管理 Kubernetes Webhook 故障:從診斷到解決方案
在現代雲原生架構中,Kubernetes Admission Webhook 扮演著至關重要的角色,允許我們擴充和自定義 Kubernetes 的行為,而無需修改核心代碼。然而,這種強大的功能也帶來了潛在的風險 — 當 webhook 發生故障時,可能會對整個叢集造成嚴重影響,甚至導致系統性的服務中斷。
作為一名在容器技術領域的實踐者,我曾協助處理過多起因 webhook 故障導致的生產環境事件。這些經驗讓我深刻認識到,了解 webhook 的運作機制、掌握故障診斷技巧,以及實施適當的監控策略,對於維護 Kubernetes 叢集的穩定性至關重要。因此,本篇內容將著重於分享從診斷到解決方案的全面指南,包含實際案例分析和預防措施。透過這些內容,希望能夠幫助更多 Kubernetes 管理員在面對 webhook 相關問題時,能夠迅速找到根本原因並採取適當的解決方案。
本篇內容同時也摘要總結分享至 Kubernetes Community Day (KCD) Taipei 2025 演講 1。
Kubernetes Admission Webhook 概述
Kubernetes Admission Control 是 Kubernetes 中的一種機制,允許在資源被儲存到 etcd 之前攔截和修改 API 請求。而 Kubernetes Admission Webhook 則屬於動態擴充機制的一部分,允許開發者自定義和擴充 Kubernetes 的控制邏輯。這種機制透過 HTTP 回調的方式,使外部服務能夠參與到資源管理決策中,在資源被持久化到 etcd 之前進行驗證或修改。
Kubernetes 提供了許多原生內建的 Admission 插件,可以透過 Kubernetes API Server 的 --enable-admission-plugins 參數啟用,例如:
kube-apiserver --enable-admission-plugins=NamespaceLifecycle,LimitRanger...
例如,在本文撰寫時,最新版本為 Kubernetes 1.33,預設啟用了以下 Admission 插件:
CertificateApprovalCertificateSigningCertificateSubjectRestrictionDefaultIngressClassDefaultStorageClassDefaultTolerationSecondsLimitRangerMutatingAdmissionWebhookNamespaceLifecyclePersistentVolumeClaimResizePodSecurityPriorityResourceQuotaRuntimeClassServiceAccountStorageObjectInUseProtectionTaintNodesByConditionValidatingAdmissionPolicyValidatingAdmissionWebhook
為了擴增 Kubernetes 的功能性,額外的 MutatingAdmissionWebhook 以及 ValidatingAdmissionWebhook 為 Kubernetes 動態擴充 Kubernetes API 的關鍵機制。它們能夠在資源被 Kubernetes API Server 處理的過程中攔截請求,執行額外的邏輯,例如驗證資源規格是否符合組織政策,或者自動修改資源配置以符合特定需求。
在實際應用中,Admission Webhook 被廣泛用於多個場景:
- 鏡像安全掃描:確保只有經過安全掃描的容器鏡像才能部署到叢集
- 命名空間管理:自動為資源添加特定的標籤或註釋
- Sidecar 注入:自動注入監控和日誌收集的 sidecar 容器
許多開源專案依賴 webhook 來提供功能,如 Istio(用於 sidecar 注入)、Cert-manager(自動化憑證管理)、Kyverno 和 Gatekeeper(策略控制)等。
假設你需要根據 Pod 的標籤來自動加上對應的註解。比如說,當一個 Pod 帶有標籤 app=nginx 時,你需要自動加上一個叫做 foo 的註解,其值為 stack。但如果 app 標籤的值是 mongo,則註解的值應該是不同的。這本質上需要一個查找表來將 X 值映射到 Y 值,這通常不太容易實現。而使用 Kyverno,不僅可以取代這些客製化的註解工具,還可以利用原生的 Kubernetes 資源如 ConfigMap 來定義這個對照表,並動態套用相對應的值。這裡的動態操作,便涉及了 Kubernetes Admission Webhook 的運作機制。以下是一個 Kyverno 規則示例,它可以根據 Pod 的標籤動態地添加註解:
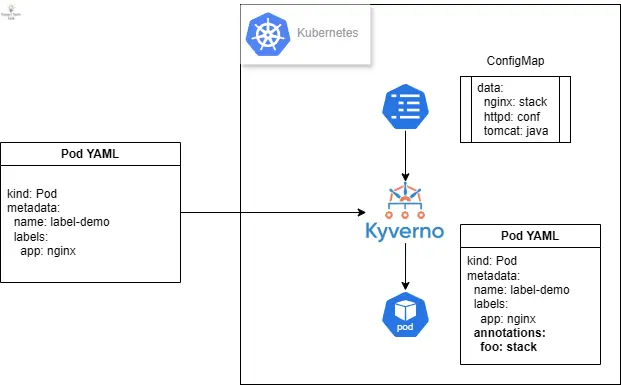
首先,我們需要一個作為參考表的 ConfigMap。這就是一個標準的 ConfigMap,其中每個鍵 (Key) 都有對應的值 (Value),形成標籤和註解之間的映射關係。
apiVersion: v1
kind: ConfigMap
metadata:
name: resource-annotater-reference
namespace: default
data:
httpd: conf
nginx: stack
tomcat: java
接下來,我們需要一個包含變更邏輯的策略。以下是一個範例,它做了幾件事。首先,它使用了 Kyverno 中稱為 context 的概念來提供對現有 ConfigMap 的引用。其次,它使用 JMESPath 表達式 來執行參考並插入名為 foo 的註解值。
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: resource-annotater
spec:
background: false
rules:
- name: add-resource-annotations
context:
- name: LabelsCM
configMap:
name: resource-annotater-reference
