JobSet:让 Kubernetes 真正驾驭多 Job 工作负载
一句话理解 JobSet: 如果 Kubernetes Job 是“单兵作战”,JobSet 就是“协同作战的整支部队”:一个 API 对象,统一管理多组 Job 的生命周期、网络与故障恢复。
为什么要用 JobSet?不是已经有 Kubernetes Job API 了吗?
Kubernetes 原生 Job 的设计假设是:一个 Job = 一个独立的批处理任务。但现实中的分布式工作负载远比这复杂。
以大模型训练为例,你可能同时需要:
- Parameter Server:存储并同步模型权重
- Worker Node:并行处理训练数据
- Coordinator:控制训练流程与 checkpoint
如果分别用原生 Job 创建,你必须自己处理:
- 多个 Job 的启动顺序与依赖关系
- 跨 Job 的 Pod 网络发现
- 任一 Job 失败后的全局重启逻辑
这就像试图用三个独立的 crontab 来编排一场交响乐,技术上可行,但运维成本极高。
JobSet 把这些协同逻辑内建到一个 CRD 中,让你只描述“我要什么”,而不是“怎么串起来”。
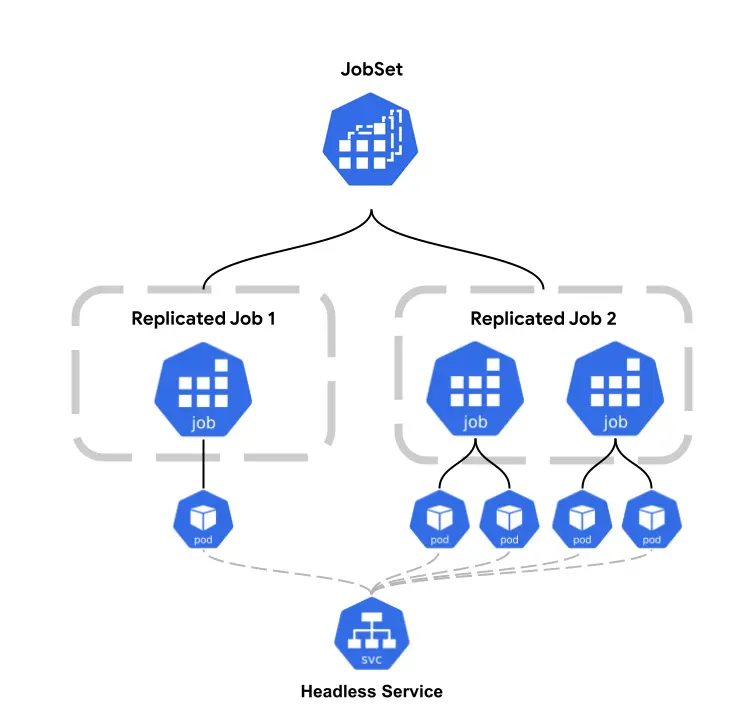 (图片来源:JobSet Conceptual Diagram)
(图片来源:JobSet Conceptual Diagram)
核心能力一览
| 能力 | 做了什么 | 为什么重要 |
|---|---|---|
| ReplicatedJob 分组 | 在同一个 JobSet 中定义多组 Job,各自拥有独立的 Pod Template 与副本数 | 一个 YAML 就能描述多个关联任务,而不是拆成多个 Job 分别管理 |
| 协同生命周期 | 各 Job 作为同一工作负载协同启动,JobSet 跟踪整体成功/失败 | 避免“半成品”状态,例如 worker 已完成但 PS 尚未就绪 |
| 自动创建 Headless Service | 为每个 ReplicatedJob 创建 headless Service,Pod 可通过可预测 DNS 互相发现 | 可直接配合 PyTorch torchrun、TensorFlow MultiWorkerMirroredStrategy 等框架 |
| 灵活失败策略 | 支持 FailJobSet action(目标 Job 失败时触发全局失败/重启)或选择性容忍个别失败 | 可在“训练一致性”与“容错弹性”之间自由取舍 |
典型使用场景
🧠 分布式 ML 训练(最常见)
大规模模型训练,无论是 Parameter Server 架构还是 Data-Parallel 架构,都需要多个角色 Pod 同时运行并互相通信。JobSet 天然适配这种多角色拓扑。结合 Kueue,还能实现 GPU/TPU 资源排队与公平调度。
🔬 HPC 与科学计算
MPI 应用要求所有 rank 在可预测网络地址上同时启动。JobSet 的 headless Service + 协同启动正好解决这一痛点。
🔄 多阶段数据处理
在 ETL pipeline 中,“抽取 → 转换 → 加载”的不同 worker 组可以封装到同一个 JobSet 内,共享生命周期管理。
实际示例:大规模日志分析系统
让我们用一个实际例子理解为什么需要 Leader-Worker 架构。以 Apache Spark 分布式数据处理为例,假设你要处理每天产生的 TB 级网站访问日志,并进行实时异常检测与统计分析。该工作负载天然需要 Leader-Worker 架构。
为什么需要 Leader(Driver)?
