深入解析 Amazon EKS CNI 插件在快速扩缩过程中的 IP 分配难题
试想这样一个场景:一个看似普通的星期五下午,生产环境突然爆出严重事故,背后牵出一连串复杂的 IP 分配失败,甚至足以把整个 Kubernetes 集群拖进故障。这篇文章会深入拆解 CNI 插件配置里那些容易被忽略的风险,还原一次几乎演变成灾难的扩缩事件,并整理出避免 IP 耗尽的实战建议。接下来我会带你一起看清 failed to assign an IP address 这类错误背后到底发生了什么,以及怎样让 EKS 基础设施尽量避开同样的问题。
概述
深入解析 Amazon EKS CNI 插件在快速扩缩过程中的 IP 分配难题
├── 事情是怎么开始的
│ └── 难以判断的错误
├── AWS VPC CNI 插件
│ ├── Amazon VPC CNI 的 IP 分配流程
│ ├── 关键配置参数
│ └── 为什么 warm pool 设得太低,会在突发扩缩时出问题
│ ├── API 节流问题
│ └── 性能瓶颈
├── 真实观察与事故分析
│ ├── GitHub issue 分析(warm pool 设置过低)
│ └── 生产故障案例(子网可用 IP 不足)
├── 大多数文档没有讲清楚的事
│ ├── 先看懂这条消息(no free IP available in the prefix)
│ ├── 等一下,原来有 IP 冷却期?
│ └── Pod IP 分配与 hydration
├── 冷却期带来的挑战
│ └── WARM_IP_TARGET 的误区
├── 长期方案
│ ├── VPC 设计改进
│ ├── 快速扩缩的推荐配置
│ ├── Prefix Delegation 模式
│ ├── 监控与可观测性
│ └── FAQ
├── 关键结论
├── 总结
└── 致谢
事情是怎么开始的
某个星期五下午,一位经理给我发来消息:
Hey, I have a critical case that needs your help.
不到 30 分钟,我就开始接手一个已经引起管理层关注的高优先级案例。客户的 EKS 生产环境正在发生事故,而我在和相关人员同步情况的同时,也被安排参加当天稍晚的客户会议。
会前我先查看了内部 COE 报告和沟通记录。问题很快变得清晰起来:客户在一次大规模部署期间撞上了 IP 分配限制。虽然当时我还没法仅凭快速浏览就立刻锁定根因,但已经可以确定,这是一类与 CNI IP 分配行为相关的 IP 耗尽问题。
也正因为这次机会,我得以深入研究一个非常有意思的生产案例。快速扩缩需求和 CNI 插件行为交织在一起,让这起事件成了一个很典型的案例,也带出了不少 EKS IP 资源管理上的关键经验。下面就是我们最终整理出来的结论。
难以判断的错误
最初的事故由 InsufficientFreeAddressesInSubnet 引发。这个报错本身很直白,意思就是子网里已经没有足够的空闲 IP 可供 CNI 插件分配。客户于是尝试调整 WARM_IP_TARGET,希望借此“释放”更多 IP。但这种做法并不一定对症。如果子网本身已经耗尽,只改 WARM_IP_TARGET 并不能解决根本问题。真正需要弄清楚的,是 CNI 插件如何分配 IP,以及应该怎样组合调整相关配置。
在多次修改参数之后,客户一度把 WARM_IP_TARGET 切回默认值 0,子网 IP 耗尽的情况暂时有所缓解;但从 Kubernetes event 和日志系统来看,IP 分配错误依旧持续出现:
add cmd: failed to assign an IP address to container
当出现 "add cmd: failed to assign an IP address to container" 这条消息时,表示 Amazon VPC CNI 插件无法为 Pod 分配新的 IP。常见原因包括插件本身没有正常工作,或者像这次一样,节点上已挂载的 Elastic Network Interface(ENI)已经没有可用 IP 了。CNI 插件依赖挂在 EC2 实例上的 ENI 及其 secondary IP 来给 Pod 分配地址;一旦这些 IP 被用完,新 Pod 就拿不到 IP,于是就会报这个错。
在我加入调查之前,我的同事已经从日志里找到了下面这两行:
Get free IP from prefix failed no free IP available in the prefix - 172.28.15.192/ffffffff
Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.15.192/ffffffff
他当时的判断是:客户之所以出现 IP 分配错误,是因为 Prefix Delegation 需要的连续 /28 块不够,因此建议先修正 IP 块分布,以避免这类错误。
但我重新看完内部报告后发现,客户其实根本还没有启用 Prefix Delegation。更关键的是,我快速翻了代码后才意识到,这条消息本身并不是真正意义上的错误。这个误解非常常见,也确实误导过不少人,后面我会详细解释。
说到这里,我反而更想知道底层到底发生了什么。会上团队给我看了一段日志,我注意到 warm pool 并没有积极补充 IP,而日志里透露出来的状态也不像只是单纯“IP 用完”那么简单。结合我过去处理类似案例的经验,我怀疑问题很可能出在 CNI 分配 IP 的节奏和业务扩缩模式之间的相互影响。于是我请对方提供日志采集结果,开始往下分析。
