
JobSet 排查實錄 (解決 follower pod node selector not set)
在用 JobSet 跑 multi-slice TPU 或 GPU 的分散式訓練時,JobSet 的 leader-follower 機制會先排程 leader pod,再透過 mutating webhook 讀取 leader 所在節點的 topology label,將對應的 nodeSelector patch 到 follower pods 上,確保同一組 Pod 被排程到相同的拓撲域。這個設計在正常情況下運作良好,但當底層的加速器資源不足、leader pod 卡在 Pending 無法排程時,你會看到一個讓人困惑的錯誤:
admission webhook "vpod.kb.io" denied the request: follower pod node selector not set
直覺會讓人去檢查 follower pod 的 node selector 設定,但問題其實不在那裡。經過數小時的排查,我發現這個錯誤訊息其實是一個診斷假象,它遮蔽了真正的根因,讓你以為是 JobSet 的設定出了問題,但實際很可能是 基礎設施資源不足,導致 leader pod 無法排程。而這個誤導性訊息會出現,是因為 validating webhook 在 pkg/webhooks/pod_webhook.go 中的驗證順序有一個微妙的問題:它先檢查了 follower 的 NodeSelector,卻沒有先確認 leader 是否已經被排程。
最近我在排查這個問題後,開了 Issue #1187 並提交了兩個 PR,分別從不同層面來解決。同時撰寫本文將從這次實際的診斷經驗出發,拆解 JobSet 的 leader-follower 排程機制、mutating 與 validating webhook 的互動關係,以及為什麼調整驗證順序能讓誤導性錯誤變成有用的診斷資訊。
本文程式碼引用基於 JobSet
mainbranch(PR #1159 重構後)。該 PR 將原本分散在pod_mutating_webhook.go和pod_admission_webhook.go的邏輯合併為單一的pod_webhook.go,採用 controller-runtime 的admission.Defaulter/admission.Validator介面。在release-0.11及更早版本中,同樣的邏輯分佈在兩個檔案中,但驗證順序的問題是相同的。
JobSet Leader-Follower 機制概述
JobSet 在處理 TPU multi-slice 或需要 exclusive placement 的 workload 時,採用了 leader-follower 的排程架構。這個機制的核心邏輯是:leader pod(index 0)先被排程到合適的節點,接著當 follower pods 被建立並進入 admission 流程時,mutating webhook 會讀取 leader pod 所在節點的 topology label,將對應的 nodeSelector patch 到 follower pods 上,確保它們被排程到相同的拓撲域。
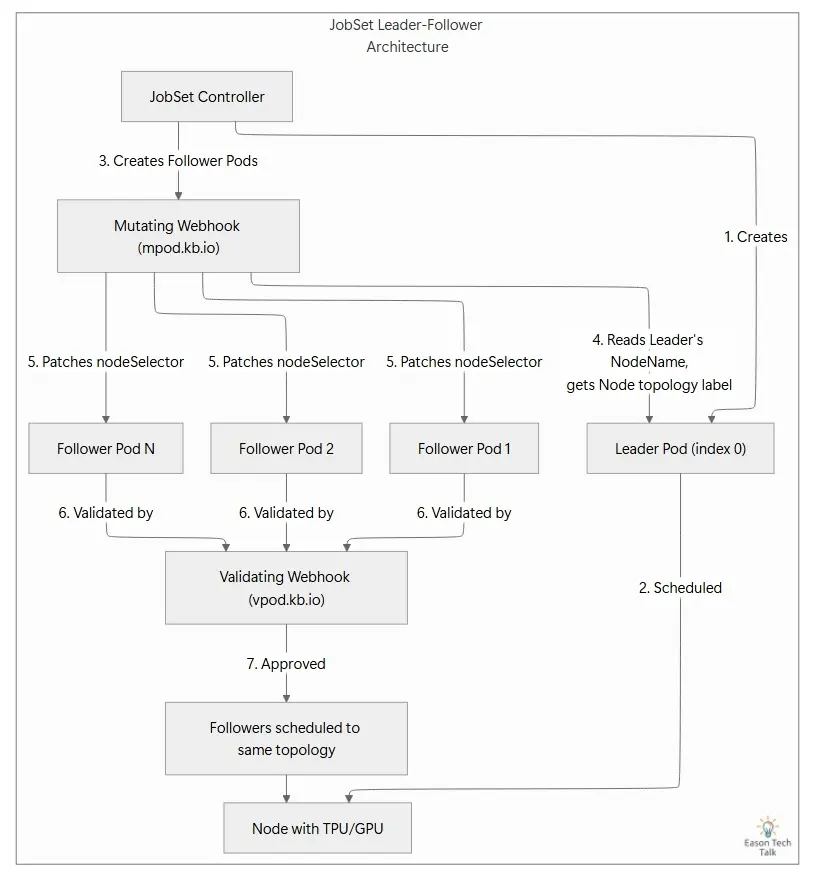
整個流程仰賴以下兩個 webhook 的協作。
Mutating Webhook:負責 Patch Node Selector
JobSet 的 mutating webhook(mpod.kb.io)會攔截每一個 pod 的建立請求。對於使用 exclusive placement 的 follower pod,它會呼叫 setNodeSelector:
- 先透過
leaderPodForFollower找到對應的 leader pod,再檢查 leader 的Spec.NodeName是否已被設定。 - 如果 leader 已經被排程,webhook 會呼叫
topologyFromPod取得 leader 所在 Node 的 topology label(例如 node pool 名稱),並將它作為 nodeSelector patch 到 follower pod 上。 - 但如果 leader 還在
Pending狀態(Spec.NodeName為空),mutating webhook 會直接 returnnil,不做任何 patch,它透過程式碼註解明確說明:把拒絕 follower 的責任留給 validating webhook。