namespace: default
preconditions:
- key: "{{request.object.metadata.labels.app}}"
operator: NotEquals
value: ""
- key: "{{request.operation}}"
operator: Equals
value: "CREATE"
match:
resources:
kinds:
- Pod
mutate:
overlay:
metadata:
annotations:
foo: "{{LabelsCM.data.{{ request.object.metadata.labels.app }}}}"
最後,讓我們用一個簡單的 Pod 定義來測試。在這個定義中,輸入是一個名為 app 的標籤,其值為 nginx。
apiVersion: v1
kind: Pod
metadata:
labels:
app: nginx
name: mypod
spec:
automountServiceAccountToken: false
containers:
- name: busybox
image: busybox:1.28
args:
- "sleep"
- "9999"
建立這資源後,檢查 Pod 註解就會看到 Kyverno 根據傳入的 app 標籤值,寫入了從 ConfigMap 中找到的對應值。
$ kubectl get po mypod -o jsonpath='{.metadata.annotations}' | jq
{
"foo": "stack",
"policies.kyverno.io/patches": "add-resource-annotations.resource-annotater.kyverno.io: removed /metadata/creationTimestamp\n"
}
Kubernetes Admission Webhook 工作流程
在了解基礎的 Kubernetes Admission Webhook 概念後,讓我們來看看 Webhook 的工作流程。在典型的 API 請求處理過程中,當用戶或系統組件向 Kubernetes API Server 發送請求時,該請求會經過一系列的處理步驟。首先,請求會通過認證(Authentication)和授權(Authorization)檢查,確保請求者有權執行該操作。接著,請求會進入准入控制(Admission Control)階段,其中包括 Mutating Webhook 和 Validating Webhook 的處理。
Admission Webhook 主要分為兩種類型:
- 驗證型 (Validating) Webhook:負責驗證資源請求是否符合特定規則,可以接受或拒絕請求,但不能修改請求內容。
- 修改型 (Mutating) Webhook:除了可以驗證請求外,還能修改請求內容,例如新增預設值或注入額外配置。
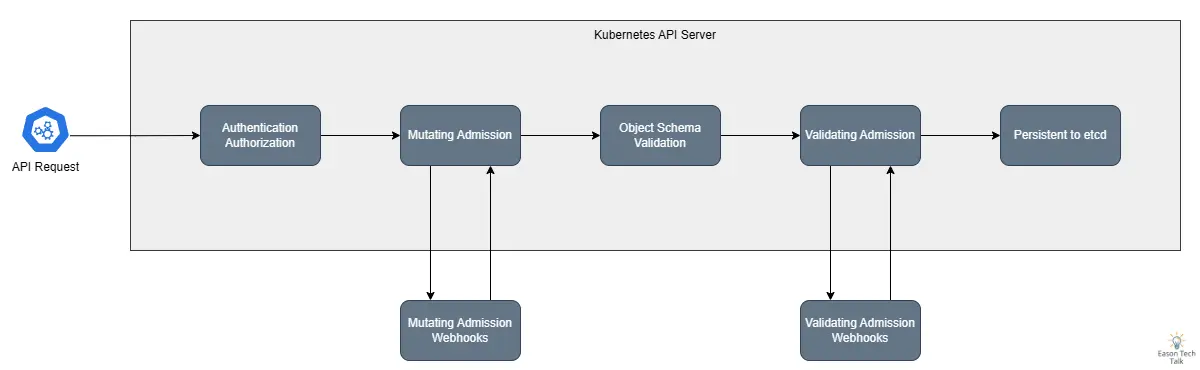
在 API 伺服器的請求處理流程中,當一個請求到達時,首先會進行身份驗證和授權檢查,然後會依序經過所有已註冊的 Mutating Webhook。這些 Webhook 可以對請求進行修改,例如新增標籤、註解或是注入 Sidecar 容器。完成修改後,請求會進入 Validating Webhook 階段,在這個階段中,Webhook 只能驗證請求是否符合特定規則,但不能進行任何修改。最後,如果所有的 Webhook 都通過,請求才會被永久保存到 etcd 中。
在這背後,API Server 將會主動呼叫並且觸發對應的 Webhook 服務。例如,當使用者嘗試創建 Pod 資源時,API Server 將會請求 Webhook 服務進行驗證或修改。Webhook 服務收到請求後,會根據預定的邏輯處理該請求,並返回結果給 API Server。API Server 根據 Webhook 的回應決定是否繼續處理該請求,或者返回錯誤給使用者。這種請求與回應的循環構成了 Webhook 的基本工作流程。
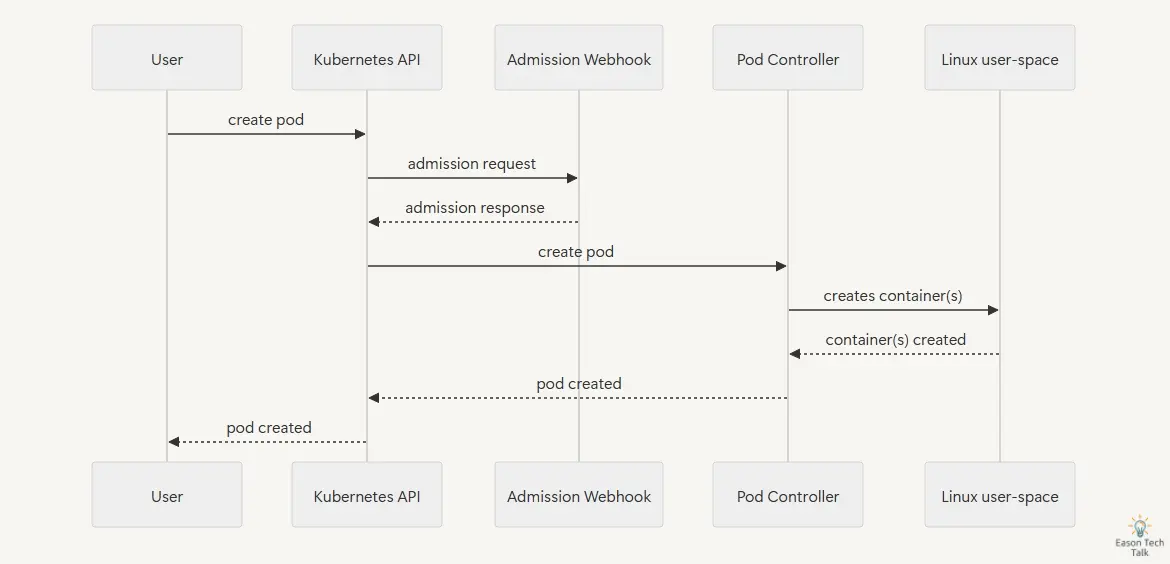
其中,作為 Webhook 服務的應用程式需要返回 AdmissionReview 類型的回應資料 (200 HTTP status code),資料結構為 Content-Type: application/json。這個回應告訴 API Server 該請求是被允許還是被拒絕,以及可能需要的修改內容。以下是兩個典型的 AdmissionReview回應範例,分別代表接受和拒絕請求的情況。
接受請求的 webhook 回應示例:
{
"apiVersion": "admission.k8s.io/v1",
"kind": "AdmissionReview",
"response": {
"uid": "<value from request.uid>",
"allowed": true
}
}
拒絕請求的 webhook 最小回應示例 (Validating webhook):
{
"kind": "AdmissionReview",
"apiVersion": "admission.k8s.io/v1",
"response": {
"uid": "9e8992f7-5761-4a27-a7b0-501b0d61c7f6",
"allowed": false,
"status": {
"message": "pod name contains \"offensive\"",
"code": 403
}
}
}
那 Kubernetes API Server 是如何具體得知在執行特定 API 操作時,要觸發哪個 Webhook 呢?這就輪到 MutatingWebhookConfiguration 和 ValidatingWebhookConfiguration 這兩類資源定義來發揮作用了。這兩類配置告訴 API Server 哪些 Webhook 服務應該在什麼情況下被觸發。這些配置資源包含了 Webhook 的 URL、驗證選項、匹配規則以及錯誤處理策略等重要信息。