- 任务分配与协调:Driver 将大型数据集切分为小块,分配给不同 Worker 处理
- 状态跟踪:监控哪些数据块已完成,哪些失败需要重试
- 结果聚合:汇总各 Worker 结果并进行最终聚合(例如统计 95th percentile 响应时间)
- 资源管理:动态调整 Worker 数量并处理反压(backpressure)
为什么需要多个 Worker?
- 并行处理:100 个 Worker 同时处理不同数据分片,大幅缩短处理时间
- 资源隔离:每个 Worker 处理自己的数据子集,减少内存争用
- 容错能力:单个 Worker 失败不影响其他 Worker,Leader 可重新分配任务
架构示意
┌─────────────────────────────────────────┐
│ Leader (Spark Driver) │
│ - 读取任务配置 │
│ - 切分数据为 1000 个分片 │
│ - 分配给 Worker 处理 │
│ - 跟踪进度:652/1000 完成 │
└──────────────┬──────────────────────────┘
│
┌──────────┼──────────┬──────────┐
│ │ │ │
┌───▼───┐ ┌──▼────┐ ┌──▼────┐ ┌──▼────┐
│Worker1│ │Worker2│ │Worker3│ │Worker4│
│处理 │ │处理 │ │处理 │ │处理 │
│分片1-25│ │分片26 │ │分片51 │ │分片76 │
│ │ │ -50 │ │ -75 │ │ -100 │
└───────┘ └───────┘ └───────┘ └───────┘
真实世界的挑战
- 网络依赖:Worker 需要知道 Leader 地址才能回报进度(
LEADER_HOST环境变量) - 启动顺序:Leader 必须先启动并就绪,Worker 才能开始工作
- 失败处理:Leader 挂掉时整个任务要重来;若只是 Worker 挂掉,Leader 可重分配该部分任务
- 资源争用:在 Kubernetes 中,如何确保 Leader 与 Worker Pod 能同时拿到足够资源?
这正是 JobSet 的价值所在:
原生 Job 无法优雅表达“Leader 必须先启动,且 Worker 要通过稳定 DNS 名称找到它”这种拓扑关系。你通常要手写 init container、readiness probe、并手动创建 Service,这些都重复且容易出错。
JobSet 通过 replicatedJobs + 自动 headless Service,让你用大约 20 行 YAML 就能描述该架构,而不是 200 行手工配置。
其他常见的 Leader-Worker 场景
- 机器学习训练:Parameter Server(Leader)存模型参数,Worker 计算梯度并回传更新
- 爬虫系统:Coordinator(Leader)管理待爬 URL 队列,Worker 执行页面下载与解析
- 视频转码:Orchestrator(Leader)切分视频片段,Worker 并行处理不同时间段编码
- 基因测序分析:Master(Leader)协调序列比对任务,Worker 执行计算密集型比对算法
在 Kubernetes 中运行 Leader-Worker 架构
如果用原生 Job,你需要手动管理 Service、协调启动顺序,并在任一 Job 失败时自行处理清理与重启逻辑:
apiVersion: batch/v1
kind: Job
metadata:
name: worker-job
spec:
template:
spec:
containers:
- name: worker
image: bash:latest
command: ["bash", "-xc", "sleep 1000"]
env:
- name: LEADER_HOST
value: "leader-service"
restartPolicy: Never
---
apiVersion: batch/v1
kind: Job
metadata:
name: leader-job
spec:
template:
spec:
containers:
- name: leader
image: bash:latest
command: ["bash", "-xc", "echo 'Leader is running'; sleep 1000"]
restartPolicy: Never
---
apiVersion: v1
kind: Service
metadata:
name: leader-service
spec:
selector:
job-name: leader-job
ports:
- port: 8080
如果使用 JobSet:不仅可一次定义 Leader 与 Worker,还可通过 failurePolicy 对特定角色执行失败策略(例如 Leader 失败时直接 FailJobSet 终止任务)。
apiVersion: jobset.x-k8s.io/v1alpha2
kind: JobSet
metadata:
name: failjobset-action-example
spec:
failurePolicy:
maxRestarts: 3
rules:
# 当 leader Job 失败时,JobSet 会立刻标记为失败
- action: FailJobSet
targetReplicatedJobs:
- leader
replicatedJobs:
- name: leader
replicas: 1
template:
spec:
# 设为 0,确保任一 Pod 失败时 Job 立即失败
backoffLimit: 0
completions: 2
parallelism: 2
template:
spec:
containers:
- name: leader
image: bash:latest
command:
- bash
- -xc
- |
echo "JOB_COMPLETION_INDEX=$JOB_COMPLETION_INDEX"
if [[ "$JOB_COMPLETION_INDEX" == "0" ]]; then
for i in $(seq 10 -1 1)
do
echo "Sleeping in $i"
sleep 1
done
exit 1
fi
for i in $(seq 1 1000)
do
echo "$i"
sleep 1
done
