
Kueue 快速上手:在 Kubernetes 上佇列管理共享 GPU/TPU 資源
這篇文章幫助你在 10 分鐘內了解 Kueue 是什麼、為什麼需要它、以及如何在共享 GPU/TPU 叢集上使用它。
為什麼只靠 Kubernetes 還不夠?
Kubernetes 本身的調度器可以透過 Job 或 CronJob 執行批次工作負載,但無法有效管理資源分配與等待邏輯。Kubernetes 擅長將 Pod 排程到節點上,卻不擅長管理批次工作的運行時機。例如運行 AI/ML 訓練任務時,通常會需要使用大量的運算資源,如 GPU 或 TPU。然而,在多團隊共享 GPU/TPU 的叢集中,Kubernetes 原生的調度機制就會顯得力不從心,比如你可能會遇到:
- 缺乏排隊機制:資源不足時 Job 直接失敗,或是 Pod 以直卡在 Pending 狀態,而非等待
- 缺乏配額管理:單一團隊可佔用所有 GPU/TPU,其他團隊只能空等
- 缺乏優先順序:低優先的實驗可能阻塞高優先的正式訓練任務
- 缺乏公平分配:無法保證各團隊取得合理的資源份額
正如 Kueue 的發音類似提供排隊機制的佇列 (Queue),Kueue 就是為了解決這些問題而生的 Kubernetes 原生工作佇列系統 (job queueing system)。它會將 Job 暫留 (hold) 在佇列中,只有在配額範圍內有足夠資源時,才會放行 (admit) 該 Job。
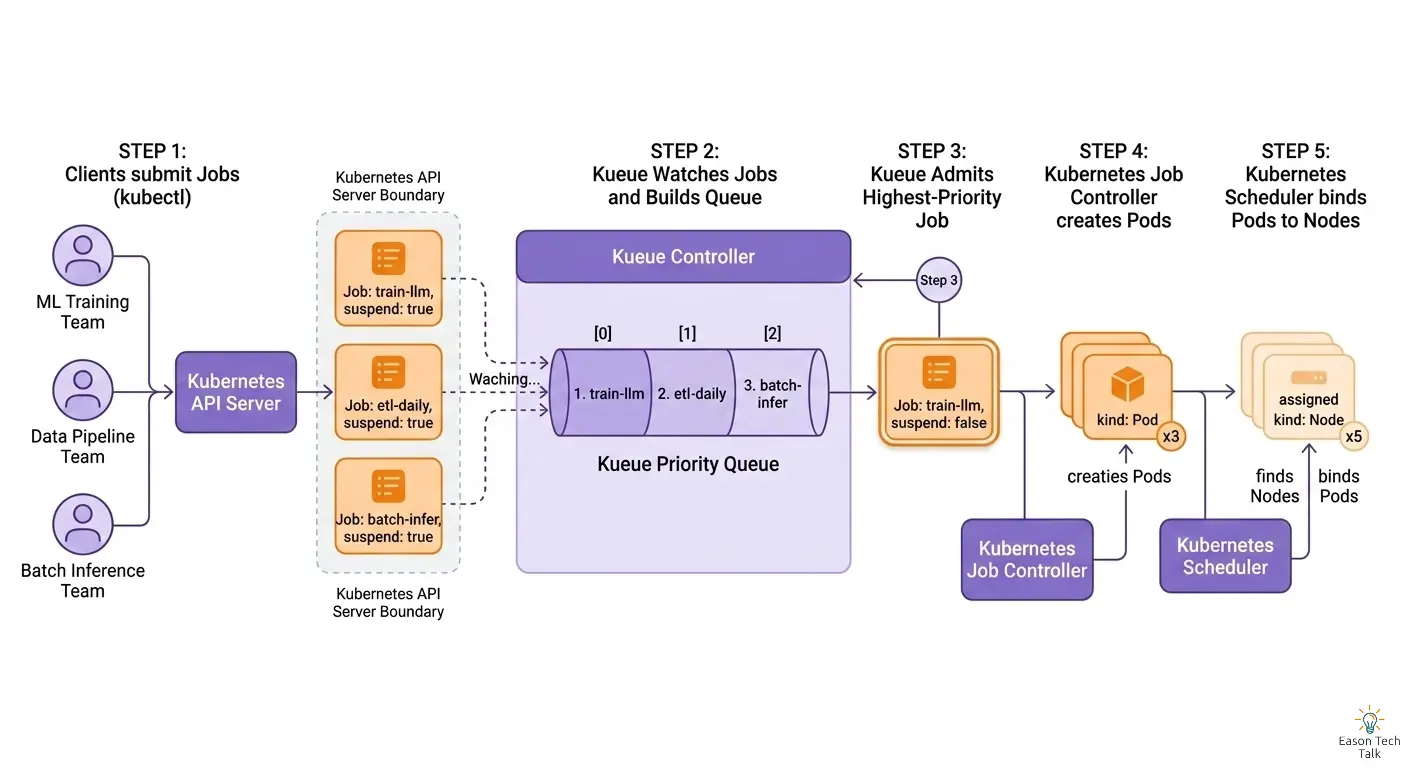
什麼是 Kueue?
