EKS Managed Node Group: 解決 PodEvictionFailure 錯誤
自上篇提及 2019 年 EKS 釋出了新的 API 支援 Managed Node Groups (託管式工作節點) 1 和簡介 Ec2SubnetInvalidConfiguration 的錯誤排查後,本篇內容將進一步探討在執行 Managed Node Group 升級過程遭遇的 PodEvictionFailure 錯誤。
PodEvictionFailure 錯誤是在 EKS 進行節點組升級時會遇到的常見錯誤之一,通常是使用 AWS Console 介面、aws eks update-nodegroup-version 命令或是 UpdateNodegroupVersion API 呼叫時產生。本文將進一步分析這個錯誤的原因、常見情境以及解決方法。
如何確認該問題
要檢查 EKS Managed Node Groups 是否存在 PodEvictionFailure 錯誤,可以透過 EKS Console 或是 AWS CLI 命令確認是否存在任何錯誤。例如,透過點擊 Cluster 底下的 Compute 頁籤 > 點擊 Node groups 進入到節點組的詳細頁面後,可以檢查 Update history 頁籤相關的升級事件是否存在相關的錯誤訊息:
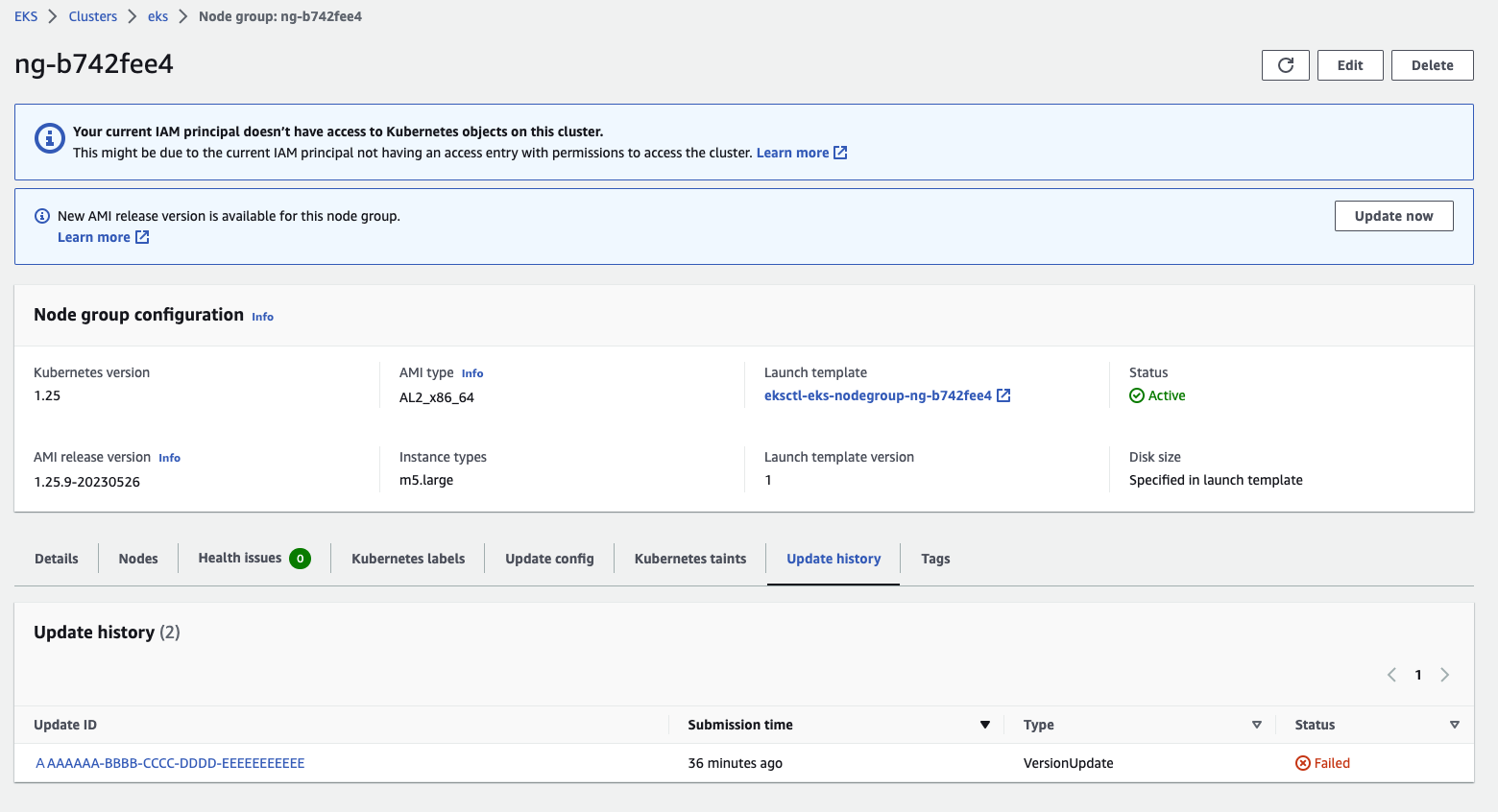
再進一步點擊個別的升級事件,便可以進一步看到詳細資訊和錯誤:
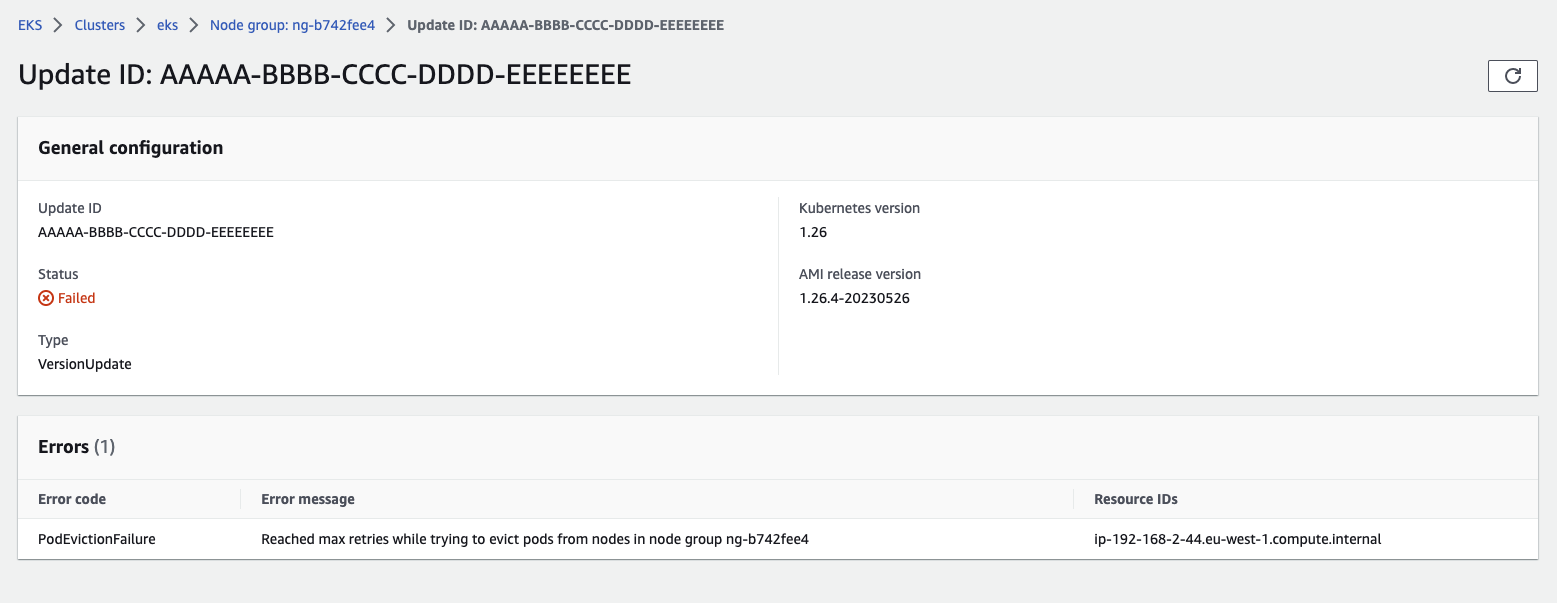
根據文件提到 EKS Managed Node Group 的升級流程 2,如果升級或是新建節點超過 15-20 分鐘後卡住,很可能是某些原因使得工作節點在運作時存在一些問題,過一段時間後,通常有機會透過這些資訊進一步排查可能的原因。以下是使用 AWS CLI 命令的範例:
$ aws eks list-updates --name <CLUSTER_NAME> --nodegroup-name <NODE_GROUP_NAME>
{
"updateIds": [
"AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEEE"
]
}
$ aws eks describe-update --name <CLUSTER_NAME> --nodegroup-name <NODE_GROUP_NAME> --update-id AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEEE
{
"update": {
"id": "AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEEE",
"status": "Failed",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "ReleaseVersion",