不过在进入日志细节之前,先快速过一遍 AWS VPC CNI 插件是怎么工作的。
AWS VPC CNI 插件
AWS VPC CNI(Container Network Interface)插件,是 Amazon EKS 集群中负责 Pod 网络的核心组件。它负责 Pod 的 IP 分配、ENI 管理,以及 Pod 在 EC2 实例上的网络连通。要排查 IP 分配问题,或者优化集群性能,先理解它的架构和运行方式非常重要。
Amazon VPC CNI 插件的核心,主要由两个组件协同完成 Pod 网络配置:
- CNI Binary:位于
/opt/cni/bin/aws-cni,当节点上有 Pod 新增或删除时,由 kubelet 调用 - ipamd Daemon:常驻本地的 IP Address Management daemon,负责管理 ENI,并维护可立即使用的 warm pool IP
AWS VPC CNI 插件是按照 Kubernetes 的 Container Networking Interface(CNI)规范实现的。虽然规范里定义了多种操作,但对这里最关键的是两个:ADD 和 DEL。
- ADD:创建 Pod 时,kubelet 会调用 CNI binary 发起
ADD,请求建立网络。binary 会和ipamd通信,请求 IP 并完成 Pod 网络接口配置。 - DEL:删除 Pod 时,kubelet 会调用 CNI binary 发起
DEL。binary 会通知ipamd释放 IP,并清理相关网络配置。
Amazon VPC CNI 的 IP 分配流程
当 Pod 被调度到某个节点后,CNI binary 会通过 gRPC 向 ipamd 申请 IP。ipamd 负责管理节点上已挂载的 ENI 及其 IP,同时维护一个 warm pool,保证节点手边始终有一批可以立刻分配给 Pod 的 IP。如果缓存里已经没有可用 IP,这次请求就会失败,进而触发 IP 分配错误。
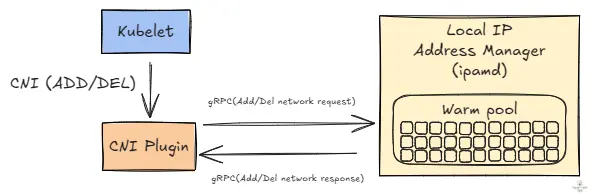
为什么 AWS VPC CNI 插件需要 warm pool
warm pool 的作用非常关键,因为它能提前准备好 IP,降低 Pod 启动延迟,也能在流量平稳时分散 EC2 API 调用,减少扩缩瞬间被节流的风险,并为突发扩缩预留缓冲空间。
如果你希望 Kubernetes Pod 在 AWS 环境中拥有独立的私有 IP,并保留原生 VPC 网络性能,那么 CNI 插件就会直接利用 VPC 和 EC2 的原生网络能力。每个 Pod 都依赖 Elastic Network Interface(ENI) 参与网络通信,因此既可以选择性访问 Internet,也能访问 RDS、DynamoDB 之类的 AWS 私有资源。Pod 使用的私有 IP,则来自 ENI 上分配的 secondary IP。
但这种设计也有代价。因为 CNI 插件必须在 ENI 层处理 IP 分配,所以 warm pool 该怎么维护、什么时候补 IP,都会变得更复杂。每种实例规格都有自己的 ENI 数量上限和每张 ENI 可分配的 IP 数量上限,而新增 ENI 或分配 IP 又必须通过 EC2 API 完成;这些 API 不仅可能被节流(通常表现为 RequestLimitExceeded),延迟也可能从 1 秒到数分钟不等。在快速扩缩场景里,这些因素会叠加在一起。
warm pool 的意义就在于先把一批 IP 准备好,等 Pod 真正需要时直接拿来用。这样不仅能缩短 Pod 启动时间,也能降低扩缩过程中的 IP 分配失败概率。同时,它还能把 ENI 挂载请求摊到平时去做,避免在大量 Pod 同时启动时把 EC2 API 顶出一个尖峰。
ENI 限制示例:m5.large
节点上的 IP,是从已挂载到实例的 ENI 中按块获取的。每张 ENI 可以挂多少个 IP,取决于实例规格。以 m5.large 为例,它支持 3 张 ENI,每张最多可分配 10 个 IP1。理论上总共有 30 个 IP,但这并不代表节点就能运行 30 个 Pod。
节点可运行的最大 Pod 数,会按照下面的公式计算:
- 每张 ENI 的第一个 IP 不会分给 Pod,因为 primary IP 会保留给 EC2 主机
- 再额外加上 2 个使用 host network 的 Pod(AWS CNI 和 kube-proxy)
(该实例规格的 ENI 数量 * (每张 ENI 的 IP 数量 - 1)) + 2
对于 m5.large,计算结果如下2:
(3 * (10 - 1)) + 2 = 29 pods maximum
这也解释了为什么 EKS 在这个实例规格上的默认 maxPods 是 29。做节点容量规划和 warm pool 配置时,先弄清这些硬限制非常重要。需要注意的是,如果启用了 Prefix Delegation,这个计算方式就不再适用。
另外,即使我们知道 m5.large 最多能跑 29 个 Pod,也不代表 AWS VPC CNI 插件应该一次性分配 29 个 IP。实际生产里,一台节点多数时候并不会真的跑到这么满,所以没有必要过早把子网里的 IP 都占住。CNI 插件本来就是按需逐步分配 IP。
理解这一点后,就更容易看出插件真正要做的事情:它是在“尽量保留子网里的可用 IP”和“维持 warm pool 让 Pod 能快速启动”之间取得平衡。
关键配置参数