func (p *podWebhook) setNodeSelector(ctx context.Context, pod *corev1.Pod) error {
log := ctrl.LoggerFrom(ctx)
// Find leader pod (completion index 0) for this job.
leaderPod, err := p.leaderPodForFollower(ctx, pod)
if err != nil {
log.Error(err, "finding leader pod for follower")
// Return no error, validation webhook will reject creation of this follower pod.
return nil
}
// If leader pod is not scheduled yet, return error to retry pod creation until leader is scheduled.
if leaderPod.Spec.NodeName == "" {
// Return no error, validation webhook will reject creation of this follower pod.
return nil
}
// Get the exclusive topology value for the leader pod (i.e. name of nodepool, rack, etc.)
topologyKey, ok := pod.Annotations[jobset.ExclusiveKey]
if !ok {
return fmt.Errorf("pod missing annotation: %s", jobset.ExclusiveKey)
}
topologyValue, err := p.topologyFromPod(ctx, leaderPod, topologyKey)
if err != nil {
log.Error(err, "getting topology from leader pod")
return err
}
// Set node selector of follower pod so it's scheduled on the same topology as the leader.
if pod.Spec.NodeSelector == nil {
pod.Spec.NodeSelector = make(map[string]string)
}
log.V(2).Info(fmt.Sprintf("setting nodeSelector %s: %s to follow leader pod %s", topologyKey, topologyValue, leaderPod.Name))
pod.Spec.NodeSelector[topologyKey] = topologyValue
return nil
}
這個行為是符合預期的。leader 還沒被排程,Node 的 topology label 無從取得,本來就沒有值可以 patch。
Validating Webhook:負責驗證 Follower Pod 的合法性
Mutating webhook 處理完之後,vpod.kb.io validating webhook 的 ValidateCreate 會接著執行驗證。在 pkg/webhooks/pod_webhook.go 中,這個驗證流程包含兩個關鍵檢查:
- NodeSelector 檢查:確認 follower pod 是否已經有 node selector
- Leader 排程狀態檢查:確認 leader pod 是否已經被排程
// ValidateCreate validates that follower pods (job completion index != 0) part of a JobSet using exclusive
// placement are only admitted after the leader pod (job completion index == 0) has been scheduled.
func (p *podWebhook) ValidateCreate(ctx context.Context, pod *corev1.Pod) (admission.Warnings, error) {
...
// Do not validate anything else for leader pods, proceed with creation immediately.
if placement.IsLeaderPod(pod) {
return nil, nil
}
// If a follower pod node selector has not been set, reject the creation.
if pod.Spec.NodeSelector == nil {
return nil, fmt.Errorf("follower pod node selector not set")
}
if _, exists := pod.Spec.NodeSelector[topologyKey]; !exists {
return nil, fmt.Errorf("follower pod node selector for topology domain not found. missing selector: %s", topologyKey)
}
// For follower pods, validate leader pod exists and is scheduled.
leaderScheduled, err := p.leaderPodScheduled(ctx, pod)
if err != nil {
return nil, err
}
if !leaderScheduled {
return nil, fmt.Errorf("leader pod not yet scheduled, not creating follower pod. this is an expected, transient error")
}
return nil, nil
}
問題的核心就在於這個驗證的執行順序。當 validating webhook 先檢查 NodeSelector 是否存在,而後才檢查 leader pod 的排程狀態時,就會導致錯誤訊息無法正確反映真正的問題根源。這個順序上的安排,使得更有診斷價值的 transient error 被完全遮蔽,讓使用者看到的是一個誤導性的錯誤提示。
驗證順序遮蔽了真正的錯誤訊息
問題現象
在 GKE 上跑一個 multi-slice TPU training job 時,follower pods 全部被拒絕,錯誤訊息如下:
admission webhook "vpod.kb.io" denied the request: follower pod node selector not set
同時在 webhook server 的 log 中,mutating webhook 的 setNodeSelector 有時會記錄另一條更有資訊量的錯誤,當 leader pod 尚未被建立時,leaderPodForFollower 會回傳 error,並被記錄為:
ERROR admission finding leader pod for follower
{"error": "expected 1 leader pod (example-job-0-0), but got 0. this is an expected, transient error"}
注意這兩條訊息的差異:透過事件日誌中大部分看到的錯誤都是 validating webhook 回傳的第一條,讓人以為是 follower pod 的設定問題;而第二條來自 mutating webhook,才是真正有診斷價值的資訊。在比較嚴謹的權限設定下,由於 mutating webhook 的詳細日誌權限可能只有 cluster admin 能夠查看,一般使用者容易被誤導性的 admission error 訊息所困擾。
根本原因:驗證順序的問題
為什麼會這樣?讓我們拆解整個流程。
當 leader pod 因資源不足而停在 Pending 狀態時:
- Follower pod 被建立,進入 admission 流程
- Mutating webhook 的
setNodeSelector發現 leader 的Spec.NodeName為空,直接 return nil,不做任何 patch,把拒絕責任留給 validating webhook - Follower pod 進入 validating webhook(
ValidateCreate) - Validating webhook 先檢查 NodeSelector,發現不存在,直接拒絕,丟出
follower pod node selector not set - Leader 排程狀態檢查根本沒有機會執行,因為已經在第 4 步被截斷了
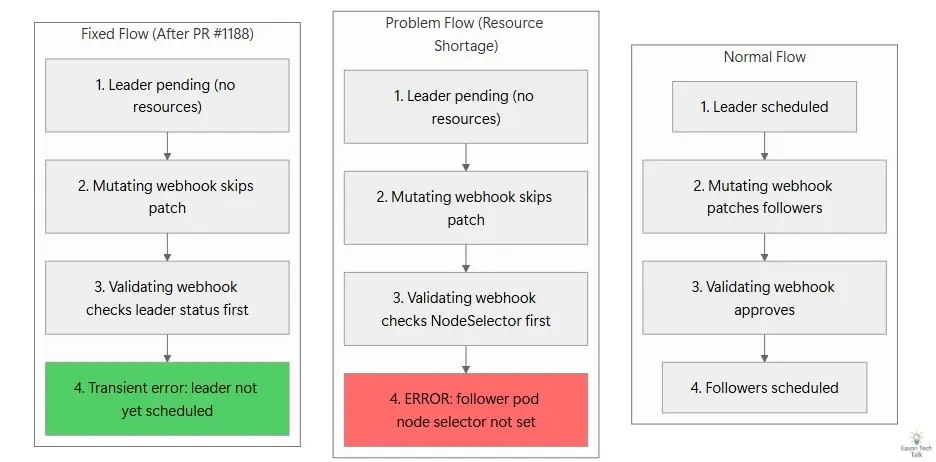
整條流程使得錯誤訊息指向的是最下游的症狀,而不是根本原因:
Infrastructure capacity 不足(TPU/GPU 資源不夠)
└── Leader pod 停在 Pending(未被排程)
└── Mutating webhook 正確地跳過 patch(符合預期)
└── Follower pod 沒有被寫入 node selector
└── Validating webhook 先檢查 NodeSelector → 拒絕
├── 使用者看到:"follower pod node selector not set"
└── 真正有用的 transient error 被遮蔽 ✘
JobSet 內部其實已經有一條設計良好的 transient error 可以顯示,但因為驗證順序的問題,它永遠不會被觸發。如果驗證順序反過來,先檢查 leader 是否已排程,那麼使用者看到的會是:
leader pod not yet scheduled, not creating follower pod. this is an expected, transient error
這條訊息會直接引導你去檢查 leader pod 的排程狀態,而不是在 follower 的設定上浪費時間。
以下流程圖說明了三種情境:正常流程(leader 先被排程)、問題流程(當前版本的驗證順序導致錯誤訊息被遮蔽)、以及目前 PR 提交修正後的流程(調整驗證順序後,transient error 能正確顯示)。
問題除錯
如果你也遇到這個錯誤,排查的關鍵在於:不要被錯誤訊息誤導,先檢查上游的 leader pod 狀態。
首先確認 leader pod 是否存在且已被排程:
kubectl get pods -n <namespace> | grep <jobset-name>.*-0-0
如果 leader pod 是 Pending,接著用 describe 查看具體原因:
kubectl describe pod <leader-pod-name> -n <namespace>
通常會看到類似這樣的事件:
Warning FailedScheduling 0/10 nodes are available: insufficient google.com/tpu resources
到這裡根因就清楚了:不是 follower pod 的設定問題,而是 infrastructure capacity 不足,導致 leader 無法排程。解法也很直接:確保 cluster 有足夠的加速器資源供 leader pod 使用。Leader 排程成功後,mutating webhook 會自動將 node selector patch 到 follower pods,後續的 validating webhook 也會順利通過。
提交 PR:從文件到程式碼的改進
找到根本原因之後,我開了 Issue #1187 1 回報這個問題,並同時提交了兩個 PR,分別從不同層面來解決:
- PR #1189 2(Documentation):在 Troubleshooting Guide 新增排查指引,已 merged
- PR #1188 3(Code Fix):調整 validating webhook 的驗證順序,讓更有幫助的 transient error 能被正確顯示
PR #1189:新增 Troubleshooting 文件(Merged)
第一個 PR 是文件層面的改進。在 JobSet 官方 Troubleshooting Guide 中新增了一個段落 4,說明當你看到 follower pod node selector not set 時,應該先檢查 leader pod 的排程狀態,而不是去改 follower 的設定。
PR #1188:調整驗證順序(Code Fix)
第二個 PR 是程式碼層面的根本修正。在 pkg/webhooks/pod_webhook.go 中,將 ValidateCreate 裡的驗證順序做了調整。一旦順利合併,當 leader pod 還沒被排程時,使用者看到的會是:
leader pod not yet scheduled, not creating follower pod. this is an expected, transient error
而不是原本那條誤導性的 follower pod node selector not set。
結語
在分散式系統中,這種因果鏈很長的 bug 其實很常見。而在 Kubernetes 的生態系中,mutating webhook 和 validating webhook 的執行順序和互動方式,更是容易讓問題的表現和根因脫節。本文透過實際案例,幫助你在遇到類似問題時快速定位真正的根因。
參考資料
-
Issue #1187 - Pod validation webhook obscures leader scheduling state by validating follower NodeSelector too early ↩
-
PR #1189 - docs: add troubleshooting section for follower pod node selector errors ↩
-
PR #1188 - Reorder follower pod validation to surface leader scheduling status ↩
-
JobSet Troubleshooting Guide - 5. Follower pods rejected with “follower pod node selector not set” ↩