以下展示了一個基本的驗證型 webhook (Validating webhook),它會:
- 監控所有 Pod 的建立操作
- 通過指定的服務發送請求到 webhook 服務 (webhook-service)
- 如果 webhook 服務失敗,根據 failurePolicy 決定是否允許請求通過
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingWebhookConfiguration
metadata:
name: pod-policy.example.com
webhooks:
- name: pod-policy.example.com
rules:
- apiGroups: [""]
apiVersions: ["v1"]
operations: ["CREATE"]
resources: ["pods"]
clientConfig:
service:
name: webhook-service
namespace: default
path: "/validate"
failurePolicy: Fail
自定義 Mutating webhook 的設定也十分類似,以下用 AWS Load Balancer Controller 實現自動注入 Pod readinessGates 的功能為例,其設定如下:
$ kubectl describe MutatingWebhookConfiguration/aws-load-balancer-webhook
Name: aws-load-balancer-webhook
Namespace:
Labels: app.kubernetes.io/instance=aws-load-balancer-controller
app.kubernetes.io/name=aws-load-balancer-controller
app.kubernetes.io/version=v2.7.2
API Version: admissionregistration.k8s.io/v1
Kind: MutatingWebhookConfiguration
Webhooks:
Admission Review Versions:
v1beta1
Client Config:
Service:
Name: aws-load-balancer-webhook-service
Namespace: kube-system
Path: /mutate-v1-pod
Port: 443
Failure Policy: Fail
Match Policy: Equivalent
Name: mpod.elbv2.k8s.aws
Namespace Selector:
Match Expressions:
Key: elbv2.k8s.aws/pod-readiness-gate-inject
Operator: In
Values:
enabled
Object Selector:
Match Expressions:
Key: app.kubernetes.io/name
Operator: NotIn
Values:
aws-load-balancer-controller
Rules:
API Versions:
v1
Operations:
CREATE
Resources:
pods
...
這個 AWS Load Balancer Controller 的 MutatingWebhookConfiguration 展示了幾個關鍵設定項:
- Client Config:定義 API Server 與 webhook 服務的通信方式:
- 指向
kube-system命名空間中的aws-load-balancer-webhook-service - 使用
/mutate-v1-pod路徑處理 Pod 變更 - 透過 443 端口進行安全通信
- 指向
- Failure Policy:設為
Fail,表示 webhook 無回應時 API Server 會拒絕請求。這是重要的安全措施,但可能在故障時阻礙資源創建。 - 命名空間選擇器 (Namespace Selector):僅處理帶有標籤
elbv2.k8s.aws/pod-readiness-gate-inject: enabled的命名空間中的資源。這提供精細控制,讓管理員可選擇需要此功能的命名空間。 - 物件選擇器 (Object Selector):排除標籤為
app.kubernetes.io/name: aws-load-balancer-controller的資源,避免 webhook 處理 AWS Load Balancer Controller 本身,防止循環依賴問題。 - 規則定義 (Rules):指定僅處理 Pod 資源的建立 (
CREATE) 操作,進一步限制其作用範圍。
這個設定明確界定了 webhook 的行為邊界,確保它只在需要的地方生效(特定標籤的命名空間中的新建 Pod)。
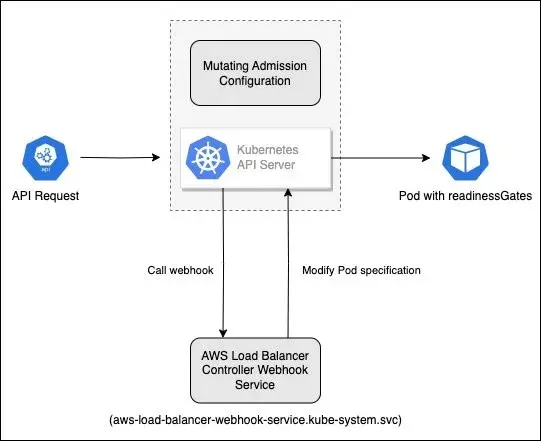
以下是具體 API 請求經由 API Server 觸發和更改 Pod 規格的流程:
- 用戶建立標記了
elbv2.k8s.aws/pod-readiness-gate-inject: enabled的命名空間 - 當在此命名空間中建立 Pod 時,API Server 會檢查 MutatingWebhookConfiguration
- API Server 發現 Pod 建立操作符合 webhook 規則,發送請求到 AWS Load Balancer Controller webhook 服務 (借助 kube-dns 解析
aws-load-balancer-webhook-service.kube-system.svc對應的服務 Cluster IP 地址) - Webhook 服務收到請求後,檢查 Pod 規格並注入所需的 readinessGates 配置
- API Server 接收修改後的 Pod 規格,將其保存到 etcd 中