AWS VPC CNI 插件有几个关键配置参数,会直接影响 IP 分配行为和 warm pool 的管理方式。这些参数之间会互相影响,重点是找到平衡点:设得太低,扩缩时容易分不到 IP;设得太高,则可能额外占用一些私有 IP。不过如果你的 Pod 本来就运行在专用子网里,这种额外占用通常不是大问题。下面逐一展开。
WARM_ENI_TARGET(默认值:1)
- 定义:希望节点额外保留多少张已挂载但尚未使用的 ENI,每张 ENI 都会带来一整组可供 Pod 使用的 IP
- 行为:默认值为 1,表示会多保留一张完整 ENI 的 IP 容量作为 warm pool
- 影响:相比按 IP 数量维持 warm pool,这种方式可以减少 EC2 API 调用次数,但会一次性占用更大批量的 IP
WARM_IP_TARGET
- 定义:希望在所有已挂载的 ENI 上,总共额外保留多少个可立即使用的 warm IP
- 灵活性:可以直接指定 IP 数量,比按 ENI 数量控制更细
- 覆盖行为:如果同时设置
MINIMUM_IP_TARGET,它们会覆盖WARM_ENI_TARGET的行为
MINIMUM_IP_TARGET
- 定义:节点启动时至少要预先分配多少个 IP,系统会为了达到这个目标提前挂载 ENI
- 用途:相当于给节点的 IP 容量设一个基础盘,避免节点刚起来时可用 IP 太少
- 建议:通常建议略高于单节点预期承载的 Pod 数量
为什么 warm pool 设得太低,会在突发扩缩时出问题
当 Pod 在短时间内被快速调度时,如果 warm pool 相关参数设置得太低,就很容易出现 IP 分配失败。原因是 warm pool 里的 IP 太少,Pod 之间会开始竞争;而插件如果此时才同步调用 EC2 API 去补 ENI 或 IP,速度通常跟不上 Pod 创建的节奏。
API 节流问题
如果 WARM_ENI_TARGET 或 WARM_IP_TARGET 设置得过低,CNI 插件就不会预留足够的 warm IP。一旦大量 Pod 突然启动,插件只能同步调用 EC2 API 去挂新 ENI 或分配新 IP,这不仅会带来延迟,也可能被 EC2 服务节流。
性能瓶颈
warm target 偏低的集群,常见的瓶颈就是 IP 分配速度赶不上 Pod 创建速度。下面这些情况会让问题更加明显:
- EC2 API 在高频调用下触发限流
- 多个节点同时请求挂载 ENI,而创建并挂载一张新的 ENI 最多可能需要 10 秒
- IP 冷却期带来的影响(后面会详细展开)
真实观察与事故分析
这类错误在快速扩缩场景下尤其麻烦,因为短时间内会有大量 Pod 同时在集群各节点上被调度。很多生产环境在几分钟内部署 100 个以上的 Pod 时,都会碰到这个问题,相关故障复盘里也有记录。
GitHub issue 分析(warm pool 设置过低)
GitHub issue #28043 记录了这样一个案例:集群在几分钟内部署超过 100 个 Pod 时,会偶发 IP 分配失败,而且日志里出现的正是我前面提到的那组消息:
"Get free IP from prefix failed no free IP available in the prefix""Unable to get IP address from CIDR: no free IP available in the prefix"
表面上看,这像是子网里的 IP 快用完了;但实际上子网仍然有 80% 以上的空闲 IP。真正耗尽的,是 ENI 内某些 prefix 中可以继续利用的 IP,这才导致了分配失败。
生产故障案例(子网可用 IP 不足)
Neon 团队分享的一篇生产事故分析4,则更完整地说明了这类问题能严重到什么程度。事故发生前,他们使用的是 AWS CNI 默认配置,也就是 WARM_ENI_TARGET=1,而 WARM_IP_TARGET 没有额外设置。在一次扩缩事件中:
- 每个子网已经分配了大约 3.7k 到 3.9k 个 IP,但整体使用率只有约 50%
- 所有子网合计已分配约 12,200 个 IP,而总可用 IP 只有 12,273 个,整体分配率达到 99%
- 某些节点虽然 CPU 和内存已经满载,但仍然占着 IP,导致这些 IP 实际上无法再被新工作负载利用
- 新节点表面上看似还有空间,却拿不到足够的 IP,因此无法顺利承接新的 Pod
大多数文档没有讲清楚的事
先看懂这条消息(no free IP available in the prefix)
和客户工程团队一起排查日志时,我注意到这条消息反复出现。它看起来和 Prefix Delegation 模式下常见的 InsufficientCidrBlocks 很像,如果不仔细对照日志,很容易把排查方向带偏。
在 Prefix Delegation 模式下,插件会给节点分配 /28 CIDR block;但这里看到的 mask 是 /32,也就是 ffffffff。这说明当前仍处于“单个 IP 分配模式”,而不是 prefix delegation。这个差异非常关键,因为两种模式对应的根因和处理方式完全不同。
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.15.192/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.15.192/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.119/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.119/ffffffff"}
...
