
深入解析 Amazon EKS CNI 外掛在快速擴縮期間的 IP 配置難題
想像這樣一個場景:看似平常的星期五午後,生產環境突然爆發重大事件,背後牽扯出一連串複雜的 IP 配置失敗,甚至可能把整個 Kubernetes 叢集拖垮。這篇文章會深入拆解 CNI 外掛設定裡容易被忽略的風險,還原一場幾乎演變成災難的擴縮事件,並整理出避免 IP 耗盡的實務做法。跟著我一起釐清 failed to assign an IP address 這類錯誤背後真正的原因,看看要怎麼讓你的 EKS 基礎設施避開同樣的坑。
概覽
深入解析 Amazon EKS CNI 外掛在快速擴縮期間的 IP 配置難題
├── 事情是怎麼開始的
│ └── 難以判讀的錯誤
├── AWS VPC CNI 外掛
│ ├── Amazon VPC CNI 的 IP 配置流程
│ ├── 重要設定參數
│ └── 為什麼 warm pool 設太低,會在突發擴縮時出問題
│ ├── API 節流問題
│ └── 效能瓶頸
├── 實際觀察與事件分析
│ ├── GitHub issue 分析(warm pool 設定過低)
│ └── 生產事故案例(子網路可用 IP 不足)
├── 多數文件沒有說清楚的事
│ ├── 先看懂訊息(no free IP available in the prefix)
│ ├── 等一下,原來有 IP 冷卻期?
│ └── Pod IP 指派與 hydration
├── 冷卻期帶來的挑戰
│ └── WARM_IP_TARGET 的迷思
├── 長期解法
│ ├── VPC 設計改善
│ ├── 快速擴縮的建議設定
│ ├── Prefix Delegation 模式
│ ├── 監控與可觀測性
│ └── FAQ
├── 重點整理
├── 結論
└── 致謝
事情是怎麼開始的
某個星期五午後,一位主管傳訊息給我:
Hey, I have a critical case that needs your help.
不到 30 分鐘,我就開始接手一個已經驚動管理層的高優先級案件。客戶的 EKS 生產環境正在出事,而我在和相關人員同步狀況的同時,也被安排參加當天下午稍晚的客戶會議。
在準備會議之前,我先看了內部 COE 報告和來回溝通紀錄。問題很快浮現:客戶在一次大規模部署過程中撞上了 IP 配置限制。雖然當下我還無法只靠快速瀏覽就直接鎖定根因,但我已經能確定,這是一個和 CNI IP 配置行為有關的 IP 耗盡問題。
也因為這次機會,我得以深入研究一個相當有意思的生產案例。快速擴縮需求和 CNI 外掛的行為交錯在一起,讓這起事件成為一個很值得拆解的案例,也帶出了不少和 EKS IP 資源管理有關的重要經驗。以下就是我最後整理出的觀察。
難以判讀的錯誤
最一開始的事故,是由 InsufficientFreeAddressesInSubnet 觸發的。這個訊息很直白,表示子網路裡已經沒有足夠的可用 IP 可供 CNI 外掛配置。客戶因此嘗試調整 WARM_IP_TARGET,希望能釋放出更多 IP。不過,這樣做不一定真的對症下藥。如果子網路本身已經耗盡,只調 WARM_IP_TARGET 並不能解決根本問題。真正要處理的是:先搞清楚 CNI 外掛如何配置 IP,然後再搭配正確的設定策略一起調整。
在多次調整參數之後,客戶一度把 WARM_IP_TARGET 改回預設值 0,子網路 IP 耗盡的情況暫時緩解;但從 Kubernetes event 與日誌系統來看,仍然持續出現 IP 配置錯誤:
add cmd: failed to assign an IP address to container
當出現 "add cmd: failed to assign an IP address to container" 這個訊息時,代表 Amazon VPC CNI 外掛無法替 Pod 配到新的 IP。常見原因包括外掛本身沒有正常運作,或者像這個案例一樣,節點掛載的 Elastic Network Interface(ENI)已經沒有可用 IP 可分配。CNI 外掛仰賴掛在 EC2 執行個體上的 ENI 與其 secondary IP,才能把 IP 指派給 Pod;一旦用完,新的 Pod 就拿不到 IP,於是就會看到這個錯誤。