Kueue 是一個 Kubernetes Controller,位於你提交 Job 與 Kubernetes Scheduler 之間。它不會取代 Scheduler,而是決定「何時」讓你的 Job 開始執行。
如果 Kubernetes 是叢集的「作業系統」,Kueue 就是航管塔台 (traffic control tower),決定哪架航班(工作負載)何時可以起飛。
Kueue 提供的核心能力:
- ✅ 配額管理 (Quota Management) — 為各團隊設定資源使用上限
- ✅ 優先順序排程 (Priority-based Scheduling) — 高優先工作優先取得資源
- ✅ 公平共享 (Fair Sharing) — 多團隊之間公平分配 GPU/TPU
- ✅ Resource-aware Admission — 資源感知的准入控制 — 僅在資源充足時才放行 Job
Kueue vs Job vs JobSet:它們的關係
常見問題:「我已經用了 JobSet,還需要 Kueue 嗎?」 答案是:兩者解決的是不同層面的問題,搭配使用效果最佳。
| 層級 | 工具 | 職責 |
|---|---|---|
| Pod 排程 | 原生 Kubernetes Scheduler | 將 Pod 分配到具體的 Node 上執行 |
| Job 編排 | JobSet | 將多個相依的 Jobs 組合成一個單元統一管理,例如一個訓練任務需要 1 個 leader Job + 3 個 worker Jobs 同時運作,JobSet 確保它們一起啟動、一起失敗重啟 |
| Job Admission | Kueue | 依據配額、優先順序與公平共享策略,決定何時允許 Job 開始執行 |
- 僅使用 Job:單一批次任務,無佇列機制。適合在專用叢集上執行簡單工作負載。
- 僅使用 JobSet:多角色分散式工作負載(例如 parameter server + workers),但缺乏資源治理。
- 僅使用 Kueue:為單一 Job 提供佇列管理與配額控管。
- Kueue + JobSet:完整方案 — 同時具備複雜分散式工作負載的編排能力與叢集層級的資源分配管理。這是大規模 TPU/GPU 訓練的建議架構。
JobSet 管「怎麼跑」,Kueue 管「什麼時候可以跑」。兩者搭配是 TPU/GPU 大規模訓練的推薦實踐。