- name: workers
replicas: 1
template:
spec:
backoffLimit: 0
completions: 2
parallelism: 2
template:
spec:
containers:
- name: worker
image: bash:latest
command:
- bash
- -xc
- |
sleep 1000
🔍DNS 发现示例: Worker Pod 可通过 leader-0.failjobset-action-example.default.svc.cluster.local 直接连接 Leader,无需额外定义 Service。
对照表:原生 Job vs JobSet
| 对比维度 / 工作流程 | 原生 Job | JobSet |
|---|---|---|
| 1. 角色拓扑定义 | 单一角色;需为 Leader 与 Worker 分别写 YAML 并手工管理 | 支持多角色;单一 Manifest 内定义多组角色与副本 |
| 2. 网络服务与发现 | ❌ 需手动创建 Service 与 DNS,并注入环境变量 | ✅ 自动创建 Headless Service,通过稳定 DNS 直连 |
| 3. 启动顺序协调 | 需写 init container/readiness probe 保证 Leader 先启动 | ✅ 内建协同启动,自动处理多角色依赖关系 |
| 4. 失败处理策略 | ❌ 各 Job 独立失败;需自写脚本检测并重启关联 Job | ✅ 全局/定向 FailurePolicy;支持 Leader 失败触发全局失败 |
| 5. 监控与清理 | 需分别查看多个 Job;删除时要逐个清理 Job/Service | ✅ 单对象管理;统一查看并自动回收关联资源 |
| 6. 开发与维护成本 | 高(维护多份 YAML 与关联脚本) | 低(声明式 YAML) |
| 7. 生态支持 | Kubernetes 核心 API | SIG Scheduling 官方子项目(可与 Kueue 集成做高级调度) |
开始使用 JobSet
0. 安装前置条件(Prerequisites)
- 一个运行中的 Kubernetes 集群,版本位于最近三个次要版本范围内。
- 资源要求:集群中至少有一个节点具备 2+ CPU 与 512+ MB 内存,用于运行 JobSet Controller Manager(在某些云环境中,默认节点规格可能不足)。
- 已安装并配置好
kubectl(或选择使用helm)。
1. 安装 JobSet CRD 与 Controller
你可以根据需求选择 kubectl 或 Helm 安装。建议在生产环境固定版本(例如 v0.10.1)以保障稳定性。
方法 A:使用 kubectl
VERSION=v0.10.1
kubectl apply --server-side -f https://github.com/kubernetes-sigs/jobset/releases/download/$VERSION/manifests.yaml
方法 B:使用 Helm
VERSION=v0.10.1
helm install jobset oci://registry.k8s.io/jobset/charts/jobset \
--version $VERSION \
--create-namespace \
--namespace=jobset-system
2. 编写 JobSet Manifest
按需编写 YAML,定义 ReplicatedJob 组、副本数,以及对应 Pod Template(可参考上文 Leader-Worker 示例)。
下面是一个简化版 jobset.yaml 模板:
apiVersion: jobset.x-k8s.io/v1alpha2
kind: JobSet
metadata:
name: coordinator-example
spec:
# label and annotate jobs and pods with stable network endpoint of the designated
# coordinator pod:
# jobset.sigs.k8s.io/coordinator=coordinator-example-driver-0-0.coordinator-example
coordinator:
replicatedJob: driver
jobIndex: 0
podIndex: 0
replicatedJobs:
- name: workers
template:
spec:
parallelism: 4
completions: 4
backoffLimit: 0
template:
spec:
containers:
- name: sleep
image: busybox
command:
- sleep
args:
- 100s
- name: driver
template:
spec:
parallelism: 1
completions: 1
backoffLimit: 0
template:
spec:
containers:
- name: sleep
image: busybox
command:
- sleep
args:
- 100s
3. 部署到集群
kubectl apply -f jobset.yaml
4. 监控与排障
部署后可用以下命令跟踪任务进度:
- 查看 JobSet 整体状态:
kubectl get jobsets - 查看指定 JobSet 的详细事件与状态:
kubectl describe jobset <name> - 观察 JobSet 创建出的底层 Jobs:
kubectl get jobs -l jobset.sigs.k8s.io/jobset-name=<name>
总结
JobSet 的设计标志着 Kubernetes 从“无状态微服务编排”走向“复杂分布式拓扑”这一更成熟阶段。它不是替代原生 Job,而是精准补齐多节点、异构角色(如 Leader-Worker、Parameter Server)协同运行的关键拼图。
通过这层声明式协同层,工程团队终于可以摆脱繁琐且脆弱的启动顺序、DNS 发现与失败重试脚本。特别是在配合 Kueue 进行 GPU/TPU 等昂贵算力资源高级调度时,JobSet 让你专注描述“目标状态”,而不是手工拼接控制逻辑。
如果你正在 Kubernetes 上构建下一代 AI 训练平台或大规模数据处理流水线,JobSet 是不可或缺的核心基础设施。