在我加入調查之前,我的同事已經先從日誌裡找到下面這兩行:
Get free IP from prefix failed no free IP available in the prefix - 172.28.15.192/ffffffff
Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.15.192/ffffffff
他當時判斷,客戶應該是因為 Prefix Delegation 需要的連續 /28 區塊不足,才導致 IP 配置失敗,因此也提供了調整 IP 區塊的建議,希望能避開這類錯誤。
但在我重新看過內部報告後,發現客戶其實根本還沒有啟用 Prefix Delegation。更有意思的是,我快速看了原始碼之後才發現,這段訊息其實不算真正的錯誤。這個誤解很常見,而且也確實誤導過不少人,後面我會解釋原因。
到這裡,我就更想知道背後到底發生了什麼。會議中,團隊讓我快速看了部分 log。我注意到 warm pool 並沒有積極補充可用 IP,而日誌看起來也不像只是單純的「IP 用光」那麼簡單。根據我過去處理類似案例的經驗,我懷疑問題點可能卡在 CNI 配置 IP 的節奏,和工作負載擴縮模式之間的交互影響。於是我請對方提供日誌蒐集資料,開始往下分析。
不過在進入日誌細節之前,先快速看一下 AWS VPC CNI 外掛到底是怎麼運作的。
AWS VPC CNI 外掛
AWS VPC CNI(Container Network Interface)外掛,是 Amazon EKS 叢集中負責 Pod 網路的核心元件。它處理 Pod 的 IP 配置、ENI 管理,以及 Pod 在 EC2 執行個體上的網路連線。要排查 IP 配置問題、或是優化叢集效能,先理解它的設計與運作方式非常重要。
Amazon VPC CNI 外掛的核心,主要由兩個元件協同工作,負責完成 Pod 網路配置:
- CNI Binary:位於
/opt/cni/bin/aws-cni,當節點上有 Pod 被建立或刪除時,由 kubelet 呼叫 - ipamd Daemon:常駐在本機的 IP Address Management daemon,負責管理 ENI,以及維持可立即使用的 warm pool IP
AWS VPC CNI 外掛是依照 Kubernetes 的 Container Networking Interface(CNI)規範來實作的。雖然規範裡定義了多種操作,但在這裡最重要的是兩個:ADD 和 DEL。
- ADD:Pod 建立時,kubelet 會呼叫 CNI binary,發出
ADD,要求建立網路。binary 會和ipamd溝通,取得 IP,並完成 Pod 網路介面的設定。 - DEL:Pod 刪除時,kubelet 會呼叫 CNI binary,發出
DEL。binary 會通知ipamd釋放 IP,並清理網路設定。
Amazon VPC CNI 的 IP 配置流程
當 Pod 被排程到某台節點時,CNI binary 會透過 gRPC 向 ipamd 申請 IP。ipamd 會管理節點上已掛載的 ENI 與其 IP,並維持一個 warm pool,讓節點手邊隨時有一批可以立刻指派給 Pod 的 IP。如果快取中已經沒有可用 IP,這次請求就會失敗,進而觸發 IP 配置錯誤。
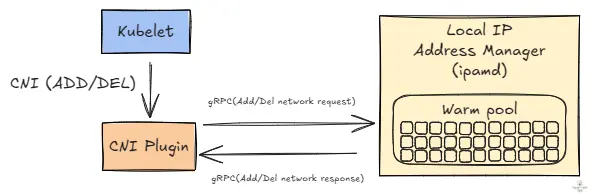
為什麼 AWS VPC CNI 外掛需要 warm pool
warm pool 的存在很關鍵,因為它可以先把 IP 準備好,降低 Pod 啟動延遲,也能在流量平靜時分散 EC2 API 呼叫,減少擴縮當下被節流的風險,同時為突發擴縮預留緩衝空間。
如果你希望 Kubernetes Pod 在 AWS 環境中使用獨立的私有 IP,並且保有原生 VPC 網路效能,CNI 外掛就會直接利用 VPC 與 EC2 的原生網路能力。每個 Pod 都會透過 Elastic Network Interface(ENI) 參與網路通訊,因此可以選擇性存取 Internet,也能連到像 RDS、DynamoDB 這類 AWS 私有資源。Pod 使用的私有 IP,則是從 ENI 上配置的 secondary IP 中取得。