從以上的討論中,我們可以看到 Kubernetes Admission Webhook 的工作流程相當複雜,牽涉到多個組件之間的通信和協作。當使用者或系統發起一個請求創建資源時,該請求需要經過一系列的檢查和處理才能最終被執行。這個過程中的任何環節出現問題,都可能導致整個工作流程受阻,進而影響叢集的正常運作。
常見的 Webhook 故障模式
基於實際案例分析,我總結了幾種常見的 webhook 故障模式:
1. 網路連接問題
網路連接問題是 webhook 最常見的故障之一。當叢集內的網路通信出現問題時,可能導致 webhook 服務無法正常響應 API Server 的請求。例如,以下是一個典型的錯誤信息,表明 API Server 無法找到 webhook 服務:
error when patching "istio-gateway.yaml": Internal error occurred: failed calling webhook "validate.kyverno.svc-fail": failed to call webhook: Post "https://kyverno-svc.default.svc:443/validate/fail?timeout=10s": context deadline exceeded
這些問題可能源於 DNS 解析失敗、網路延遲過高、CNI 錯誤,或是服務發現機制失效等情況。以 Amazon EKS 環境為例,以下是一個常見 Webhook 服務在雲原生環境中的資料流,它揭示了 API Server 如何通過雲端基礎設施連接到 webhook 服務:
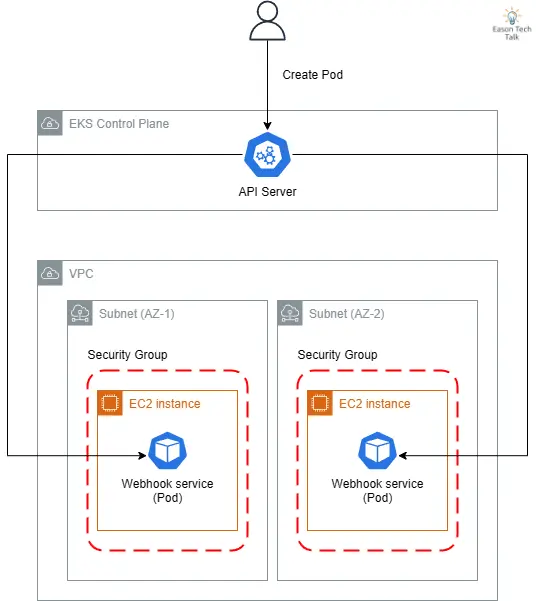
- API Server 位於 AWS 管理的 EKS Control Plane,而 webhook 服務則運行在客戶 VPC 的 EC2 實例上
- 為實現高可用性,webhook 服務通常部署在不同可用區 (AZ-1, AZ-2) 的子網路中
- 安全群組限制了進出 webhook 服務的網路流量
此架構中可能出現的網路連接問題包括:子網路路由錯誤、安全群組規則限制、DNS 解析失敗 (CoreDNS)、系統層網路問題 (例如 kube-proxy 無法正確工作設定 iptables 或 ipvs 規則影響到目標 Pod) 等,任何一環出現問題都可能導致 webhook 調用失敗,進而影響整個叢集的正常運作。在故障診斷時,這些網路路徑都是需要檢查的重點。
2. 證書過期和 TLS 問題
證書過期和 TLS 問題是另一個常見的故障點。當 webhook 的 TLS 證書過期或配置不當時,API Server 將無法與 webhook 服務建立安全連接。這種情況特別棘手,因為證書即將過期的問題往往不易被及時發現。
舉例來說,在我協助客戶案例的經驗中,AWS Load Balancer Controller 過去的版本曾因常遇到證書過期,而導致新的 Ingress 資源無法創建。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedDeployModel 53m (x9 over 63m) ingress (combined from similar events): Failed deploy model due to Internal error occurred: failed calling webhook "mtargetgroupbinding.elbv2.k8s.aws": Post "https://aws-load-balancer-webhook-service.kube-system.svc:443/mutate-elbv2-k8s-aws-v1beta1-targetgroupbinding?timeout=30s": x509: certificate has expired or is not yet valid: current time 2022-03-03T07:37:16Z is after 2022-02-26T11:24:26Z
為了解決此問題,最新版本在使用 Helm 安裝時,會透過內建的 genCA 方法自動產生有效期超過十年的自簽憑證。
若你的集群環境採用 Cert-manager 等套件來輪替 TLS 證書,則需要特別注意憑證更新機制是否正常運作,並確保在憑證到期前有充足的處理時間,實施自動化的憑證輪替機制,以減少人為干預的需求。
3. 延遲和性能下降 (Control Plane)
控制平面層延遲和性能下降是另一個重要的故障來源。當 Kubernetes Master Node 服務響應時間過長,或者服務本身處理能力下降時,可能導致請求超時。這種情況通常發生在大規模負載過高,或者底層資源(如 CPU、記憶體)不足時,可能會導致請求堆積和超時。
以內建的 ResourceQuota 為例,作為內建 Kubernetes Admission Controller 的一部分,其工作流程與 Webhook 非常相似。當使用者嘗試建立或更新資源時,API Server 會呼叫 ResourceQuota Admission Controller 檢查是否違反資源配額限制。這個過程中,API Server 需要計算資源的當前使用量並進行比較,對應的資源限制狀態將會更新至 etcd。
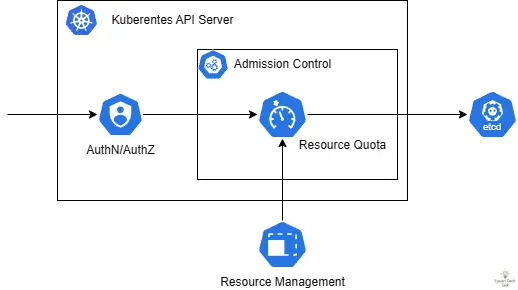
一個有趣的案例是 ResourceQuota 因為 Kubernetes Controller Manager 負載過高無法正確工作,常見於 Kubernetes 資源過多或是 CPU 處理速度過慢導致。由於 ResourceQuota 屬於預設 Validating Admission Plugin 的一部分,當其監控邏輯出現問題時,可能會影響到整個集群的資源配額執行。這種情況下,集群可能無法正確限制資源使用,導致超額配置或資源分配不均。以下是一個實際案例,展示了 ResourceQuota Controller 因為同步超時而影響集群運作的情況:
E0119 11:37:53.532226 1 shared_informer.go:243] unable to sync caches for garbage collector