补充一下,当子网里没有足够连续的 CIDR block 可以给 Prefix Delegation 使用时,更典型的报错其实是:InsufficientCidrBlocks: The specified subnet does not have enough free cidr blocks to satisfy the request。可参考:Increase the available IP addresses for your Amazon EKS node - Amazon EKS
刚开始我自己也被这条日志绕进去过。但翻过代码之后,我才确认:它指向的并不是子网层面的 IP 耗尽,而是 CNI 插件内部 IP 管理流程里的一个状态。
- 这类 debug 消息来自 CNI 插件内部的 IP 分配流程。插件会扫描节点上各张 ENI 的
AvailableIPv4Cidrs,查找尚未分配的 IP;一旦找到,就把这些可用 secondary IP 记录到 datastore 中(可参考:AssignPodIPv4Address)。 - 当 getUnusedIP 在某个特定 CIDR block 里找不到任何可用 IP 时,就会打印这组消息。
从代码来看,这种情况大致有两个原因(同样可参考 getUnusedIP):
- 它会先检查 datastore 中,是否存在任何已经脱离 cooldown period 且尚未被分配的 IP。只要找到,就返回第一个可用 IP。
- 如果 cooldown 检查之后仍然找不到可用 IP,它才会尝试在该 CIDR 范围内生成新的 IP。但这里日志里的 mask 是
ffffffff,也就是十六进制表示的/32。换句话说,这个 CIDR 实际上只是一个单独的 IP,而不是一个真正可展开的子网段。
因此,这条日志出现时,其实是在表示某个特定 CIDR block 中的 IP 已经全部被分配出去,或者还在 cooldown 中,迫使 CNI 插件继续扫描其他 ENI,甚至去申请新的 ENI。下面这组日志就能看出,插件在遇到这种情况时会持续去其他 ENI 寻找可用 IP:
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.119/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.119/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:1291","msg":"Found a free IP not in DB - 172.28.12.25"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Returning Free IP 172.28.12.25"}
...
等一下,原来有 IP 冷却期?
分析到这里,我才意识到 CNI 插件内部其实有一个很容易被忽略的机制:IP 冷却期(参数:IP_COOLDOWN_PERIOD)。当某个 Pod 释放 IP 后,这个 IP 不会立刻重新分配,而是会先进入 30 秒冷却期。这个设计原本是为了避免 IP 冲突,但在快速扩缩场景里,反而可能让 IP 分配问题更明显。
在分析客户 issue 和日志时,我注意到:当 Pod churn 很高、而 warm IP target 又设得很低时,这个 cooldown 机制和 warm pool 补充速度不足会形成一种很糟的组合。就我看到的案例而言,明明子网里还有足够空间,多台节点却仍然同时出现 IP 分配失败。
从 debug 日志中,也确实能看到 cooldown 机制在起作用。日志会记录当前 IP 状态,包括总 IP 数、已分配 IP 数,以及处于 cooldown 状态的 IP 数。这也解释了为什么“总 IP 看起来还够”,但其中一部分短时间内其实并不能重新分配:
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"ipamd/ipamd.go:661","msg":"IP stats - total IPs: 100, assigned IPs: 95, cooldown IPs: 5"}
问题在于,这些处于 cooldown 的 IP 似乎仍然会被计入可用 IP。于是,在 WARM_ENI_TARGET=0 且 WARM_IP_TARGET=0 这样的场景里,系统只有等到所有 IP 都真的被认为用尽之后,才会去补更多 IP:
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"ipamd/ipamd.go:661","msg":"IP stats - total IPs: 100, assigned IPs: 100, cooldown IPs: 0"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"ipamd/ipamd.go:679","msg":"Starting to increase pool size"}
...