但這種設計也有代價。因為 CNI 外掛必須在 ENI 層處理 IP 配置,所以 warm pool 要怎麼維持、要怎麼補 IP,都變得比較複雜。每種執行個體類型都有自己的 ENI 數量上限與每張 ENI 可掛的 IP 數量,而新增 ENI 或配置 IP 又得透過 EC2 API 完成;這些 API 不但可能被節流(通常會看到 RequestLimitExceeded),延遲也可能從 1 秒一路到數分鐘不等。在快速擴縮時,這些因素就會全部疊在一起。
warm pool 的作用,就是先把一批 IP 準備好,等 Pod 需要時直接取用。這不只可以縮短 Pod 啟動時間,也能在擴縮過程中降低 IP 配置失敗的機率。除此之外,它還能把 ENI 掛載請求分散到平時處理,避免在大批 Pod 同時啟動時,把 EC2 API 壓出一波尖峰。
ENI 限制範例:m5.large
節點上的 IP,是從已掛載到執行個體的 ENI 裡成批取得的。每張 ENI 可支援多少 IP,取決於執行個體類型。以 m5.large 為例,它支援 3 張 ENI,每張可配置 10 個 IP1。理論上總共會有 30 個 IP,但這不代表這台節點就能跑 30 個 Pod。
節點可容納的最大 Pod 數,會用下面這個公式計算:
- 每張 ENI 的第一個 IP 不會分給 Pod,因為 primary IP 會保留給 EC2 host
- 再加上 2 個使用 host network 的 Pod(AWS CNI 和 kube-proxy)
(該執行個體類型的 ENI 數量 * (每張 ENI 的 IP 數量 - 1)) + 2
以 m5.large 來算,結果如下2:
(3 * (10 - 1)) + 2 = 29 pods maximum
這也說明了,為什麼 EKS 在這種執行個體類型上預設的 maxPods 會是 29。規劃節點容量與 warm pool 時,先搞懂這些硬限制非常重要。當然,若你使用 Prefix Delegation,這個計算方式就不再適用。
另外,雖然我們知道 m5.large 最多能跑 29 個 Pod,但不代表 AWS VPC CNI 外掛就應該一口氣配置 29 個 IP。大部分情況下,一台節點不會真的跑到這麼多 Pod,因此沒必要提早把子網路裡的 IP 全部吃掉。CNI 外掛本來就是依需求逐步配置 IP。
理解這個背景之後,就比較容易看出:外掛真正做的事情,是在「保留子網路裡的可用 IP」和「維持 warm pool 讓 Pod 能快啟動」之間取得平衡。
重要設定參數
AWS VPC CNI 外掛有幾個很關鍵的設定參數,會直接影響 IP 配置行為與 warm pool 管理方式。這些參數彼此之間會互相影響,重點在於找到平衡點:設太低,遇到擴縮時容易配不到 IP;設太高,則可能多占用一些私有 IP。不過如果你的 Pod 本來就用專用子網路,這種額外占用通常問題不大。下面逐一說明。
WARM_ENI_TARGET(預設值:1)
- 定義:希望節點額外保留幾張已掛載但尚未使用的 ENI,每張 ENI 都會附帶一整組可供 Pod 使用的 IP
- 行為:預設值為 1,代表會多保留一張完整 ENI 的 IP 容量作為 warm pool
- 影響:和以 IP 為單位相比,這種設定可以減少 EC2 API 呼叫次數,但會一次配置較大批的 IP
WARM_IP_TARGET
- 定義:希望在所有已掛載 ENI 上,額外保留多少個可立即使用的 warm IP
- 彈性:可以直接指定 IP 數量,比以 ENI 為單位更細緻
- 覆寫行為:若同時設定
MINIMUM_IP_TARGET,會優先覆蓋WARM_ENI_TARGET的邏輯
MINIMUM_IP_TARGET
- 定義:節點啟動時至少要先配置多少個 IP,系統會為了達到這個目標而預先掛載 ENI
- 用途:相當於設定 IP 配置的基本盤,避免節點一開始可用 IP 太少
- 建議:通常建議設成略高於單一節點預期承載的 Pod 數
為什麼 warm pool 設太低,會在突發擴縮時出問題