E0119 11:37:53.532261 1 garbagecollector.go:228] timed out waiting for dependency graph builder sync during GC sync (attempt 73)
I0119 11:37:54.680276 1 request.go:645] Throttling request took 1.047002085s, request: GET:https://10.150.233.43:6443/apis/configuration.konghq.com/v1beta1?timeout=32s
I0119 11:37:54.831942 1 shared_informer.go:240] Waiting for caches to sync for garbage collector
I0119 11:38:04.722878 1 request.go:645] Throttling request took 1.860914441s, request: GET:https://10.150.233.43:6443/apis/acme.cert-manager.io/v1alpha2?timeout=32s
E0119 11:38:04.861576 1 shared_informer.go:243] unable to sync caches for resource quota
E0119 11:38:04.861687 1 resource_quota_controller.go:447] timed out waiting for quota monitor sync
在這個範例中,我們可以看到 API Server 發出請求到 ResourceQuota 控制器時,可能會因為控制平面負載過高而導致處理延遲,使得套用的 ResourceQuota 更新與 etcd 的紀錄不一致,比如套用新的 記憶體上限 (52Gi) 但無法在新的資源中同步套用 (62Gi)。
$ kubectl get quota webs-compute-resources -n webs -o yaml
spec:
hard:
pods: "18"
limits.cpu: "26"
limits.memory: "52Gi"
status: {}
$ kubectl describe namespace webs
Name: webs
Labels: team=webs
webs.tree.hnc.x-k8s.io/depth=0
Annotations: <none>
Status: Active
Resource Quotas
Name: webs-compute-resources
Resource Used Hard
-------- --- ---
Resource Limits
Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio
---- -------- --- --- --------------- ------------- -----------------------
Container cpu 50m 2 150m 500m -
Container memory 16Mi 18Gi 32Mi 64Mi -
新建立的 Pod 事件仍參考舊有的記憶體限制 (62Gi),但後續的更新顯示限制已降至 52Gi,然而系統行為仍然參考舊的限制值。這種不一致性可能導致資源配置混亂,甚至阻礙新 Pod 的建立。在高負載環境中,控制平面組件之間的同步延遲會更加嚴重。
creating: pods "workspace-7cc88789c5-fmcxm" is forbidden: exceeded quota: compute-resources, requested: limits.memory=10Gi, used: limits.memory=60544Mi, limited: limits.memory=62Gi
4. 資源限制和擴展性問題 (Data Plane)
當 webhook 服務的資源配置不足,或者無法有效地進行水平擴展時,可能會導致服務不穩定。例如,如果 webhook Pod 的記憶體限制設置過低,可能會導致 OOM(Out of Memory)錯誤;或者如果沒有正確配置 HPA(Horizontal Pod Autoscaling),在高負載時可能無法及時擴展來處理增加的請求量。
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: pod-resources-example
spec:
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
containers:
- name: memory-demo-ctr
image: nginx
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]
連鎖故障案例
連鎖故障是指當一個核心組件的 webhook 出現問題時,可能會觸發一連串的系統性故障。以下是幾個實際案例:
系統資源耗盡故障案例
在一個真實案例中,Webhook 服務因為因為節點資源不足發生的錯誤。核心問題由於節點的記憶體不足加上磁碟空間接近滿觸發驅逐事件 (Eviction):
$ kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
example-pod-1234 0/1 Evicted 0 5m
example-pod-5678 0/1 Evicted 0 10m
example-pod-9012 0/1 Evicted 0 7m
example-pod-3456 0/1 Evicted 1 15m
example-pod-7890 0/1 Evicted 0 3m
最終導致新的 Pod 無法創建,造成整個服務不可用。
$ kubectl get events -n curl
...