虽然这看起来像是我发现了一个没多少人真正解释清楚的细节,但毕竟我不是 CNI maintainer,所以还是找了 EKS 团队一起确认。到这里,我们大致可以把 CNI 插件为 Pod 分配 IP 的流程整理成下面这样:
- 当 Pod 被调度到节点时:
- [Kubernetes scheduler] 将 Pod 分配到节点
- [Kubelet] 启动 Pod,并调用 CNI 插件(
ADDrequest) - [ipamd] 从 warm pool 分配一个 IP
- [ipamd] 如果 warm pool 里没有可用 IP,就通过 EC2 API 新增 ENI 或分配新的 secondary IP
- 当 Pod 从节点上移除时:
- [Kubernetes API] 将 Pod 状态更新为
Terminating - [Kubelet] 终止 Pod,并调用 CNI 插件清理 network namespace(
DELrequest) - [ipamd] 释放该 Pod 的 IP,并标记为未分配
- [ipamd] 该 IP 进入 30 秒 cooldown period(
IP_COOLDOWN_PERIOD) - [ipamd] cooldown 结束后,这个 IP 才重新变为可分配状态
- [Kubernetes API] 将 Pod 状态更新为
IP_COOLDOWN_PERIOD 默认最少就是 30 秒,而且这个值不是随意设定的。系统必须给 kube-proxy 之类的网络代理留出足够时间,让它们更新节点上的 iptables 规则,确保那些曾被注册成有效 endpoint 的 IP 不会过早被重复利用。5
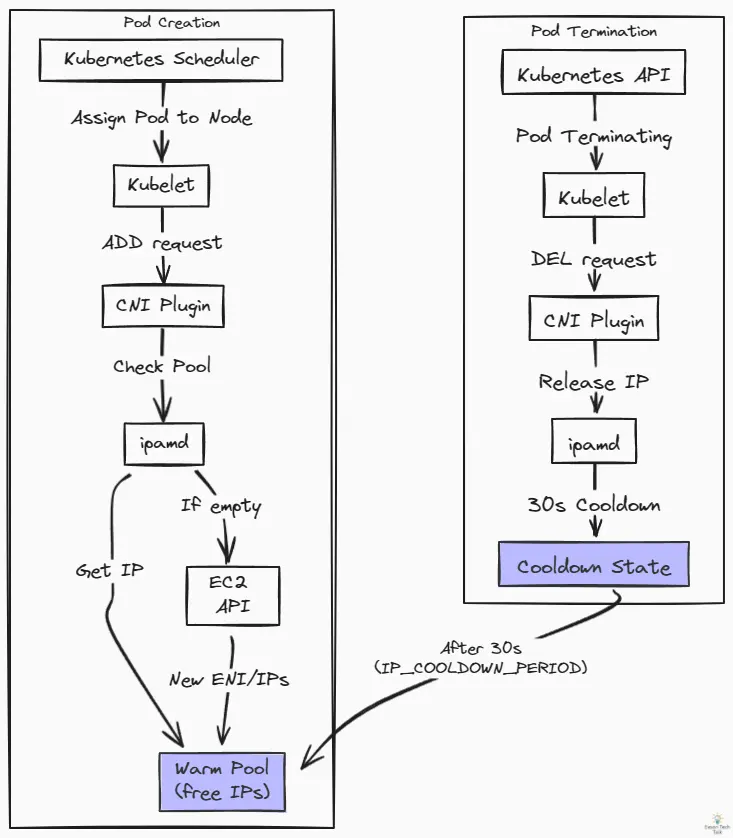
Pod IP 分配与 hydration
在和 EKS 团队确认之后,我了解到 Pod IP 分配和 IP hydration 实际上是并发执行的。也就是说,新 Pod 在不断创建并索取 IP 的同时,hydration 流程也在后台同步运行,尝试把 warm pool 补回到配置目标。不过在快速扩缩事件中,IP 被消耗的速度可能会快过 hydration 的补充速度,所以即使系统整体行为符合设计,也仍然会暂时出现 IP 分配失败。
Pod IP 分配
当 Pod 在 CNI ADD 流程中请求 IP 时,插件会先检查 warm pool 里是否有预先分配好的地址。如果有,就立即分配;如果没有,就会返回 "no available IP addresses":
{"level":"error","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"DataStore has no available IP/Prefix addresses"}
{"level":"info","ts":"2024-02-21T20:39:45.367Z","caller":"rpc/rpc.pb.go:863","msg":"Send AddNetworkReply: IPv4Addr: , IPv6Addr: , DeviceNumber: -1, err: AssignPodIPv4Address: no available IP/Prefix addresses"}
周期性 IP Hydration
- CNI 插件会每 5 秒 检查一次当前可用 IP 是否达到配置目标:
WARM_IP_TARGET:期望保留的 warm IP 数量WARM_ENI_TARGET:期望保留的 warm ENI 数量
- 如果可用 IP 低于目标,插件就会:
- 先尝试在已有 ENI 上分配更多 secondary IP
- 如果还不够,再给节点挂新的 ENI
- 在快速扩缩过程中,由于 hydration 速度慢于 IP 分配,Pod 可能会先收到
"ip address not available"之类的错误,直到新 IP 补上
- 这个补充过程本身需要时间,因为背后依赖 EC2 API 调用。这也是为什么 warm pool 如此重要,它能:
- 降低 Pod 启动延迟
- 让扩缩过程更平滑
- 避免在突发流量下出现 IP 耗尽
下面这张图可以帮助理解 Pod IP 分配与 hydration 之间的关系。CNI 插件里的 ipamd 会同时管理这两个流程。
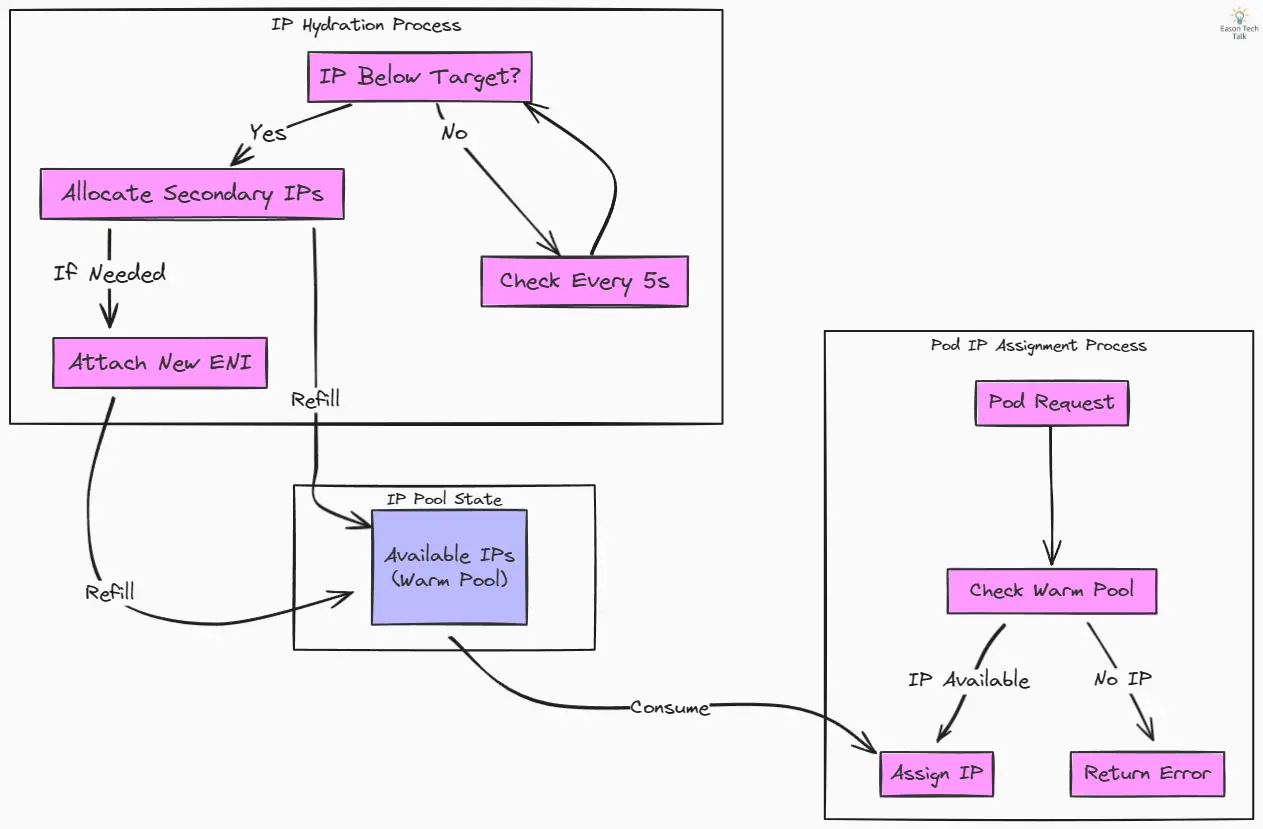
这张图把整体关系表达得很直观:warm pool 很像令牌桶里的那个桶,一边被 Pod IP 分配流程持续消耗,一边又由 hydration 流程不断补充。hydration 的职责是把水位维持在目标区间,而 Pod IP 分配流程则从里面即时取用 IP。