當 Pod 在短時間內快速被排程,若這些 warm pool 參數設得太低,就很容易出現 IP 配置失敗。原因在於:warm pool 裡的 IP 太少,Pod 之間就會開始搶資源;而外掛如果這時才同步呼叫 EC2 API 去配置新 ENI 或 IP,速度通常跟不上 Pod 建立的節奏。
API 節流問題
如果 WARM_ENI_TARGET 或 WARM_IP_TARGET 設得太低,CNI 外掛就不會預留足夠的 warm IP。當大量 Pod 突然啟動時,外掛只能同步呼叫 EC2 API 去新增 ENI 或配置更多 IP,這不只會帶來延遲,也可能被 EC2 服務節流。
效能瓶頸
warm target 偏低的叢集,常見瓶頸是 IP 配置速度趕不上 Pod 建立速度。以下情況會讓問題更明顯:
- EC2 API 在高頻率呼叫下遭到限流
- 多台節點同時要求掛載 ENI,而建立與掛載一張新 ENI 最多可能要 10 秒
- IP 冷卻期的影響(後面會細講)
實際觀察與事件分析
這類錯誤在快速擴縮場景下特別容易放大,因為短時間內會有大量 Pod 同時在叢集各節點上排程。實務上,很多生產環境在幾分鐘內部署上百個 Pod 時,就會碰到這個問題,相關 incident report 也有記錄。
GitHub issue 分析(warm pool 設定過低)
GitHub issue #28043 記錄了一個案例:叢集在幾分鐘內部署超過 100 個 Pod 時,會零星出現 IP 配置失敗,而且看到的就是我前面提到的那組 log:
"Get free IP from prefix failed no free IP available in the prefix""Unable to get IP address from CIDR: no free IP available in the prefix"
乍看之下很像子網路的 IP 已經快用完,但實際上子網路還有超過 80% 的可用 IP。真正被耗盡的,是 ENI 內部某些 prefix 可再利用的 IP,這也才導致配置失敗。
生產事故案例(子網路可用 IP 不足)
Neon 團隊分享的一篇生產事故分析4,則更清楚說明了這類問題會有多嚴重。事故發生前,他們使用的是 AWS CNI 預設設定,也就是 WARM_ENI_TARGET=1,且沒有設定 WARM_IP_TARGET。在某次擴縮事件中:
- 每個子網路大約已配置 3.7k 到 3.9k 個 IP,但整體使用率只有約 50%
- 全部子網路合計已配置約 12,200 個 IP,而總可用 IP 僅有 12,273 個,等於整體配置率已達 99%
- 某些節點雖然 CPU 和記憶體都已滿,但仍占著 IP,這些 IP 實際上已經無法被新工作負載利用
- 新節點表面上看似還有空間,卻拿不到足夠的 IP,因此無法順利接手新 Pod
多數文件沒有說清楚的事
先看懂訊息(no free IP available in the prefix)
在和客戶工程團隊一起看 log 時,我就注意到這組訊息一直出現。因為它看起來和 Prefix Delegation 模式常見的 InsufficientCidrBlocks 很像,如果沒有仔細對照 log,很容易往錯的方向查。
在 Prefix Delegation 模式下,外掛會把 /28 CIDR block 指派給節點;但這裡我們看到的是 /32 mask,也就是 ffffffff。這代表目前其實還是在「單一 IP 配置模式」,不是 prefix delegation。這個差異非常重要,因為兩種模式的根因和解法完全不同。
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.15.192/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.15.192/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.119/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.119/ffffffff"}
...
