JobSet:讓 Kubernetes 真正駕馭多 Job 工作負載
一句話理解 JobSet: 如果 Kubernetes Job 是「單兵作戰」,JobSet 就是「協同作戰的整支部隊」,一個 API 物件,統一管理多組 Job 的生命週期、網路與故障恢復。
為什麼要用 JobSet?不是已經有 Kubernetes Job API 了嗎?
Kubernetes 原生 Job 的設計假設是:一個 Job = 一個獨立的批次任務。但現實中的分散式工作負載遠比這複雜。
以大型模型訓練為例,你可能同時需要:
- Parameter Server — 儲存與同步模型權重
- Worker Node — 並行處理訓練資料
- Coordinator — 控制訓練流程與 checkpoint
如果用原生 Job 分別建立,你必須自行處理:
- 多個 Job 的啟動順序與依賴
- 跨 Job 的 Pod 間網路發現
- 任一 Job 失敗後的全域重啟邏輯
這就像試圖用三個獨立的 crontab 來編排一場交響樂——技術上可行,但維運成本極高。
JobSet 把這些協調邏輯內建到一個 CRD 裡,讓你只需要描述「我要什麼」,而非「怎麼串起來」。
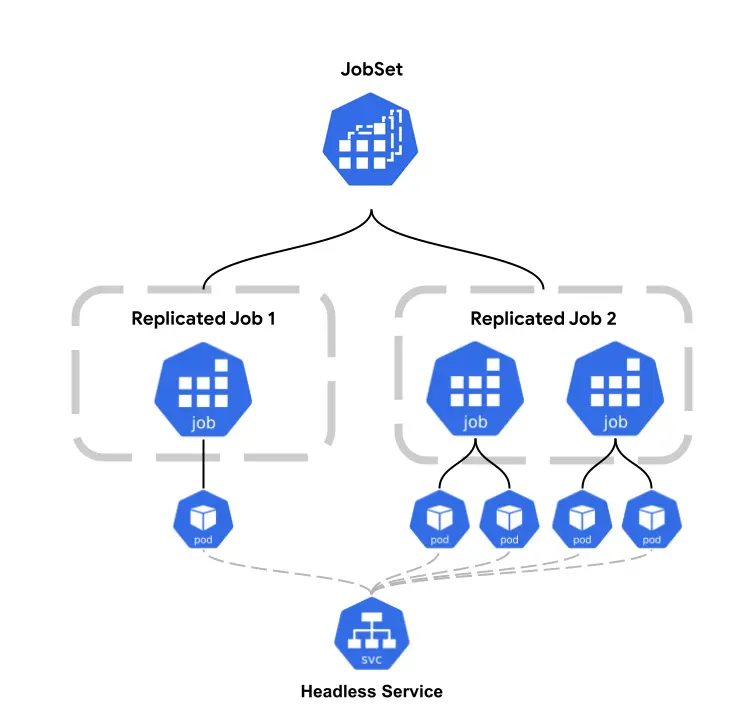 (圖片來源:JobSet Conceptual Diagram)
(圖片來源:JobSet Conceptual Diagram)
核心能力一覽
| 能力 | 做了什麼 | 為什麼重要 |
|---|---|---|
| ReplicatedJob 分組 | 在同一個 JobSet 裡定義多組 Job,各自擁有獨立的 Pod Template 與副本數 | 一個 YAML 即可描述多個相關聯的任務而不是拆成個別的 Job 管理 |
| 協調式生命週期 | 所有 Job 共同啟動,JobSet 追蹤整體成功/失敗 | 避免「半成品」狀態:不會出現 worker 跑完但 PS 還沒啟動的窘境 |
| 自動建立 Headless Service | 為每個 ReplicatedJob 建立 headless Service,Pod 可透過可預測的 DNS 互相發現 | PyTorch torchrun、TensorFlow MultiWorkerMirroredStrategy 等框架可直接使用 |
| 靈活的失敗策略 | 支援 FailJobSet 屬性(任一 Job 失敗即全域重啟)或選擇性容忍個別失敗 | 在「訓練一致性」與「容錯彈性」之間自由取捨 |
典型使用場景
🧠 分散式 ML 訓練(最熱門場景)
大規模模型訓練——無論是 Parameter Server 架構還是 Data-Parallel ——都需要多個角色的 Pod 同時運行並互相通訊。JobSet 天然支援這種多角色拓撲,搭配 Kueue 可進一步實現 GPU/TPU 資源的排隊與公平調度。
🔬 HPC 與科學計算
MPI 應用需要所有 rank 在可預測的網路位址上同時啟動。JobSet 的 headless Service + coordinated startup 正好解決這個痛點。
🔄 多階段資料處理
ETL pipeline 中「抽取 → 轉換 → 載入」的不同 worker 群組可以封裝在同一個 JobSet 內,共享生命週期管理。
實際範例:大規模日誌分析系統
讓我們用一個實際範例來理解為什麼需要 Leader-Worker 架構。以 Apache Spark 分散式資料處理為例,假設你需要處理每天產生的 TB 級網站存取日誌,進行即時異常偵測與統計分析。這個工作負載天然需要 Leader-Worker 架構:
為什麼需要 Leader(Driver)?
- 任務分配與協調:Driver 負責將大型資料集切分成小塊,分配給不同的 Worker 處理
- 狀態追蹤:監控哪些資料塊已處理完成、哪些失敗需要重試
- 結果彙總:收集各 Worker 的處理結果,進行最終的聚合計算(如統計 95th percentile 回應時間)
- 資源管理:動態調整 Worker 數量,處理反壓(backpressure)情況
為什麼需要多個 Worker?
- 平行處理:100 個 Worker 同時處理不同的資料分片,大幅縮短處理時間
- 資源隔離:每個 Worker 處理自己的資料子集,避免記憶體競爭
- 容錯能力:單一 Worker 失敗不影響其他 Worker,Leader 可重新分配該任務
架構示意
┌─────────────────────────────────────────┐
│ Leader (Spark Driver) │
│ - 讀取任務設定 │
│ - 切分資料成 1000 個分片 │
│ - 分配給 Worker 處理 │
│ - 追蹤進度:652/1000 完成 │
└──────────────┬──────────────────────────┘
│
┌──────────┼──────────┬──────────┐
│ │ │ │
┌───▼───┐ ┌──▼────┐ ┌──▼────┐ ┌──▼────┐
│Worker1│ │Worker2│ │Worker3│ │Worker4│
│處理 │ │處理 │ │處理 │ │處理 │
│分片1-25│ │分片26 │ │分片51 │ │分片76 │
│ │ │ -50 │ │ -75 │ │ -100 │
└───────┘ └───────┘ └───────┘ └───────┘
真實世界的挑戰
- 網路相依性:Worker 需要知道 Leader 的位址才能回報進度(
LEADER_HOST環境變數) - 啟動順序:Leader 必須先啟動並準備好接收連線,Worker 才能開始工作
- 失敗處理:如果 Leader 掛了,整個任務都要重來;如果只是 Worker 掛了,Leader 可以重新分配該部分工作
- 資源爭奪:在 Kubernetes 中,如何確保 Leader 和 Worker 的 Pod 能同時取得足夠資源?
這就是 JobSet 的價值所在:
原生 Job 無法表達「Leader 必須先啟動,且 Worker 需要透過穩定的 DNS 名稱找到它」這種拓撲關係。你需要自己寫 init container、readiness probe、手動建立 Service——這些都是重複且容易出錯的工作。
JobSet 透過 replicatedJobs + 自動 headless Service,讓你用 20 行 YAML 就能描述這個架構,而非 200 行的手動配置。
其他常見的 Leader-Worker 使用場景
- 機器學習訓練:Parameter Server (Leader) 儲存模型參數,Worker 計算梯度並回傳更新
- 爬蟲系統:Coordinator (Leader) 管理待爬取 URL 佇列,Worker 執行實際的網頁下載與解析
- 影片轉檔:Orchestrator (Leader) 切分影片片段,Worker 平行處理不同時間段的編碼工作
- 基因定序分析:Master (Leader) 協調基因序列比對任務,Worker 執行計算密集的比對演算法
在 Kubernetes 中運行的 Leader-Worker 架構
如果今天使用 Job,你需要手動管理 Service、協調啟動順序,並且在任一 Job 失敗時自行處理清理與重啟邏輯:
apiVersion: batch/v1
kind: Job
metadata:
name: worker-job
spec:
template:
spec:
containers:
- name: worker
image: bash:latest
command: ["bash", "-xc", "sleep 1000"]
env:
- name: LEADER_HOST
value: "leader-service"
restartPolicy: Never
---
apiVersion: batch/v1
kind: Job
metadata:
name: leader-job
spec:
template:
spec:
containers:
- name: leader
image: bash:latest
command: ["bash", "-xc", "echo 'Leader is running'; sleep 1000"]
restartPolicy: Never
---
apiVersion: v1
kind: Service
metadata:
name: leader-service
spec:
selector:
job-name: leader-job
ports:
- port: 8080
如果使用 JobSet:不僅能一次定義 Leader 與 Worker,還能透過 failurePolicy 針對特定角色進行錯誤處理(例如:Leader 失敗時,直接 FailJobSet 中止任務)。
apiVersion: jobset.x-k8s.io/v1alpha2
kind: JobSet
metadata:
name: failjobset-action-example
spec:
failurePolicy:
maxRestarts: 3
rules:
# 當 leader job 失敗時,JobSet 會立刻標記為失敗
- action: FailJobSet
targetReplicatedJobs:
- leader
replicatedJobs:
- name: leader
replicas: 1
template:
spec:
# 設為 0 確保如果任何 pod 失敗,job 立即失敗
backoffLimit: 0
completions: 2
parallelism: 2
template:
spec:
containers:
- name: leader
image: bash:latest
command:
- bash
- -xc
- |
echo "JOB_COMPLETION_INDEX=$JOB_COMPLETION_INDEX"
if [[ "$JOB_COMPLETION_INDEX" == "0" ]]; then
for i in $(seq 10 -1 1)
do
echo "Sleeping in $i"
sleep 1
done
exit 1
fi
for i in $(seq 1 1000)
do
echo "$i"
sleep 1
done
- name: workers
replicas: 1
template:
spec:
backoffLimit: 0
completions: 2
parallelism: 2
template:
spec:
containers:
- name: worker
image: bash:latest
command:
- bash
- -xc
- |
sleep 1000
🔍DNS 發現範例: Worker Pod 可透過 leader-0.failjobset-action-example.default.svc.cluster.local 直接連線到 Leader,無需額外的 Service 定義。
綜合對照表:原生 Job vs JobSet
| 比較維度 / 工作流程 | 原生 Job | JobSet |
|---|---|---|
| 1. 角色拓撲定義 | 單一角色;需為 Leader 和 Worker 寫獨立 YAML 並手動管理 | 支援多角色;單一 Manifest 內定義多組角色與副本 |
| 2. 網路服務與發現 | ❌ 手動建立 Service 與 DNS,需自行注入環境變數 | ✅ 自動建立 Headless Service;透過穩定 DNS 直接連線 |
| 3. 啟動順序協調 | 需寫 init container/readiness probe 確保 Leader 先啟動 | ✅ 內建協調啟動;自動處理多角色的依賴關係 |
| 4. 失敗處理策略 | ❌ 各 Job 獨立失敗;需自行寫腳本偵測並重啟關聯 Job | ✅ 全域/針對性 FailurePolicy;支援 Leader 失敗全域重啟 |
| 5. 監控與清理 | 需分別查看多個 Job;刪除時需逐一清除 Job/Service | ✅ 單一物件管理;一鍵查看與自動回收所有關聯資源 |
| 6. 開發與維護成本 | 高(維護多個 YAML 與關聯腳本,難以滿足複雜需求) | 極低(純 YAML 宣告式定義) |
| 7. 社群生態支援 | Kubernetes 核心 | SIG Scheduling 官方子專案(能整合 Kueue 進行更進階的 Pod 調度) |
開始使用 JobSet
0. 安裝前置條件 (Prerequisites)
- 一個運行中且版本為最近三個次要版本之一的 Kubernetes 叢集。
- 資源要求:叢集中至少需要一個節點擁有 2+ CPU 與 512+ MB 記憶體,供 JobSet Controller Manager 運行(在某些雲端環境下,預設節點類型可能資源不足,請特別留意)。
- 已安裝並配置好連線的
kubectl,或選擇使用helm。
1. 安裝 JobSet CRD 與 Controller
你可以根據需求選擇使用 kubectl 或 Helm 來安裝,你可以選擇指定固定版本(例如 v0.10.1)以確保生產環境的穩定性:
方法 A:使用 kubectl
VERSION=v0.10.1
kubectl apply --server-side -f https://github.com/kubernetes-sigs/jobset/releases/download/$VERSION/manifests.yaml
方法 B:使用 Helm
VERSION=v0.10.1
helm install jobset oci://registry.k8s.io/jobset/charts/jobset \
--version $VERSION \
--create-namespace \
--namespace=jobset-system
2. 撰寫 JobSet Manifest
根據你的需求撰寫 YAML,定義你的 ReplicatedJob 群組、副本數、以及對應的 Pod Template(如上方的 Leader-Worker 架構範例)。
以下為一個簡易的 jobset.yaml 範本:
apiVersion: jobset.x-k8s.io/v1alpha2
kind: JobSet
metadata:
name: coordinator-example
spec:
# label and annotate jobs and pods with stable network endpoint of the designated
# coordinator pod:
# jobset.sigs.k8s.io/coordinator=coordinator-example-driver-0-0.coordinator-example
coordinator:
replicatedJob: driver
jobIndex: 0
podIndex: 0
replicatedJobs:
- name: workers
template:
spec:
parallelism: 4
completions: 4
backoffLimit: 0
template:
spec:
containers:
- name: sleep
image: busybox
command:
- sleep
args:
- 100s
- name: driver
template:
spec:
parallelism: 1
completions: 1
backoffLimit: 0
template:
spec:
containers:
- name: sleep
image: busybox
command:
- sleep
args:
- 100s
3. 部署到叢集
kubectl apply -f jobset.yaml
4. 監控與除錯
一旦部署,你可以使用以下指令來追蹤任務進度:
- 查看 JobSet 整體狀態:
kubectl get jobsets - 查看特定 JobSet 的詳細事件與狀態:
kubectl describe jobset <name> - 觀察底層建立出來的 Jobs:
kubectl get jobs -l jobset.sigs.k8s.io/jobset-name=<name>
總結
JobSet 的設計,標誌著 Kubernetes 從「無狀態微服務編排」正式跨入「複雜分散式拓撲」的成熟階段。它並非取代原生 Job,而是精準補足了多節點、異質角色(如 Leader-Worker、Parameter Server)協同運作的拼圖。
透過建立這一層宣告式的協調層,工程團隊終於能從繁瑣的啟動順序、DNS 發現與錯誤重試腳本中解放。特別是在搭配 Kueue 進行 GPU/TPU 等昂貴運算資源的進階調度時,JobSet 讓你只需專注於描述「要什麼」,而非痛苦地處理「怎麼串」——這才是 Kubernetes 真正該有的優雅模樣。
如果你正在 Kubernetes 上建構下一代 AI 訓練平台或大規模資料處理管線,JobSet 絕對是不可或缺的核心基礎架構。