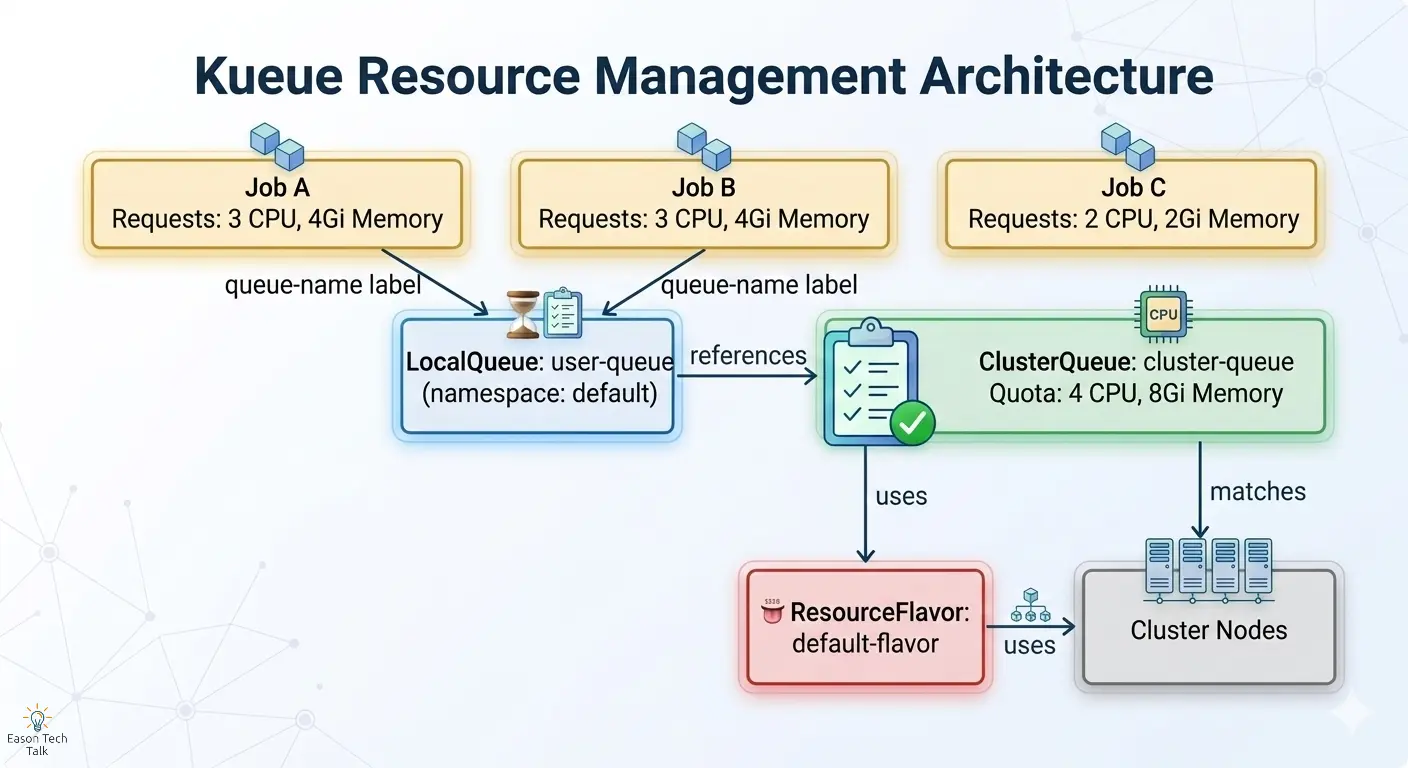
核心概念
Kueue 引入了四個核心抽象概念,在撰寫任何 YAML 之前,務必先理解它們:
| 概念 | 說明 | 類比 |
|---|---|---|
| ResourceFlavor | 定義叢集中可用的資源類型,例如 TPU v6e 1x1 topology、A100 GPU、純 CPU 節點等,透過 Node Labels 將資源與實際節點對應 | 🍽️ 菜單 — 列出廚房能供應的所有菜色 |
| ClusterQueue | 叢集級別的佇列,針對每種 ResourceFlavor 設定資源配額 (nominalQuota),控管可同時消耗的資源總量 | 👨🍳 廚房 — 管理產能上限,決定同時能出幾道菜 |
| LocalQueue | Namespace 級別的佇列,使用者將工作負載提交至此,它會將請求轉發給對應的 ClusterQueue 進行配額檢查 | 🙋 服務員 — 接收你的點單,轉交給廚房處理 |
| Workload | Kueue 內部對 Job 或 JobSet 的封裝物件,當你提交帶有 kueue.x-k8s.io/queue-name label 的 Job 時由 Kueue 自動建立 |
🎫 點餐單 — 紀錄並追蹤你的請求狀態 |
何時該使用 Kueue
| 適用場景 | 為什麼需要 Kueue | 典型範例 |
|---|---|---|
| 多團隊共享叢集 | 多個團隊競爭有限的 GPU/TPU,需要配額管理與公平共享機制 | ML 團隊 A 與團隊 B 共用同一叢集的 8 張 A100 |
| 高價值加速器資源 | TPU/GPU 不應因排程不當而閒置,Kueue 確保資源利用率最大化 | TPU v6e 單件成本高,閒置一小時即產生費用浪費 |
| 批次工作負載 (Batch) | 訓練任務、資料處理管線、CI/CD 工作等可容許排隊等待 | 模型訓練 Job 在尖峰時段排隊,離峰時自動執行 |
| 雲端成本控制 | 透過硬性配額 (hard quota) 防止過度佈建,降低不必要的雲端支出 | 設定團隊最多只能使用 16 個 TPU chips,避免意外超支 |
| Multi-slice TPU 訓練 | 搭配 JobSet 編排多節點分散式訓練,由 Kueue 控管 admission 時機 | 使用 3 個 TPU slice 進行 Multislice JAX 訓練 |