"value": "1.26.4-20230526"
}
],
"createdAt": "2023-06-03T17:19:38.068000+00:00",
"errors": [
{
"errorCode": "PodEvictionFailure",
"errorMessage": "Reached max retries while trying to evict pods from nodes in node group <NODE_GROUP_NAME>",
"resourceIds": [
"ip-192-168-2-44.eu-west-1.compute.internal"
]
}
]
}
}
上述範例為在升級時嘗試停用 Pod 超出重試的次數導致失敗,並且該次升級為 Failed 狀態。
常見情境和發生原因
Pod Disruption Budget (PDB)
Pod Disruption Budget (PDB) 是 Kubernetes 內的一個資源物件,用於確保在進行維護、升級、回滾等操作時,對於特定部署的可用性不會被破壞 3。
PDB 通常用在設定 Pod 的最小 (可用) 運行數量,當進行維護操作時,Kubernetes 會確保在目前集群中 Pod 的運行數量不會低於這個數字。這樣可以確保在進行維護等操作時,服務的可用性不會受到影響或是中斷 (Pod)。
以下是一個 PDB 的範例:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: my-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: my-app
在這個範例中,我們設定了一個 PDB,最小可用數量為 2 個,選擇器為 app=my-app。這表示在進行維護等操作時,Kubernetes 會確保至少有 2 個符合選擇器的 Pod 可用。
PDB 的設定可以幫助您在進行維護等操作時確保 Pod 的可用性,同時也可以減少可能出現的 PodEvictionFailure 錯誤。在設計應用程式時,建議您考慮使用 PDB 來確保應用程式的可用性。
PodEvictionFailure 和 PDB 之間的關係
PodEvictionFailure 錯誤通常是由於 EKS 無法在要更新的工作節點上節點上停用 Pod 引起。在進行 Managed Node Group 升級替換操作時,如果目前要被更新的節點上運行的目標 Pod 的運行數量低於 PDB 中設定的最小值,那麼 Kubernetes 就會拒絕刪除 Pod,在這種情況下,就可能會觸發升級過程產生的 PodEvictionFailure 錯誤。例如,以下的環境中部署了一個 Kubernetes Deployment (nginx-deploymnet),並且在目前環境中的唯一節點 ip-192-168-2-44.eu-west-1.compute.internal 上運行:
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default pod/nginx-deployment-ff6774dc6-dntfm 1/1 Running 0 45m 192.168.7.16 ip-192-168-2-44.eu-west-1.compute.internal
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS
default deployment.apps/nginx-deployment 1/1 1 1 49m nginx
同時,該環境中設定了以下 PodDisruptionBudget 資源 (這個 nginx-deployment 所有 Pod 存在 app=nginx 標籤):
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
通常在執行更新或是替換節點過程時,我們通常會需要將節點標記為不可調度以及停用在上面運行的應用,在 Kubernetes 中,提供了 kubectl drain 這類方法支援這個操作 4。一旦執行 kubectl drain 將節點設定為維護狀態時,它會觸發 Kubernetes Scheduler 將節點上的 Pod 進行重新調度。
此外,在重新調度之前,kubectl drain 命令會將節點標記為不可調度,這樣新的 Pod 就不會被調度到該節點上。同時,已在節點上運行的 Pod 會被逐一停用。但在違反 PodDisruptionBudget 情況下,這樣的操作很可能會失敗,例如,以下就是一個在存在 PDB 時無法正確停用的範例:
$ kubectl drain ip-192-168-2-44.eu-west-1.compute.internal --ignore-daemonsets --delete-emptydir-data
node/ip-192-168-2-44.eu-west-1.compute.internal already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/aws-node-n9lc5, kube-system/kube-proxy-lwxcb
evicting pod kube-system/coredns-6866f5c8b4-r96z8
evicting pod default/nginx-deployment-ff6774dc6-dntfm
evicting pod kube-system/coredns-6866f5c8b4-h296r
pod/coredns-6866f5c8b4-r96z8 evicted
pod/coredns-6866f5c8b4-h296r evicted
