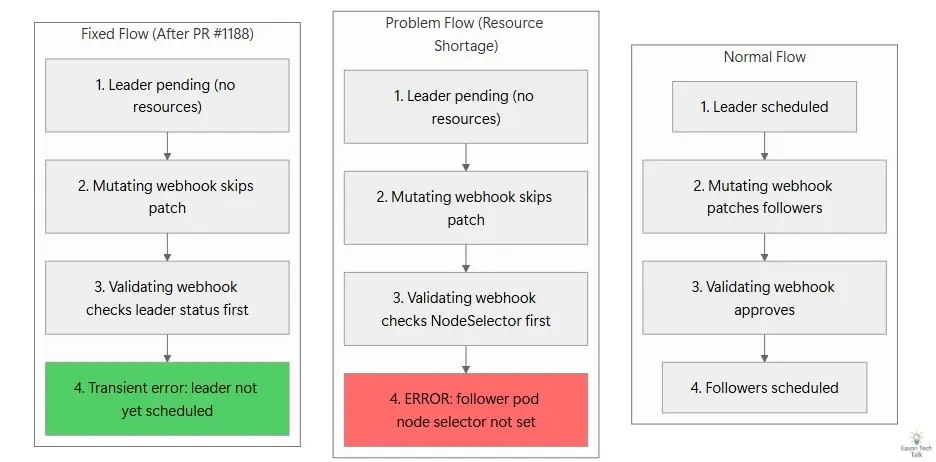
当 leader Pod 因为集群里没有足够的加速器容量而卡在 Pending 时,整个流程实际上是这样的:
- 创建 follower Pod,进入 admission 流程。
- mutating webhook 的
setNodeSelector发现leaderPod.Spec.NodeName为空,于是直接返回nil,不会执行 patch。拒绝这个 follower 的责任被刻意留给 validating webhook。 - follower Pod 进入 validating webhook,也就是
ValidateCreate。 - validating webhook 先检查
NodeSelector,发现它不存在,于是立刻拒绝,并返回follower pod node selector not set。 - 用于检查 leader 是否已完成调度的逻辑根本没有机会执行,因为在第 4 步就已经提前返回了。
这就导致最终看到的错误,只指向最末端的症状,而不是根因:
基础设施容量不足(TPU/GPU 资源不够)
└── Leader pod 一直 Pending(未完成调度)
└── Mutating webhook 正确跳过 patch(符合预期)
└── Follower pod 创建时没有写入 node selector
└── Validating webhook 先检查 NodeSelector 并直接拒绝
├── 用户看到:"follower pod node selector not set"
└── 真正有价值的 transient error 被完全遮蔽 ✘
实际上,JobSet 内部已经准备好了一条设计合理的 transient error,只是因为验证顺序不对,永远不会显示出来。如果把顺序反过来,先检查 leader 是否已调度,用户看到的就会是:
leader pod not yet scheduled, not creating follower pod. this is an expected, transient error
这条信息会直接引导你去看 leader Pod 的调度状态,而不是把时间浪费在 follower 配置上。
下图展示了三种情况:正常流程中 leader 先完成调度;当前实现中由于验证顺序问题,真正有用的错误被遮蔽;以及 PR 修正后的流程中,调整顺序后 transient error 能被正确暴露。
如何排查这个问题
如果你也遇到这个错误,关键点很简单:不要被错误信息带偏,先检查上游的 leader Pod 状态。
首先确认 leader Pod 是否存在,以及是否已经被调度:
kubectl get pods -n <namespace> | grep <jobset-name>.*-0-0
如果 leader Pod 仍然是 Pending,继续用 describe 查看具体原因:
kubectl describe pod <leader-pod-name> -n <namespace>
通常你会看到类似下面这样的事件:
Warning FailedScheduling 0/10 nodes are available: insufficient google.com/tpu resources
到这里,根因就很清楚了。问题不在 follower Pod 的配置,而是集群没有足够的基础设施容量,导致 leader 根本调度不起来。解决方法也很直接:确保集群里有足够的加速器资源供 leader Pod 使用。只要 leader 调度成功,mutating webhook 就会自动把正确的 node selector patch 到 follower Pod 上,后续 validating webhook 也会顺利通过。
提交 PR:从文档到代码的双重修复
找到真正根因后,我开了 Issue #11871,并提交了两个 PR,从不同层面解决这个问题:
- PR #11892(文档改进):在官方 Troubleshooting Guide 中补充排查建议,已经合并。
- PR #11883(代码修复):调整 validating webhook 的验证顺序,让更有帮助的 transient error 可以正确显示。
PR #1189:补充 Troubleshooting 文档
第一个 PR 是文档层面的改进。它在官方 JobSet Troubleshooting Guide 中新增了一节4,明确说明当你看到 follower pod node selector not set 时,首先应该检查的是 leader Pod 的调度状态,而不是直接去改 follower 的配置。
PR #1188:调整验证顺序
第二个 PR 才是真正从代码层面修复问题。在 pkg/webhooks/pod_webhook.go 中,它调整了 ValidateCreate 内部的检查顺序。等这个修复合并之后,当 leader Pod 尚未调度时,用户将看到:
leader pod not yet scheduled, not creating follower pod. this is an expected, transient error
而不是原本那条误导性的 follower pod node selector not set。
结语
在分布式系统里,这种“因果链很长”的 bug 很常见。而在 Kubernetes 生态中,mutating webhook 与 validating webhook 的执行顺序和交互方式,更容易让问题表象与真实根因脱节。这个案例说明了为什么理解这套交互机制很重要,也说明了为什么一个很小的验证顺序调整,就能显著提升排障效率和诊断准确性。
参考资料
-
Issue #1187 - Pod validation webhook obscures leader scheduling state by validating follower NodeSelector too early ↩
-
PR #1189 - docs: add troubleshooting section for follower pod node selector errors ↩
-
PR #1188 - Reorder follower pod validation to surface leader scheduling status ↩
-
JobSet Troubleshooting Guide - 5. Follower pods rejected with “follower pod node selector not set” ↩