只要你的叢集有超過一個團隊提交批次工作 (batch jobs),你可能就需要考慮 Kueue。若你的工作負載使用 JobSet 進行多節點訓練 (multi-node training),加上 Kueue 便構成完整的資源治理方案。
運作方式:Admission 流程
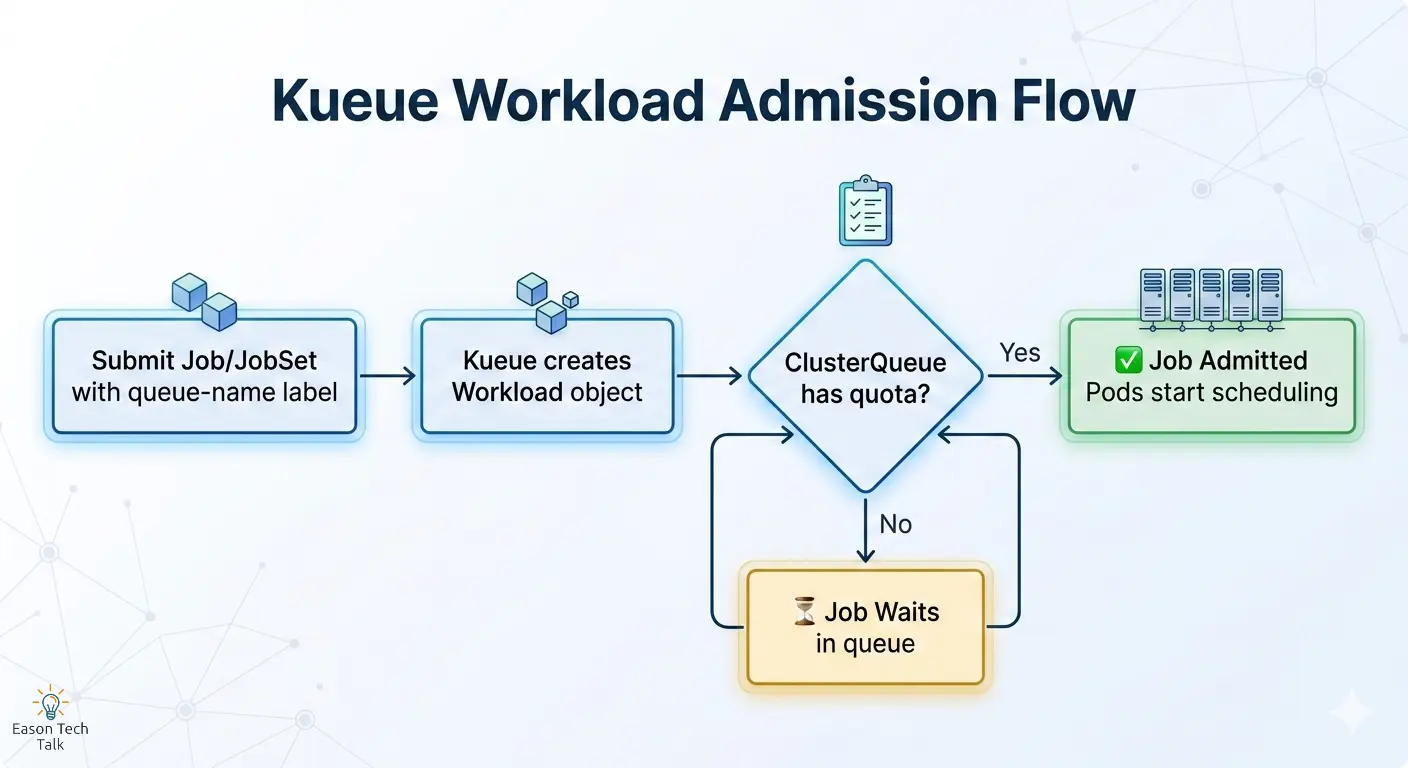
- 提交一個 Job 或 JobSet,附上
kueue.x-k8s.io/queue-namelabel 指向對應的 LocalQueue - Kueue 自動建立 Workload 物件,並檢查 ClusterQueue 的可用配額
- 配額充足 → Job 被 admitted(允許執行),Pod 開始進入排程
- 配額不足 → Job 在佇列中等待,直到有資源釋放
快速實作:3 步設定 Kueue
以下範例使用 CPU 與 Memory 作為配額資源,讓你在任何標準 Kubernetes 叢集上就能立即驗證 Kueue 的運作流程,不需要 GPU 或 TPU。
架構總覽
步驟一:安裝 Kueue
# 安裝 Kueue
helm install kueue oci://registry.k8s.io/kueue/charts/kueue \
--namespace kueue-system \
--create-namespace \
--wait --timeout 300s
步驟二:設定 ResourceFlavor + ClusterQueue + LocalQueue
# ResourceFlavor: 使用 default flavor(不限制特定節點)
apiVersion: kueue.x-k8s.io/v1beta2
kind: ResourceFlavor
metadata:
name: default-flavor
spec: {} # 空的 spec 代表任何節點都符合
---
# ClusterQueue: 設定 CPU 與 Memory 總配額
apiVersion: kueue.x-k8s.io/v1beta2
kind: ClusterQueue
metadata:
name: cluster-queue
spec:
namespaceSelector: {} # 允許所有 namespace
queueingStrategy: BestEffortFIFO