evicting pod default/nginx-deployment-ff6774dc6-dntfm
error when evicting pods/"nginx-deployment-ff6774dc6-dntfm" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod default/nginx-deployment-ff6774dc6-dntfm
error when evicting pods/"nginx-deployment-ff6774dc6-dntfm" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod default/nginx-deployment-ff6774dc6-dntfm
error when evicting pods/"nginx-deployment-ff6774dc6-dntfm" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
...
Deployment 允許 (容忍) 在存在污點 (Taint) 的節點上部署
在 Kubernetes 中,Taints(污點)和 Tolerations(容忍)是用於控制 Pod 能否被調度到特定節點的機制。Taints 是對節點的標記,表示節點具有某些特定的限制或要求。而 Tolerations 則是由 Pod 定義,用於告訴 Kubernetes 這個 Pod 可以容忍哪些節點的 Taints,進而允許或阻止 Pod 被調度到符合條件的節點上。5
然而,不正確的 tolerations 設定很可能使得在預期進行替換的節點中,仍持續調度應用程式到節點上,例如,以下範例直接忽略了在 Node 關聯的 Taint 設定:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
...
template:
...
spec:
containers:
- name: nginx
image: nginx
tolerations:
- operator: "Exists"
...
如同前面提到,在重新調度之前,kubectl drain 命令會將節點標記為不可調度,這樣新的 Pod 就不會被調度到該節點上。執行這項操作時,Kubernetes 也會替節點設定 node.kubernetes.io/unschedulable:NoSchedule 的污點:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-2-44.eu-west-1.compute.internal Ready,SchedulingDisabled <none> 126m v1.25.9-eks-0a21954
$ kubectl describe node
Name: ip-192-168-2-44.eu-west-1.compute.internal
...
Taints: node.kubernetes.io/unschedulable:NoSchedule
但在使用上述 tolerations 設定時,對應應用程式的調度行為會直接忽略這項設定,例如,以下就是在 Node 執行 kubectl drain 仍持續執行 Pod 調度的過程:
NAME READY STATUS RESTARTS AGE IP NODE
nginx-deployment-6876484bcc-h28sn 1/1 Running 0 25s 192.168.9.175 ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-h28sn 1/1 Terminating 0 38s 192.168.9.175 ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-kbgw6 0/1 Pending 0 0s <none> ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-kbgw6 0/1 ContainerCreating 0 0s <none> ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-kbgw6 1/1 Running 0 2s 192.168.18.140 ip-192-168-2-44.eu-west-1.compute.internal
對於 EKS Managed Node Group 升級操作的行為來說,該節點並為完全停用 Pod 且屬於未清空的狀態,使得更新過程發生 PodEvictionFailure 錯誤。
Pod 本身存在錯誤
如果並非上述問題導致,則可能指出 Pod 基於某些原因無法正常關閉,例如:應用程式與 NFS 互動但執行操作卡在 I/O 行為、網路問題或資源不足 (像是 CPU 負載過高使得系統無法反應) 等原因導致。
要先確定出錯 Pod 的狀態和原因,您可以使用以下命令來查看詳細的 Pod 狀態或是相關的紀錄日誌來確定問題的原因:
$ kubectl describe pod
$ kubectl logs <POD_NAME>
解決方法和相關步驟
Pod Disruption Budget (PDB)
要確認是否因為 Pod Disruption Budget (PDB) 影響升級,可以透過以下命令確認目前有的 PDB 設定:
kubectl get pdb --all-namespaces
如果有開啟 EKS Control Plane Logging (稽核記錄),也可以透過 CloudWatch Log Insight 功能篩選並檢查是否存在任何相關的失敗事件,
- 在
Cluster>Logging(記錄) 標籤下,選擇Audit(稽核) 可以直接開啟 Amazon CloudWatch Console。 - 在 Amazon CloudWatch 主控台中,選擇 Logs (日誌)。然後,選擇 Log Insights (日誌洞察) 對 EKS 產生的稽核紀錄檔進行篩選
以下為相關查詢範例:
fields @timestamp, @message
| filter @logStream like "kube-apiserver-audit"
| filter ispresent(requestURI)
| filter objectRef.subresource = "eviction"
| display @logStream, requestURI, responseObject.message
| stats count(*) as retry by requestURI, responseObject.message
透過上述檢視稽核紀錄,可以進一步確認在停用 Pod 事件中是否存在任何因為 Pod Disruption Budget 影響的具體資訊:
如果是因為 PDB 導致升級失敗,可以修改或是移除 PDB 後,再次嘗試執行升級:
# Edit
$ kubectl edit pdb <PDB_NAME>
# Delete
$ kubectl delete pdb <PDB_NAME>
錯誤的 Tolerations 設定
前面提到不正確的 tolerations 設定,很可能使得在預期進行替換的節點中,仍持續調度應用程式到節點上。可以透過修正對應部署的設定解決這項問題:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
...
template:
...
spec:
containers:
- name: nginx
image: nginx
tolerations: <---- 修正設定
- operator: "Exists"
...
採用強制更新 (Force update)
預設情況下,EKS Managed Node Group 的升級會採用 Rolling update (滾動更新) 方法,這個選項在升級過程會遵守 Pod Disruption Budget (PDB) 設定。若因為 PDB 導致無法正確停用,升級過程將會失敗。
如果因為前述 PDB 或其他原因無法正確升級,也可以透過在升級過程選擇 Force update (強制更新) 進行升級,這個選項會在升級過程忽略 PDB 設定。無論 PDB 問題是否出現,都會強制節點重新啟動以進行更新。

以下為使用 AWS CLI 的範例:
$ aws eks update-nodegroup-version --cluster-name <CLUSTER_NAME> --nodegroup-name <NODE_GROUP_NAME> --force
以下為使用 eksctl 的範例:
$ eksctl upgrade nodegroup --cluster <CLUSTER_NAME> --name <NODE_GROUP_NAME> --force-upgrade
總結
在這篇內容中,我們提到了升級 EKS Managed Node Group 時遇到 PodEvictionFailure 錯誤的常見情境和發生原因,並且提出相關的解決方法,例如:
- 檢查 PodDisruptionBudget (PDB) 設定是否有誤,如果是 PDB 導致升級失敗,可以修改或是移除 PDB 後再次執行升級。
- 檢查 Tolerations 設定是否有誤。錯誤的 Tolerations 設定很可能使得在預期進行替換的節點中,仍持續調度應用程式到節點上,需修正對應部署的設定。
最後,如果以上方法仍無法解決問題,可以採用強制更新 (Force update) 進行升級。此選項會在升級過程中忽略 PDB 設定,並強制節點重新啟動以進行更新6 7。
透過遵循上述的解決方法和相關步驟,希望能幫助在閱讀這篇內容的你更有方向的排查並且解決這個錯誤。
參考資源