23m Normal SuccessfulCreate replicaset/curl-9454cc476 Created pod: curl-9454cc476-khp45
22m Warning FailedCreate replicaset/curl-9454cc476 Error creating: Internal error occurred: failed calling webhook "namespace.sidecar-injector.istio.io": failed to call webhook: Post "https://istiod.istio-system.svc:443/inject?timeout=10s": dial tcp 10.96.44.51:443: connect: connection refused
Node-pressure Eviction 發生在當節點面臨資源壓力(例如記憶體不足、磁碟空間不足或磁碟 I/O 壓力)時。Kubelet 會根據預設或自定義的閾值監控這些資源,當超過閾值時,節點會被標記為有壓力狀態,並開始驅逐 Pod 以釋放資源。這種情況下,優先級較低的 Pod 會先被驅逐,直到節點資源壓力降低到安全水平。然而,如果驅逐進程未能及時停止,可能會連鎖影響到關鍵的 webhook 服務 Pod,導致它們也被驅逐。當 webhook 服務不可用時,API Server 無法完成任何受該 webhook 關聯的資源操作,進而導致整個集群的功能受限。在高壓力環境下,這種連鎖反應可能會迅速擴散,從單個節點問題演變為全集群服務中斷。
Kubernetes Controller Manager 阻塞故障案例
在這個案例中,Controller Manager 因為無法與 webhook 服務建立連接而陷入重試循環,導致系統性能下降。從日誌可以看出,控制器嘗試同步作業時遇到了 webhook 調用失敗的問題:
I0623 12:15:42.123456 1 job_controller.go:256] Syncing Job default/example-job
E0623 12:15:42.124789 1 job_controller.go:276] Error syncing Job "default/example-job": Internal error occurred: failed calling webhook "validate.jobs.example.com": Post "https://webhook-service.default.svc:443/validate?timeout=10s": dial tcp 10.96.0.42:443: connect: connection refused
W0623 12:15:42.125000 1 controller.go:285] Retrying webhook request after failure
E0623 12:15:52.130123 1 job_controller.go:276] Error syncing Job "default/example-job": Internal error occurred: failed calling webhook "validate.jobs.example.com": Post "https://webhook-service.default.svc:443/validate?timeout=10s": dial tcp 10.96.0.42:443: connect: connection refused
W0623 12:15:52.130456 1 controller.go:285] Retrying webhook request after failure
在這個案例中,原先只是單一個 Webhook 故障導致 Pod 無法建立的錯誤,然而,引爆連鎖故障的關鍵在於這個案例也同時部署了大量的 Kubernetes Jobs,這些 Kubernetes Jobs 會連續不斷地被重新建立,每一次 Job 建立都會觸發 webhook 調用。
當 webhook 服務不可用時,Job Controller 會進入重試循環。Job Controller 同時屬於 Kubernetes Controller Manager 的一部分,Kubernetes Controller Manager 本身的設計為一個無窮迴圈,不斷的運行其他控制器。隨著 Job 數量增加,Job Controller 的資源消耗急劇上升 (CPU),因為迴圈大部分時間都在處理 Job Controller 的工作,進而影響到其他 Kubernetes Controller Manager 核心功能的正常運作。
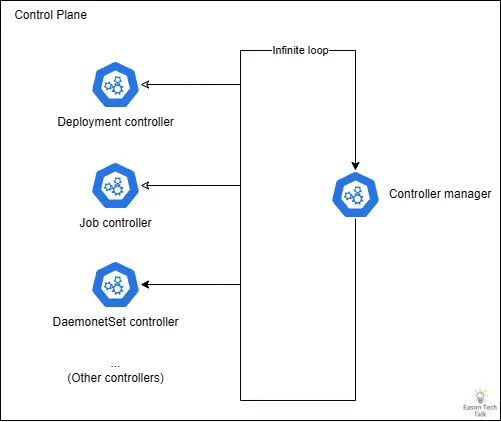
這種情況特別嚴重的是,當 Kubernetes Controller Manager 的處理能力被大量 Job Controller 觸發的 webhook 重試請求佔用時,它無法有效地執行其他關鍵控制器,如 Deployment、StatefulSet 或 DaemonSet。
當 Kubernetes Controller Manager 反覆嘗試與不可用的 webhook 服務通訊,導致控制迴圈被阻塞。隨著重試次數增加,越來越多的請求堆積,這種阻塞效應會迅速擴散,特別是當涉及核心組件(如 CNI 插件依賴地的 DaemonSet Controller)時,CNI 無法正確部署,可能導致新擴展出來的節點無法正確初始化 (處於 NotReady 狀態),即使有足夠的硬體資源也無法恢復服務。
Calico + Kyverno 案例
如果有關鍵組件 (例如 CNI) 與 Webhook 服務存在依賴關係時,更要特別注意 Webhook 故障對於叢集可用性的影響,否則一個簡單的 Webhook 故障可能會導致更嚴重的連鎖效應。
在這個案例提供的審計紀錄檔中,顯示 Calico 網路組件和 Kyverno 策略引擎之間的相互阻塞導致了嚴重的叢集可用性問題。當 Calico 需要更新服務配置時,Kyverno 的 webhook 無法正常回應,因為它沒有可用的端點。這種死鎖狀態使關鍵的網路元件無法更新,最終導致整個叢集的網路功能受損或完全失效。