重要说明: 处于 cooldown period 的 IP,在 CNI 插件眼里仍然会被算作“available”。这样设计是为了避免系统一看到 IP 进入 cooldown 就立刻去补新的 IP,从而制造更多 EC2 API 调用。对大多数场景来说,这种做法能让资源利用保持平衡,因为默认 30 秒后,这批 IP 就会重新变成可用状态。
冷却期带来的挑战
这次分析让我意识到一个文档里不太容易直接看出来的问题:cooldown period 会带来一种相当隐蔽的副作用。Pod 被快速创建、删除、再创建时,刚释放的 IP 虽然“账面上存在”,但因为仍在 cooldown,所以暂时无法重新使用。这种行为在自动化部署或高频滚动替换的场景里特别容易放大。
其中最棘手的一类情况,就是 Pod churn rate 很高,也就是 Pod 频繁创建和销毁,而 WARM_ENI_TARGET 又设置得很低。此时,每次有 Pod 被移除后,节点都可能出现长达 30 秒无法让新 Pod 启动的窗口。原因主要有三点:
- IP 一旦解除分配,就会先进入 30 秒 cooldown
- cooldown 中的 IP 仍然会被计入 warm target
- 系统误以为 warm IP 足够,但实际上没有任何可以立即使用的 IP
在 Neon 的事故4 中,工程团队也曾多次调整 WARM_IP_TARGET,试图解决 Pod 启动失败和 IP 耗尽问题。但从生产现场的观察来看,当 Pod 已经启动失败时再去修改 CNI 参数,并不能真正解决问题。单纯调整 WARM_IP_TARGET,并没有触及底层容量约束。
WARM_IP_TARGET 的误区
CNI 插件支持 WARM_IP_TARGET,用于定义所有已挂载 ENI 上应当额外保留多少个可立即使用的 warm IP。它的本意,是告诉插件:warm pool 至少应维持在某个水平。
乍看之下,从 ipamd 释放一些 IP 似乎能节省资源、避免过度消耗子网 IP;但这种策略实际上很容易制造一种“看起来还有 IP,实际上根本不能用”的错觉。因为处于 cooldown 的 IP 仍然会计入 warm target,插件就不会主动补新的 IP,即便这些 IP 此刻根本不能重新分配。结果就是在高 Pod churn 场景下,尤其是 Pod 一边删除、一边创建时,IP 分配失败反而更容易发生。
当你把 WARM_IP_TARGET 设得很低,甚至设为 0,同时又搭配:
WARM_IP_TARGET: 0MINIMUM_IP_TARGET: 0WARM_ENI_TARGET: 0
ipamd 就会变得非常被动,只有在节点上彻底没有可用 IP 时,才会去补新的 IP。这意味着只有满足以下两个条件时,它才会开始补 IP:
- 节点上的所有 IP 都已经分配给 Pod
- 节点在过去 30 秒内没有任何 Pod 终止,因此没有 IP 处于 cooldown 状态
此外,如果你本来就预期会有突发流量,并且会同时跑很多 Pod,那么把这些值设得太低,还会增加撞上 EC2 API 限流的风险,最终甚至更容易把子网 IP 提前消耗掉。这类设置只适合在确实非常需要节省 IP、且 Pod churn 极低的情况下谨慎使用。
换句话说,WARM_IP_TARGET 更适合小型集群,或者 Pod churn 非常低的集群。另外也建议把 MINIMUM_IP_TARGET 设置得略高于你预期每个节点要承载的 Pod 数量。6
长期方案
VPC 设计改进
如果你希望集群能长期支撑可持续扩缩,可以从架构层面考虑以下几件事:
- 更大的 CIDR block:在设计 VPC 时就把未来增长空间预留进去
- 使用 secondary CIDR:如果子网里的 IP 快不够了,可以利用 VPC secondary CIDR 来扩展子网容量。这会引入不可路由的地址范围(RFC 6598:
100.64.0.0/10),用于放置新的工作负载子网 - 为 Kubernetes Pod 工作负载使用独立子网:把 Pod IP 和其他 VPC 资源使用的地址空间分开,既能减少冲突,也能让 IP 管理、容量规划和网络故障排查更简单
快速扩缩的推荐配置
如果你想降低快速扩缩时的瓶颈和 IP 分配错误,建议这样做:
- 提高 warm pool 目标:对于已经出现扩缩问题的集群,建议把
WARM_ENI_TARGET至少设为 2。如果你预计会在短时间内扩到数百个 Pod:- 先确认你的实例规格每张 ENI 可以提供多少 IP
- 视情况增加节点数量,或者提高
WARM_ENI_TARGET
- 配置
MINIMUM_IP_TARGET:建议略高于单节点预期的 Pod 数量6
示例