補充一下,當子網路裡沒有足夠的連續 CIDR block 可以給 Prefix Delegation 使用時,常見的訊息其實是:InsufficientCidrBlocks: The specified subnet does not have enough free cidr blocks to satisfy the request。可參考:Increase the available IP addresses for your Amazon EKS node - Amazon EKS
一開始我自己也曾被這段訊息搞混。不過翻了程式碼之後,我才確認:它指的不是子網路層級的 IP 耗盡,而是 CNI 外掛內部 IP 管理流程中的一個狀態。
- 這類 debug 訊息,來自 CNI 外掛內部的 IP 配置流程。外掛會掃描節點上各張 ENI 的
AvailableIPv4Cidrs,尋找還沒指派出去的 IP;找到之後,就把這些可用 secondary IP 記錄到 datastore 裡(可參考:AssignPodIPv4Address)。 - 當 getUnusedIP 在特定 CIDR block 中找不到任何可用 IP 時,就會出現這組訊息。
從程式碼來看,這種情況大致有兩種可能(同樣可參考 getUnusedIP):
- 它會先檢查 datastore 裡,是否有任何已脫離 cooldown period 且尚未被指派的 IP。只要有找到,就回傳第一個可用 IP。
- 如果 cooldown 檢查後還是找不到可用 IP,它才會嘗試在該 CIDR 範圍內生成新的 IP。但這裡 log 裡的 mask 是
ffffffff,也就是十六進位表示的/32。換句話說,這個 CIDR 實際上只是一個單一 IP,而不是一個可再展開的真正 subnet range。
因此,這個訊息出現時,表示某個特定 CIDR block 內的 IP 已經全部被配置出去,或仍處於 cooldown 中,迫使 CNI 外掛繼續掃描其他 ENI,甚至再去申請新的 ENI。下面這組 log 可以看出,外掛在遇到這個狀況時,會持續往其他 ENI 尋找可用 IP:
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.126/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Get free IP from prefix failed no free IP available in the prefix - 172.28.14.119/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"Unable to get IP address from CIDR: no free IP available in the prefix - 172.28.14.119/ffffffff"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:1291","msg":"Found a free IP not in DB - 172.28.12.25"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:687","msg":"Returning Free IP 172.28.12.25"}
...
等一下,原來有 IP 冷卻期?
分析到這裡,我才意識到 CNI 外掛其實有一個很容易被忽略的機制:IP 冷卻期(參數:IP_COOLDOWN_PERIOD)。當某個 Pod 釋放 IP 後,這個 IP 不會立刻重新分配,而是會先進入 30 秒的冷卻期。這個設計原本是為了避免 IP 衝突,但在快速擴縮場景裡,反而可能讓 IP 配置問題更明顯。
在分析客戶的 issue 和 log 時,我就注意到:當 Pod churn 很高、又把 warm IP target 設得太低時,這個 cooldown 機制和 warm pool 補充速度不足就會形成一個很糟的組合。從我看到的案例來說,明明子網路還有足夠空間,多台節點卻還是同時發生 IP 配置失敗。
從 debug log 裡,也確實可以看到 cooldown 機制正在運作。log 會記錄目前 IP 的狀態,包括總 IP 數、已指派 IP 數,以及正在 cooldown 的 IP 數量。這也解釋了為什麼「整體 IP 看起來還夠」,但其中一部分短時間內其實不能再用:
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"ipamd/ipamd.go:661","msg":"IP stats - total IPs: 100, assigned IPs: 95, cooldown IPs: 5"}
問題在於,這些 cooldown 中的 IP 似乎仍然會被算進可用 IP。於是,在 WARM_ENI_TARGET=0 且 WARM_IP_TARGET=0 這種情況下,系統得等到所有 IP 都真的被視為用盡之後,才會繼續補 IP:
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"ipamd/ipamd.go:661","msg":"IP stats - total IPs: 100, assigned IPs: 100, cooldown IPs: 0"}
{"level":"debug","ts":"2024-02-21T20:39:45.367Z","caller":"ipamd/ipamd.go:679","msg":"Starting to increase pool size"}
...