{
"kind": "Event",
"apiVersion": "audit.k8s.io/v1",
"level": "RequestResponse",
"stage": "ResponseComplete",
"requestURI": "/api/v1/namespaces/calico-system/services/calico-typha",
"verb": "update",
"responseStatus": {
"metadata": {},
"status": "Failure",
"message": "Internal error occurred: failed calling webhook \"validate.kyverno.svc-fail\": failed to call webhook: Post \"https://kyverno-svc.kyverno.svc:443/validate/fail?timeout=10s\": no endpoints available for service \"kyverno-svc\"",
"reason": "InternalError",
"details": {
"causes": [{
"message": "failed calling webhook \"validate.kyverno.svc-fail\": failed to call webhook: Post \"https://kyverno-svc.kyverno.svc:443/validate/fail?timeout=10s\": no endpoints available for service \"kyverno-svc\""
}]
},
"code": 500
},
}
這種錯誤輕則影響網路策略 (NetworkPolicy) 無法正常工作,頂多影響一些 Pod 的網路通訊,然而,嚴重點則可能導致整個叢集網路完全失效。當 Calico 網路元件無法更新或重新配置時,整個叢集的網路功能可能會被癱瘓,節點間的通訊完全中斷,新節點也無法加入叢集。
監控與偵測策略
前面我們探討了一些 webhook 故障的模式,在瞭解到 webhook 故障所帶來的可能影響後,下面要繼續討論一些可以考慮實行的一些錯誤偵測和監控策略。
1. 關鍵指標監控
Kubernetes 預設提供了許多內建以 Prometheus 格式呈現的關鍵指標 2,涉及 Admission Webhook 相關的指標通常有以下幾項:
webhook_rejection_count: 追蹤被拒絕的webhook請求數量,異常增加可能表示配置問題或服務不穩定。webhook_request_total: 記錄所有請求總數,幫助了解流量趨勢並識別潛在異常模式。webhook_fail_open_count: 記錄因故障而自動通過的請求數,對設置 failurePolicy: Ignore 的 webhook 尤其重要。
這些指標可以透過訪問 /metrics 路徑採集,常見透過 Prometheus、Datadog 或其他支持 Prometheus 格式的監控系統來收集和分析。以下是一個通過 kubectl 命令檢查 API Server 相關指標的範例:
$ kubectl get --raw /metrics | grep "apiserver_admission_webhook"
apiserver_admission_webhook_request_total{code="400",name="mpod.elbv2.k8s.aws",operation="CREATE",rejected="true",type="admit"} 17
$ kubectl get --raw /metrics | grep "apiserver_admission_webhook_rejection"
apiserver_admission_webhook_rejection_count{error_type="calling_webhook_error",name="mpod.elbv2.k8s.aws",operation="CREATE",rejection_code="400",type="admit"} 17
一些開源的社群整合方案則包含 kube-prometheus-stack 套件,可以透過 Helm 工具快速的安裝套件,提供完整的 Prometheus 和 Grafana 監控解決方案,包含預設的 API Server 和 Webhook 相關指標儀表板。這種整合式方案不僅能幫助我們監控 webhook 的運作狀態,還能在潛在問題發生前提供預警。
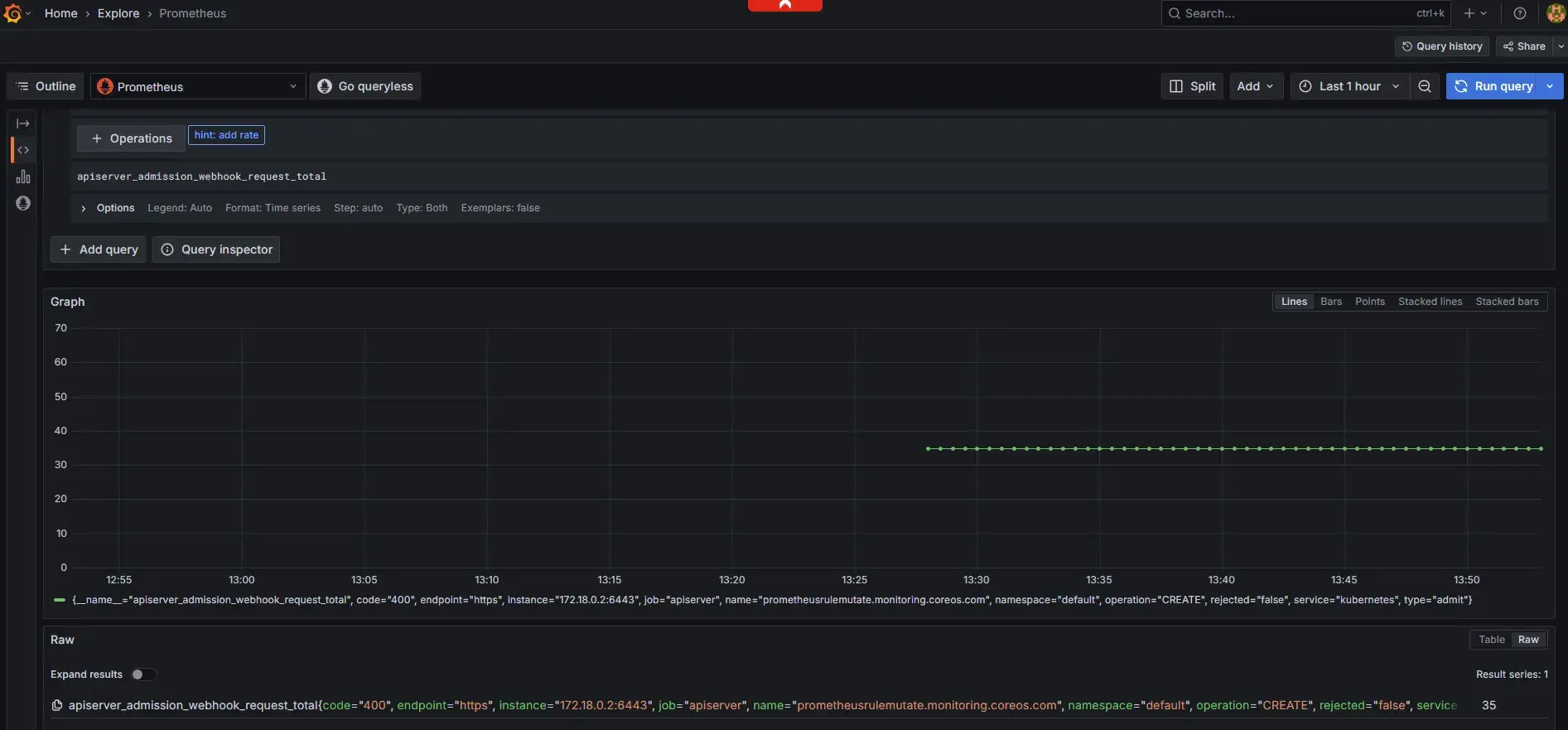
此外,針對關鍵性的應用和服務,可以參考是否提供對應的 Prometheus 或對應指標監控應用的可用性,建立特定的監控指標和警報閾值。同時監控相關的資源使用情況,如 CPU、記憶體使用率,以及網絡延遲等指標。
2. 記錄檔分析
除了 API server 指標,你也可以透過紀錄檔分析來主動過濾和發現可能的呼叫失敗錯誤。當遇到 webhook 相關問題時,分析API server的日誌可以提供寶貴的線索。從 API Server 觸發 webhook 的操作中便可以窺知一二,Kubernetes 在 Mutating 以及 Validating 階段存在 dispatcher.go 副程式進行觸發操作,在目前版本中 (Kubernetes v1.33),皆以 failed to call webhook 作為錯誤訊息輸出 3 4:
if err != nil {
var status *apierrors.StatusError
if se, ok := err.(*apierrors.StatusError); ok {
status = se
} else {
status = apierrors.NewServiceUnavailable("error calling webhook")