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: default-flavor
resources:
- name: "cpu"
nominalQuota: 4 # 總共可用 4 個 CPU cores
- name: "memory"
nominalQuota: 8Gi # 總共可用 8Gi 記憶體
---
# LocalQueue: 使用者提交工作負載的入口
apiVersion: kueue.x-k8s.io/v1beta2
kind: LocalQueue
metadata:
namespace: default
name: user-queue
spec:
clusterQueue: cluster-queue
步驟三:提交帶有 Kueue Label 的 Job
提交兩個 Job,各請求 3 個 CPU。由於 ClusterQueue 總配額只有 4 個 CPU,第一個 Job 會被立即 admitted,第二個則會在佇列中等待,直到第一個完成後釋放資源。
# Job 1: 請求 3 CPU + 4Gi Memory
apiVersion: batch/v1
kind: Job
metadata:
generateName: sample-job-
labels:
kueue.x-k8s.io/queue-name: user-queue # 👈 指向 LocalQueue
spec:
template:
spec:
containers:
- name: worker
image: busybox:1.36
command: ["sh", "-c", "echo 'Hello from Kueue!'; sleep 30"]
resources:
requests:
cpu: "3"
memory: "4Gi"
restartPolicy: Never
backoffLimit: 0
你可以透過以下指令觀察 Kueue 的行為:
# 查看 ClusterQueue 狀態(配額使用情況)
kubectl get clusterqueue cluster-queue -o wide
# 查看 Workload 物件(確認哪些 Job 被 admitted、哪些在等待)
kubectl get workloads -n default
GKE AI 系列文章:
