
GKE AI 系列:在 TPU 上用 JAX 跑第一個訓練工作
訓練大型機器學習模型需要專用硬體。Google 的 Tensor Processing Units (TPUs) 是其中最適合的晶片之一。不過一開始接觸 TPU 常常很卡:你得理解晶片配置、設定節點集區、管理資源。看了大量文件、排錯幾個小時後,還是很容易迷路。
這個系列記錄我的學習旅程,並用白話的方式解釋 TPU。我假設你已經熟悉 GCP 的基本操作(gcloud 指令)以及 Kubernetes 的概念,例如 Pod、Deployment、Node 與資源管理。接下來會一直使用以下名詞。
名詞說明
- TPU:Google 為機器學習打造的專用 AI 加速晶片。TPU 擅長矩陣運算,對於神經網路訓練與推論,速度通常優於 CPU 或 GPU。TPU v6e (Trillium) 是目前 GKE 上最新一代。TPU 會以「slice(切片)」的形式組成,透過 ICI (Inter-Chip Interconnect) 連接多顆晶片以支援多晶片訓練。
- GKE:Google Kubernetes Engine,是 Google Cloud 的託管 Kubernetes 服務,用來部署與擴展容器化應用。針對 TPU 工作負載,GKE 提供 TPU 節點集區、拓樸感知,以及與 Kueue 等排程工具的整合。建議使用 GKE,主要是因為它的容錯能力與較簡化的設定流程。
- JAX:Google 開發的 Python 高效能數值運算與機器學習函式庫。它結合 NumPy 的 API、支援自動微分與 XLA 編譯,非常適合 TPU 工作負載。JAX 會自動在多個裝置間平行化運算,對多晶片 TPU 設定至關重要。
了解 TPU 拓樸(簡化版)
最容易混淆的點: TPU 拓樸聽起來很複雜,其實就是晶片的排列方式。
可以這樣想:
- 一顆 晶片 = 一個運算單元(像一顆大腦)
- 拓樸 = 晶片的排列方式(行 × 列,像劇院座位)
- 2x2 = 2 行 × 2 列 = 共 4 顆晶片
常見的 TPU v6e 配置:
| 拓樸 | TPU 晶片 | 主機 | VM | 機器類型 (GKE API) | 範圍 |
|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | ct6e-standard-1t | 子主機 |
| 2x2 | 4 | 1/2 | 1 | ct6e-standard-4t | 子主機 |
| 2x4 | 8 | 1 | 1 | ct6e-standard-8t | 單一主機 |
| 2x4 | 8 | 1 | 2 | ct6e-standard-4t | 單一主機 |
先從最基本的開始。TPU 晶片是為機器學習設計的專用處理器。你聽到「2x2 拓樸」時,代表 4 顆晶片以 2 行 2 列的方式組成。實體上晶片不一定真的排成 2x2,可能分布在主機內的不同位置。重點在於邏輯拓樸:TPU 執行時會如何組織與存取這 4 顆晶片來做分散式計算。
下圖為 Google 資料中心中的 TPU v6e (Trillium) tray(托盤)。每個托盤有 4 顆晶片,對機器學習工作來說是一個獨立的運算單元(來源:1):

實際上,資料中心可以把多個托盤串接成更大的 slice(切片),用於分散式訓練。下圖示意晶片與托盤的關係,每個藍色方塊是一顆晶片,4 顆晶片構成一個托盤:

了解晶片如何拆分,有助於你理解拓樸的差異:
- 在 1x1 配置中,你只使用單一主機上的 8 顆晶片中的 1 顆。這是最小的 TPU 配置,適合開發、測試或輕量推論。
- 在 2x2 配置中,你只使用 8 顆晶片中的 4 顆(圖上以藍色標示)。這種子主機配置很適合中小型實驗或開發,不必租整台機器。
- 在 2x4 配置中,你會使用單一主機上的 8 顆晶片(實體上可能跨越兩個托盤)。
下圖示意 8 顆 TPU 晶片(藍色方塊)在不同拓樸下的排列方式。

在 GKE 使用 TPU 的方式
1. 拆解 TPU 概念(以 v6e 為例)
在寫程式碼之前,先理解 TPU 的租用方式。因為這篇文章聚焦在 GKE 上使用 TPU,我會從 GKE 的角度說明 TPU 拓樸與資源如何分配到節點上。
為了說明,我會以 GKE Standard 與其對應的機器類型作為例子。
機器類型:ct6e-standard-4t
在 GKE 中,TPU 會掛載到虛擬機(Node)上。對 Trillium (v6e) 來說,最容易入門的機器類型是 ct6e-standard-4t。
- 1 個 Node (VM) = 1、4 或 8 顆 TPU 晶片。每台 TPU v6e VM 可以包含 1、4 或 8 顆晶片。預設一台 VM 管理 4 顆晶片,除非你另外指定。
- 「全有或全無」規則: 你可以像 CPU 一樣要求 0.5 核心嗎?不行。在 GKE 上使用 TPU 時,通常必須一次申請 整個節點上的晶片,不能只要 1 顆。若你租 4 顆晶片的機器,Pod 就必須請求 4 顆晶片。
支援 TPU 的 GKE 機器類型遵循命名規則:<version>-hightpu-<chip-count>t。其中 chip-count 表示 VM 可以使用的 TPU 晶片數量。例如:
ct6e-standard-4t表示 4 顆 TPU 晶片ct6e-standard-8t表示 8 顆 TPU 晶片tpu7x-standard-4t支援 Ironwood (TPU7x),包含 4 顆 TPU 晶片
完整支援的 GKE 機器類型,請參考 Plan TPUs in GKE 2。
釐清差異:相同機器類型,不同拓樸
回到剛剛的表格:
| 拓樸 | TPU 晶片 | 主機 | VM | 機器類型 (GKE API) | 範圍 |
|---|---|---|---|---|---|
| 2x2 | 4 | 1/2 | 1 | ct6e-standard-4t | 子主機 |
| 2x4 | 8 | 1 | 2 | ct6e-standard-4t | 單一主機 |
你可能注意到 ct6e-standard-4t 出現兩次,但拓樸不同(2x2 與 2x4)。這是新手常見的混淆點,我們把它拆開來看。
關鍵概念: 機器類型(ct6e-standard-4t)代表 你的 VM 可以使用多少顆晶片,但 拓樸 代表 這些晶片在邏輯上如何排列,以支援分散式計算。
每台 VM 看到的是它被分配的晶片(通常是 4 顆),因此你可以寫程式去存取並協調這 4 顆晶片。
範例 1:ct6e-standard-4t + 2x2 拓樸
- 你拿到的資源: 1 台 VM、可使用 4 顆 TPU 晶片
- 實體情況: 這 4 顆晶片位在同一台實體主機(總共 8 顆晶片),但你只租到一半
- 邏輯排列: TPU runtime 會把它們視為 2×2 的網格(2 行、2 列)
- 適用情境: 小型訓練工作
範例 2:ct6e-standard-4t + 2x4 拓樸(多 VM)
- 你拿到的資源: 2 台 VM,每台可使用 4 顆 TPU 晶片(總共 8 顆)
- 實體情況: 這 8 顆晶片來自同一台實體主機,但為了編排,系統會暴露成 2 台 VM
- 邏輯排列: TPU runtime 會把它們視為 2×4 的網格(2 行、4 列)
- 適用情境: 較大型的訓練工作
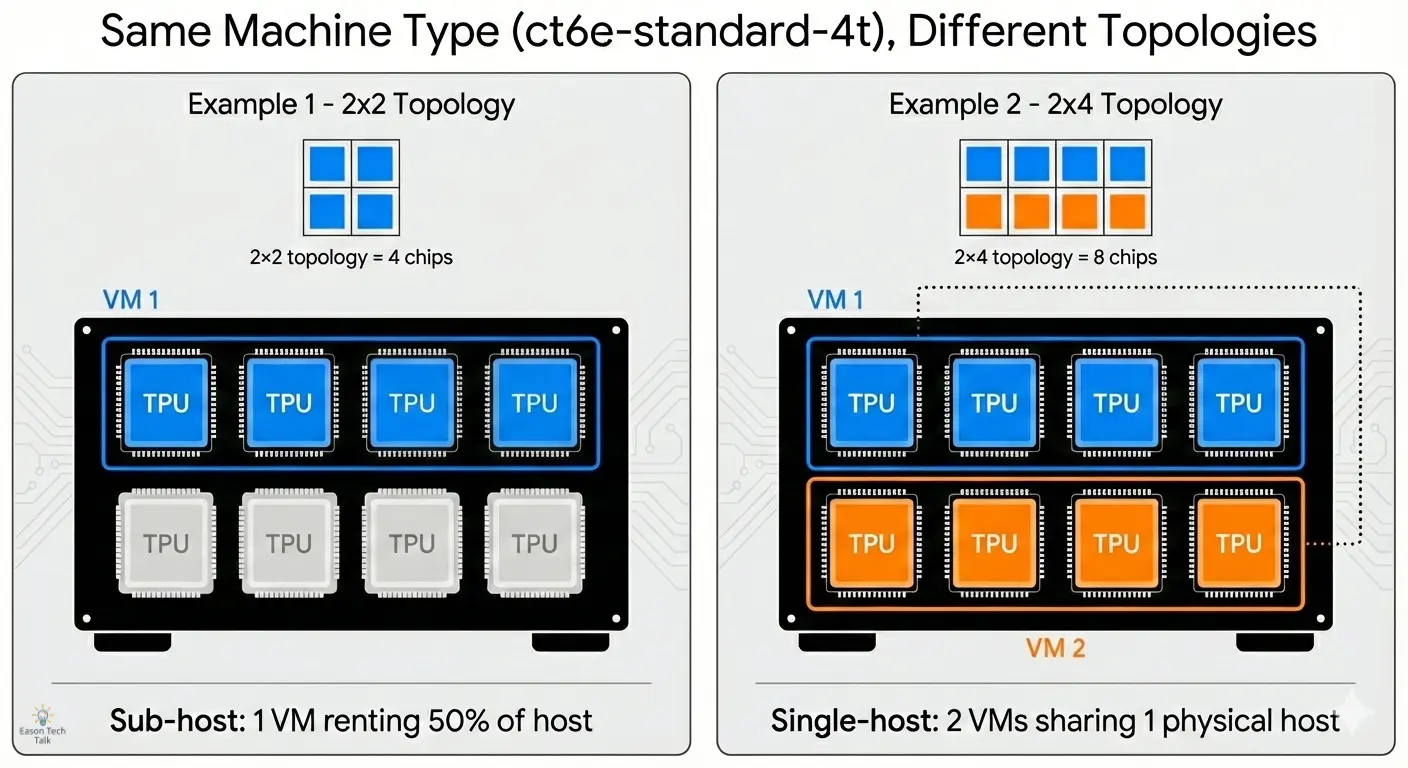
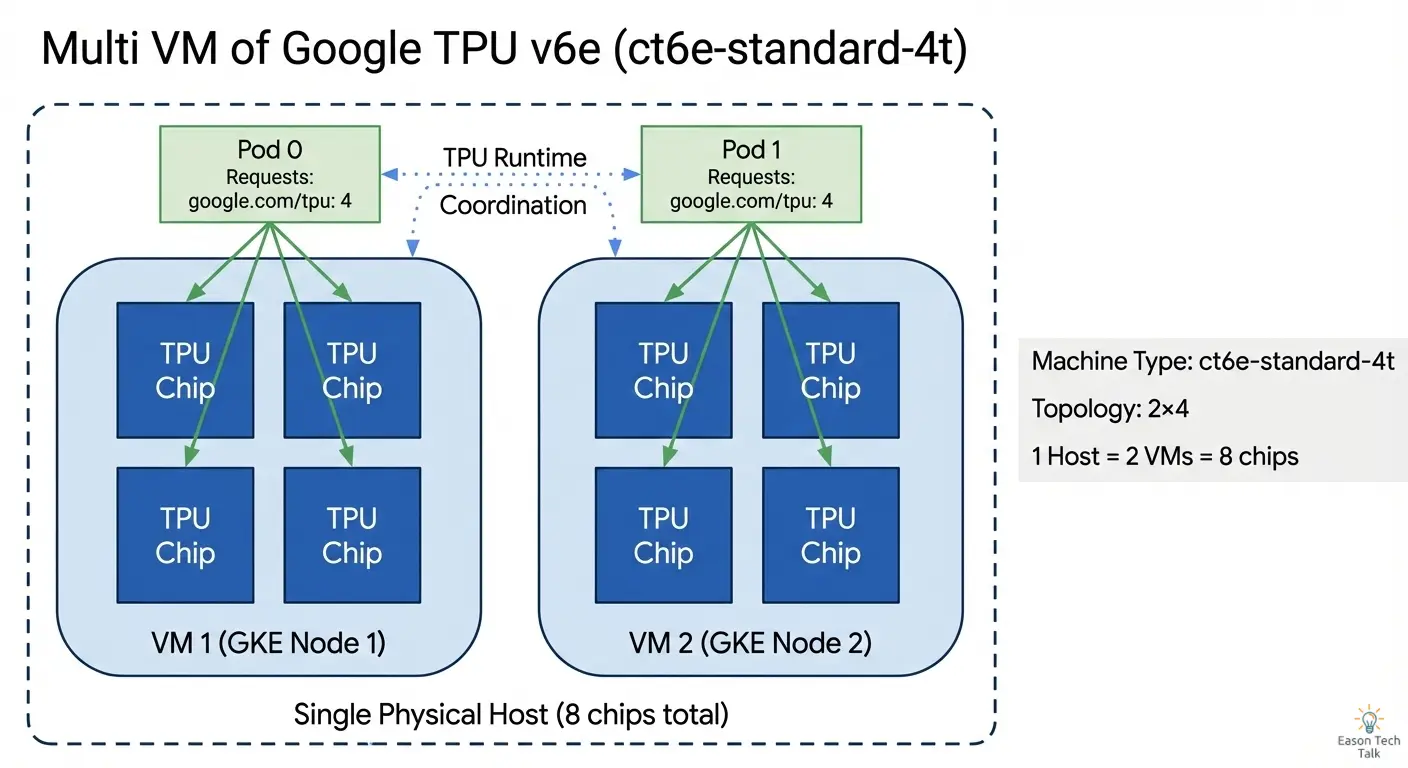
在 2x2 配置中,VM 的程式可以與全部 4 顆晶片互通。在 2x4 的多 VM 配置中,每台 VM 只看得到自己的 4 顆晶片,但 TPU runtime 會協調兩台 VM,把它們呈現成一個整體的 8 顆晶片系統。
這為什麼重要?
在 GKE 中,每個 VM 都是一個獨立的節點。對於 2x4 的多主機配置,你需要跨 2 個節點請求資源,而不是只用 1 個節點。
下表整理了不同拓樸對應的機器類型,以及你的工作負載需要多少 GKE 節點:
| 拓樸 | 機器類型 | TPU 晶片總數 | TPU 主機 | 範圍 | TPU VM | 需要幾個 GKE 節點? |
|---|---|---|---|---|---|---|
| 1x1 | ct6e-standard-1t | 1 | 1/4 | 子主機 | 1 | 1 |
| 2x2 | ct6e-standard-4t | 4 | 1/2 | 子主機 | 1 | 1 |
| 2x4 | ct6e-standard-4t | 8 | 1 | 單一主機 | 2 | 2 |
| 2x4 | ct6e-standard-8t | 8 | 1 | 單一主機 | 1 | 1 |
搞清楚這個對應關係很重要,因為你在設定節點集區時,必須確保叢集有足夠節點來符合你的拓樸需求。
2. 建立 GKE 叢集
現在我們已經了解 TPU 拓樸與機器類型,接下來就一步步實際部署。
我們會用 2x4 拓樸(8 顆晶片)跑一個小型訓練工作。首先建立一個標準 GKE 叢集,並為 TPU 新增專用節點集區。
CLUSTER_NAME=tpu-quickstart # Name of the GKE cluster
CONTROL_PLANE_LOCATION=us-central1 # Ensure you use region have v6e supported, see: https://docs.cloud.google.com/tpu/docs/regions-zones
gcloud container clusters create $CLUSTER_NAME --location=$CONTROL_PLANE_LOCATION
3. 建立 Flex-Start 節點集區
接著新增一個專門給 2x4 TPU 工作負載的節點集區。這個節點集區會使用 Flex-Start 佈建模型,確保在需求高峰時也能排隊取得 TPU 容量。
NODE_POOL_NAME=nodepool # Name of the GKE node pool
NODE_ZONES=us-central1-b # Ensure you use zone have v6e supported, see: https://docs.cloud.google.com/tpu/docs/regions-zones
gcloud container node-pools create $NODE_POOL_NAME \
--cluster=$CLUSTER_NAME \
--location=$CONTROL_PLANE_LOCATION \
--node-locations=$NODE_ZONES \
--machine-type=ct6e-standard-4t \
--tpu-topology=2x4 \
--reservation-affinity=none \
--enable-autoscaling \
--num-nodes=0 --min-nodes=0 --max-nodes=2 \
--flex-start
這裡 --flex-start 很重要,它會讓 GKE 使用 Flex-Start 佈建模型:資源不足時不會直接失敗,而是排進佇列,等有資源再佈建。
重點參數說明:
--tpu-topology=2x4:指定 TPU 晶片的邏輯排列(2×4,共 8 顆晶片)--machine-type=ct6e-standard-4t:每個節點可使用 4 顆 TPU 晶片--enable-autoscaling搭配--num-nodes=0:起始 0 節點,只在有工作負載時擴縮--max-nodes=2:2×4 拓樸需要 2 個 VM(節點),因此最大節點數要設成 2
注意:若使用 ct6e-standard-4t 且 --max-nodes=1,就只能取得 4 顆晶片,結果會變成 2x2 拓樸,而不是 2x4。
佈建模型:Flex-Start
因為 TPU 是有限資源,當 Google 機器不足時,部署失敗是很常見的痛點。Flex-Start 是用來降低這個問題的特殊模式。
| 特性 | 標準隨用隨付 | Flex-Start |
|---|---|---|
| 成本 | 標準價格 | 折扣(通常約 6 折) |
| 可用性 | 立即(若有資源) | 較高機率(加入佇列) |
4. 執行批次工作負載
現在叢集與節點集區都準備好了,我們來部署一個簡單的訓練工作負載。
我們會建立一個 Job 來排程使用 Flex-Start VM 的 TPU 節點。Kubernetes 的 Job controller 會建立一或多個 Pod,並確保它們完成指定任務。
以下是一個簡單的 YAML,示範如何在 TPU 節點集區上部署訓練工作:
apiVersion: v1
kind: Service
metadata:
name: headless-svc
spec:
clusterIP: None
selector:
job-name: tpu-training-job
---
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-training-job
spec:
backoffLimit: 0
completions: 2
parallelism: 2
completionMode: Indexed
template:
spec:
subdomain: headless-svc
restartPolicy: Never
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x4
containers:
- name: tpu-job
image: us-docker.pkg.dev/cloud-tpu-images/jax-ai-image/tpu:latest
ports:
- containerPort: 8471 # Default port using which TPU VMs communicate
- containerPort: 8431 # Port to export TPU runtime metrics, if supported.
securityContext:
privileged: true
command:
- bash
- -c
- |
python -c 'import jax; print("TPU cores:", jax.device_count())'
resources:
requests:
google.com/tpu: 4
limits:
google.com/tpu: 4
當你用 ct6e-standard-4t 建立 2x4 拓樸的節點集區時,GKE 會佈建 2 個獨立節點(VM),每個節點各有 4 顆 TPU 晶片。
google.com/tpu: "4" 的資源請求會讓 GKE 把 Job 排程到具備 4 顆 TPU 晶片的節點,正好符合我們的 2x4 拓樸。搭配 parallelism: 2,兩個 Job 會平行執行——各跑在一個節點上。當你套用這個 manifest 時,若節點尚未啟動,GKE 的 autoscaler 會自動從 Flex-Start 節點集區佈建所需節點。
從 Kubernetes 的角度看節點排程
來看看 Kubernetes 眼中的結果。先用以下指令查看節點:
kubectl get nodes -o wide
你會看到類似的輸出:
NAME STATUS ROLES AGE VERSION
gke-cluster-tpu-pool-a1b2c3d4-node-1 Ready <none> 5m v1.28.3-gke.1234
gke-cluster-tpu-pool-a1b2c3d4-node-2 Ready <none> 5m v1.28.3-gke.1234
要查看這些節點上的 TPU 標籤,可用:
kubectl get nodes -l cloud.google.com/gke-tpu-topology=2x4 -o json | jq '.items[].metadata.labels'
你會看到像這樣的標籤:
{
"cloud.google.com/gke-tpu-accelerator": "tpu-v6e-slice",
"cloud.google.com/gke-tpu-topology": "2x4",
"google.com/tpu": "4",
...
}
重點觀察:
- 加速器標籤:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice用來辨識 TPU 世代。這個標籤是 GKE Autopilot 的枚舉設定之一,文件可參考 Plan TPUs on GKE 3(Validate TPU availability in GKE > Autopilot)。 - 兩個獨立節點: 2x4 拓樸搭配
ct6e-standard-4t會產生 2 個 Kubernetes 節點 - 每個節點 4 顆晶片:
google.com/tpu: "4"表示每個節點可用的 TPU 資源 - 相同拓樸標籤: 兩個節點都有
cloud.google.com/gke-tpu-topology: 2x4標籤
把工作負載排到兩個節點上
要使用完整的 2x4 拓樸(8 顆晶片),你的 Job 必須把 Pod 分散到兩個節點。因此我們在 Job manifest 裡設定 parallelism: 2 與 completions: 2:一個 Pod 對應一個節點。
排程流程如下:
- Job 建立 2 個 Pod:
completionMode: Indexed會為每個 Pod 指定唯一索引(0 與 1) - 每個 Pod 請求 4 顆晶片: 資源請求為
google.com/tpu: "4" - NodeSelector 符合拓樸:
cloud.google.com/gke-tpu-topology: 2x4確保 Pod 排到正確節點集區 - 排程器分配 Pod: Kubernetes 會把每個 Pod 放到不同節點上,滿足資源需求
你可以用以下指令確認 Pod 的位置:
kubectl get pods -o wide
你應該會看到:
NAME READY STATUS NODE
tpu-training-job-0-abc 1/1 Running gke-cluster-tpu-pool-a1b2c3d4-node-1
tpu-training-job-1-def 1/1 Running gke-cluster-tpu-pool-a1b2c3d4-node-2
-0 和 -1 的尾碼來自 Indexed completion mode,每個 Pod 跑在不同節點上,讓你用滿 2x4 拓樸的 8 顆晶片。
5. 檢查訓練工作
部署完成後,可以監控執行情況並確認 TPU 資源是否正確使用。以下示範如何查看 Job 狀態與日誌。
確認 Job 狀態
先確認 Job 是否已建立並正在執行:
kubectl get jobs
你會看到類似的輸出:
NAME COMPLETIONS DURATION AGE
tpu-training-job 0/2 5s 5s
COMPLETIONS 顯示 0/2,代表 2 個 Pod 目前還沒完成。當兩個 Pod 都成功結束後,會顯示 2/2。
查看 Pod 日誌
要看訓練輸出,分別查看各 Pod 的日誌:
kubectl logs tpu-training-job-0-<pod-suffix>
kubectl logs tpu-training-job-1-<pod-suffix>
你應該會看到 JAX 偵測到 TPU 核心數量的輸出:
TPU cores: 4
每個 Pod 都看到 4 顆 TPU 核心,因為它們各自跑在有 4 顆晶片的節點上。合起來就是 2x4 拓樸的 8 顆晶片。
常見問題排查
如果 Pod 一直停在 Pending,可以查看事件:
kubectl describe pod tpu-training-job-0-<pod-suffix>
常見原因包含:
- TPU 資源不足: Flex-Start 節點集區仍在佈建,可能需要幾分鐘
- Node selector 不符合: 確認 nodeSelector 標籤是否與節點標籤一致
- 資源配額超限: 檢查專案的 TPU 配額
Bonus:在單一主機啟動 8 顆晶片(單一 VM)
如果你希望把所有 TPU 晶片集中在單一 VM,也可以用更大的機器類型配置 2x4 拓樸。
原本使用 ct6e-standard-4t 時會產生 2 台 VM、各 4 顆晶片;改用 ct6e-standard-8t 則可以在單一 VM 上拿到全部 8 顆晶片:
# Create TPU node pool for zonal cluster "my-cluster" in us-central2-b
gcloud container node-pools create tpu-pool \
--cluster=my-cluster \
--location=us-central2-b \
--node-locations=us-central2-b \
--machine-type=ct6e-standard-8t \
--tpu-topology=2x4 \
--reservation-affinity=none \
--enable-autoscaling \
--num-nodes=0 \
--min-nodes=0 \
--max-nodes=1 \
--flex-start
主要差異:
- 機器類型:
ct6e-standard-8t取代ct6e-standard-4t - 最大節點數:
--max-nodes=1,因為只需要 1 台 VM - 只有一個 Kubernetes 節點:
kubectl get nodes只會看到一個節點 - 可使用全部 8 顆晶片: 單一 Pod 即可存取 8 顆晶片
更新 Job manifest,把兩個 Pod 改成一個 Pod:
apiVersion: batch/v1
kind: Job
metadata:
name: tpu-training-job-single-host
spec:
backoffLimit: 0
completions: 1
parallelism: 1
template:
spec:
restartPolicy: Never
nodeSelector:
cloud.google.com/gke-tpu-accelerator: tpu-v6e-slice
cloud.google.com/gke-tpu-topology: 2x4
containers:
- name: tpu-job
image: us-docker.pkg.dev/cloud-tpu-images/jax-ai-image/tpu:latest
securityContext:
privileged: true
command:
- bash
- -c
- |
python -c 'import jax; print("TPU cores:", jax.device_count())'
resources:
requests:
google.com/tpu: 8
limits:
google.com/tpu: 8
這種配置更簡單,原因是:
- 只需要管理一個 Pod,不必協調多個 Pod
- 不需要 headless Service 來做 Pod 之間的通訊
- 除錯更方便,所有日誌都集中在同一個 Pod
不過,多 VM 的方式(ct6e-standard-4t)在需要精細控制 VM 之間的分散式訓練時,更有彈性。
結語
這篇文章完整走過在 GKE 上使用 TPU v6e 執行第一個 JAX 訓練工作的流程。我們涵蓋了建立 GKE 叢集、設定 Flex-Start 的 TPU 節點集區、部署訓練 Job,以及理解 Kubernetes 如何在 TPU 節點間排程工作負載。不論你選擇多 VM 來取得分散式訓練的彈性,或是單一 VM 追求設定上的簡單,GKE 都能支援你的 ML 工作負載,從實驗原型一路擴展到生產環境。
參考資料