}
return &webhookutil.ErrCallingWebhook{WebhookName: h.Name, Reason: fmt.Errorf("failed to call webhook: %w", err), Status: status}
}
因此,我們可以透過上述輸出作為關鍵字。當 Webhook 發生故障時,API Server 通常會記錄詳細的錯誤信息,包括連接超時、TLS 錯誤或服務不可用等問題。並且在雲原生環境中配置集中式日誌收集與分析系統。
以下是在 AWS CloudWatch Log Insight 中過濾 API Server 日誌的範例查詢,這個簡單的查詢示例過濾了所有包含 failed to call webhook 的 kube-apiserver 日誌 5:
fields @timestamp, @message, @logStream
| filter @logStream like /kube-apiserver/
| filter @message like 'failed to call webhook'
以下是以 CloudWatch 為例,將過濾的結果轉換成指標,用於監控或是設定告警等 5。
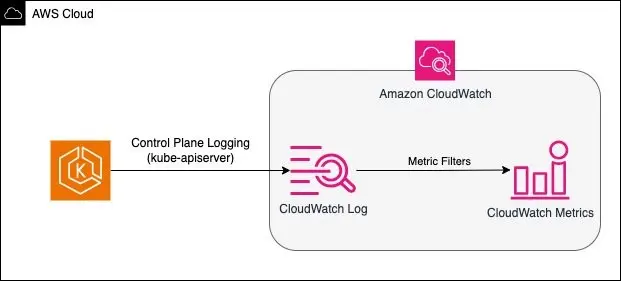
若是自建或是私有地端的 Kubernetes 叢集環境,同樣地也可以持續過濾這些 API Server 日誌,整合自動告警機制,即時發送通知捕捉這些錯誤。
3. 健康狀態監控
定期檢查 webhook 服務的健康狀態是預防問題的第一道防線:
- 設置基本的 Liveness Probe 和 Readiness Probe
- 監控服務的響應時間和錯誤率
- 追蹤 webhook 服務的資源使用情況(CPU、記憶體等)
最佳實踐
在本節中,我們將探討防止和應對 Kubernetes Webhook 故障的最佳實踐。這些建議來自於實際生產環境中的經驗,旨在幫助您建立更穩健的 Kubernetes 環境。以下是幾個關鍵領域的最佳實踐建議:
1. 資源配置最佳化
- 為 webhook 服務設置適當的資源請求和限制
- 為關鍵 webhook 服務運行多個副本並且實施水平自動擴展(HPA)以應對負載變化
- 使用 Pod Disruption Budget 確保服務可用性
2. 安全性考量
- 定期輪換 TLS 證書,尤其是在使用自簽憑證的情況下
- 使用 cert-manager 實施自動化的憑證管理時,務必關注憑證的有效期限和更新狀態
3. 其他優化考量
- 在專用命名空間 (Namespace) 中運行自定義 webhook 服務,避免故障時影響所有 Namespace (例如:正確使用 namespaceSelector 和 objectSelector 等避免故障時影響所有資源,甚至造成 deadlock)
- 對於 Kubernetes v1.30 之後的版本,考慮使用 ValidatingAdmissionPolicy 取代傳統的驗證 webhook,降低外部應用的依賴,以改善系統穩定性
這是一個簡易的 ValidatingAdmissionPolicy 範例,描述當建立或更新 Deployment 時,副本數量應小於或等於五個。
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicy
metadata:
name: "demo-policy.example.com"
spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
validations:
- expression: "object.spec.replicas <= 5"
---
apiVersion: admissionregistration.k8s.io/v1
kind: ValidatingAdmissionPolicyBinding
metadata:
name: "demo-binding-test.example.com"
spec:
policyName: "demo-policy.example.com"
validationActions: [Deny]
matchResources:
namespaceSelector:
matchLabels:
environment: test
這類資源可以在 Kubernetes Control Plane 層面完成您原本依賴外部 Webhook 服務的機制,無需呼叫外部 Webhook,從而降低因外部因素導致無法呼叫 Webhook 的風險。
📝 註:MutatingAdmissionPolicy 與 ValidatingAdmissionPolicy 類似,但提供修改資源的能力,目前在 Kubernetes v1.32 版本中處於 Alpha 階段。這項功能將使得開發者能夠直接在 Kubernetes API 中定義資源修改規則,而無需部署和維護外部 webhook 服務,進一步減少系統故障點。詳細訊息,請參考 KEP-39626。
總結
Kubernetes Admission Webhook 提供了強大的擴展能力,但同時也引入了潛在的風險點。通過了解常見的故障模式、實施有效的監控策略、採用最佳實踐,我們可以顯著提高系統的穩定性和可靠性。
本篇文章已經詳細介紹了 Kubernetes Webhook 的故障管理,從基本概念到診斷方法,再到監控策略和最佳實踐。我們看到了如何識別常見的故障模式,以及如何通過指標監控和日誌分析來預防問題。特別值得注意的是,隨著 Kubernetes 的發展,像 ValidatingAdmissionPolicy 這樣的新功能正在減少對外部 webhook 的依賴,從而提高系統的穩定性。
希望這篇文章能為你提供有價值的見解和實用的工具,幫助你更有效地管理 Kubernetes 環境中的 webhook 服務。
📧 訂閱 EasonTechTalk:獲得技術洞察與實戰分享
如果你對了解雲端技術和相關趨勢有興趣,歡迎訂閱 EasonTechTalk 電子報以取得更新,讓我們一起在技術路上持續精進!
參考資源