在没有启用 Prefix Delegation 的情况下,m5.large 每个节点最多有 10 个 IP,并支持 3 张 ENI,因此单节点最多能运行 29 个 Pod。如果你希望在 30 秒内,以较理想的性能突发创建 100 个 Pod,建议至少准备:
- EC2 实例数量(
m5.large):4 台 WARM_ENI_TARGET:3
通过这种方式提前把节点扩好后,你会得到 116 个可用 IP(29 个 IP x 4 个节点),足以支撑这种快速部署需求。
Prefix Delegation 模式
在默认情况下,IP 分配能力仍然受限于各个 EC2 实例规格所支持的 ENI 数量。如果想进一步提升可用 IP 数,AWS VPC CNI 插件还支持 Prefix Delegation 模式,也就是改为使用 subnet prefix,而不是逐个分配独立 IP。
对于需要更高 Pod 密度的集群,启用 Prefix Delegation 后,可用 IP 数量会显著增加。当你设置 ENABLE_PREFIX_DELEGATION=true 时,VPC CNI 会分配 /28(也就是 16 个 IP)的 IPv4 prefix,而不再是单个 IP。
如果场景是快速扩缩,还可以提高 WARM_PREFIX_TARGET,让系统即使只使用了现有 prefix 中的一个 IP,也会预先再补一个完整的 /28 prefix block。需要注意的是,如果同时设置了 WARM_IP_TARGET 和 MINIMUM_IP_TARGET,它们会覆盖 WARM_PREFIX_TARGET。
重要: Prefix Delegation 模式要求子网中存在连续的 /28 块,并且还要满足其他前置条件。在启用 Prefix Delegation 的情况下,把 WARM_PREFIX_TARGET 设为 0,或者同时把 WARM_IP_TARGET 和 MINIMUM_IP_TARGET 设为 0,都是不受支持的。
监控与可观测性
AWS VPC CNI 插件在每个节点上都提供了一个本地 metrics endpoint,可用于观察 IP 分配、ENI 状态以及插件健康情况。你可以通过 http://localhost:61678/metrics 获取 Prometheus 格式的指标。
从这个 endpoint 中可以看到的重要指标包括:
- awscni_assigned_ip_addresses:当前已经分配给 Pod 的 IP 数量
- awscni_eni_allocated:当前节点上已挂载的 ENI 数量
- awscni_eni_max:该实例规格允许挂载的最大 ENI 数量
- awscni_total_ip_addresses:插件当前管理的总 IP 数量
// get ipamd metrics
root@ip-192-168-188-7 bin]# curl http://localhost:61678/metrics
# HELP awscni_assigned_ip_addresses The number of IP addresses assigned
# TYPE awscni_assigned_ip_addresses gauge
awscni_assigned_ip_addresses 46
# HELP awscni_eni_allocated The number of ENI allocated
# TYPE awscni_eni_allocated gauge
awscni_eni_allocated 4
# HELP awscni_eni_max The number of maximum ENIs can be attached to the instance
# TYPE awscni_eni_max gauge
awscni_eni_max 4
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 5.6955e-05
go_gc_duration_seconds{quantile="0.25"} 9.5069e-05
go_gc_duration_seconds{quantile="0.5"} 0.000120296
go_gc_duration_seconds{quantile="0.75"} 0.000265345
go_gc_duration_seconds{quantile="1"} 0.000560554
go_gc_duration_seconds_sum 0.03659199
go_gc_duration_seconds_count 211
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 20
...
虽然插件本身提供了 introspection endpoint,但如果想尽早发现 IP 分配风险,还是应该把完整监控体系搭起来。下面两个方案都很实用:
- AWS CNI Metrics(Grafana dashboard):可以观察 ENI 挂载速率、IP 分配模式、扩缩表现以及 warm pool 状态
- CNI Metrics Helper(CloudWatch metrics):可以把 ENI 挂载率和 IP pool 利用率推送到 CloudWatch
FAQ
会不会太浪费 Private IP?
把 warm pool 参数调高,确实会更积极地占用 private IP,但大多数情况下,这个代价远小于生产事故带来的损失:
- 不会额外收费:AWS 不会对 private IP 地址本身单独收费
- 能避免可预防的 outage:相比省下少量 IP,更值得优先避免部署中断和生产事故
- 提高扩缩可靠性:在突发流量下,集群更有可能稳定扛住压力
在大型 EKS 集群中,低峰期保留一批暂时空闲的 IP,确实是一种取舍;但比起一味追求 private IP 利用率,提前规划足够大的 CIDR 和专用子网,收益通常更高。更何况,由 CNI 插件分配出来的 private IP 本身并不会产生额外费用。
关键结论
把 AWS VPC CNI 插件和 IP 分配问题拆开来看,最重要的实践建议可以浓缩成以下几点:
- 主动做容量规划:子网和 CIDR block 最好至少按预估需求的两倍来规划,这个缓冲对长期可持续扩缩非常关键。如果真的遇到 IP 耗尽,也还能通过新增子网、引入 secondary CIDR 等方式降低对生产环境的影响
- 优化 warm pool:更高的
WARM_ENI_TARGET往往能带来更好的扩缩稳定性和性能。维持足够的 warm pool,并在需要时预先多挂几张 ENI,会有几个明显好处:- 减少 EC2 API 调用:降低扩缩过程中被节流的概率
- 加快 Pod 启动:Pod 可以直接拿到 IP,无需等待新 ENI 挂载完成
- 提升集群稳定性:避免快速扩缩时出现连锁失败
- 监控必不可少:必须把指标监控做好,才能尽早发现并防止 IP 耗尽
总结
add cmd: failed to assign an IP address to container 这个错误,本质上是 EKS 集群扩缩过程中的一个关键瓶颈,它会直接影响应用部署和服务可用性。想在快速扩缩期间维持集群稳定,关键就在于理解 WARM_ENI_TARGET、WARM_IP_TARGET 和 MINIMUM_IP_TARGET 三者之间的相互作用。
默认的 CNI 配置对很多场景来说已经足够,但如果你的生产环境本来就会频繁快速扩缩,就应该提前调整这些参数。比如把 WARM_ENI_TARGET 提高到 2 以上,再配合合理的 IP target,通常就能提供足够缓冲,降低 IP 分配失败的概率。
随着容器化工作负载规模越来越大、形态越来越复杂,这些 CNI 配置细节对平台稳定性的影响只会越来越明显。把 IP 分配规划做好,最终换来的就是更少的 outage、更高的部署成功率,以及更稳定的整体集群表现。
致谢
特别感谢 Neon Engineering 团队分享宝贵的生产经验和第一手观察。他们在大规模 EKS 部署中的实践,以及实际反馈,帮助我验证了文中的很多判断,也让这篇文章能够加入更多有价值的实战视角。
我也很感谢 EKS networking 团队,以及我的同事 Maicon 和 Robin,在调查和厘清这起复杂问题的过程中提供帮助。他们的专业与投入,是这次找出根因并整理出可行方案的关键。
这篇分析之所以既有深度又能落到实践,很大程度上也得益于大家愿意提供详尽的技术反馈,并分享来自生产环境的一手经验。
文中的建议主要来自我的个人观察和实际经验。如果你也遇到过类似问题,欢迎分享你的经验,或者直接到 GitHub issue 参与讨论。这篇关于 EKS CNI IP 分配问题的深入分析,源自我亲自参与调查的一起真实事件。这段经历不仅加深了我对 AWS CNI 内部机制的理解,也促使我把这些经验整理成文。希望这些内容能帮助你在 Amazon EKS 上构建更可靠的基础设施。
参考资料