雖然我當時覺得自己好像挖到了一塊先前沒太多人說明清楚的區域,但畢竟我不是 CNI maintainer,所以我還是找了 EKS 團隊一起確認這些觀察。到這裡,我們大致可以整理出 CNI 外掛為 Pod 配置 IP 的流程:
- 當 Pod 被排程到某台節點時:
- [Kubernetes scheduler] 把 Pod 指派到節點
- [Kubelet] 啟動 Pod,並呼叫 CNI 外掛(
ADDrequest) - [ipamd] 從 warm pool 配出一個 IP
- [ipamd] 如果 warm pool 沒有可用 IP,就呼叫 EC2 API,新增 ENI 或配置更多 secondary IP
- 當 Pod 從節點上移除時:
- [Kubernetes API] 將 Pod 狀態更新為
Terminating - [Kubelet] 終止 Pod,並呼叫 CNI 外掛清除 network namespace(
DELrequest) - [ipamd] 釋放該 Pod 的 IP,並標記為未指派
- [ipamd] 該 IP 進入 30 秒的 cooldown period(
IP_COOLDOWN_PERIOD) - [ipamd] cooldown 結束後,這個 IP 才能再次被分配
- [Kubernetes API] 將 Pod 狀態更新為
IP_COOLDOWN_PERIOD 預設最少就是 30 秒,而且這不是隨便設的。這段時間是故意保留給像 kube-proxy 這類網路元件,讓它們有足夠時間更新節點上的 iptables 規則,確保某個曾經被註冊為有效 endpoint 的 IP 不會太快被重複利用。5
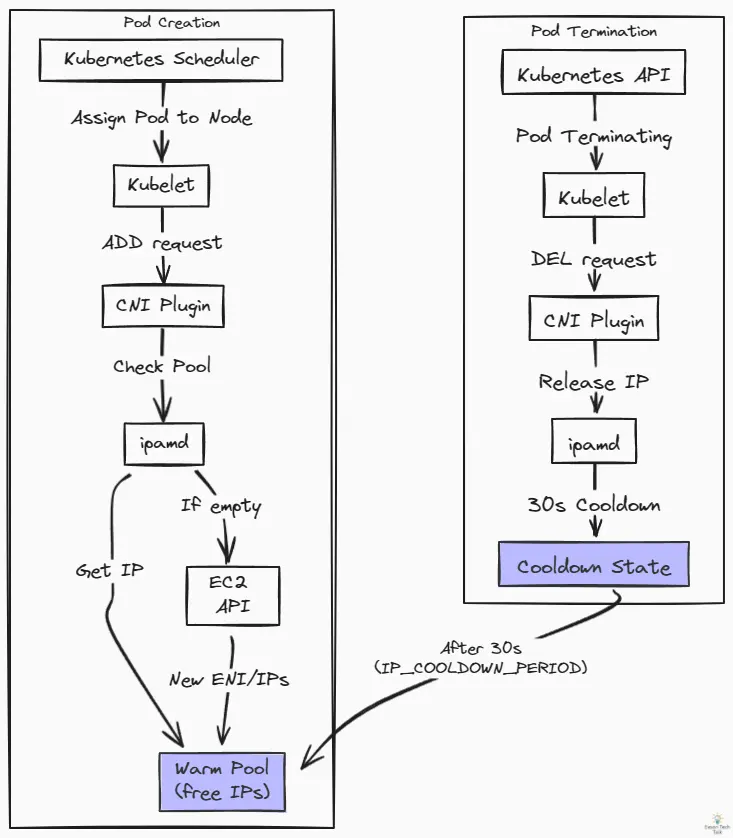
Pod IP 指派與 hydration
和 EKS 團隊確認後,我了解到 Pod IP 指派與 IP hydration 其實是並行進行的。也就是說,當新 Pod 持續建立並索取 IP 的同時,hydration 流程也在背景中同步運作,努力把 warm pool 補回設定值。不過,在快速擴縮事件中,IP 被消耗的速度可能比 hydration 補 IP 還快,因此即使整體系統設計沒有壞掉,也仍然會暫時出現 IP 配置失敗。
Pod IP 指派
當 Pod 在 CNI ADD 流程中要求一個 IP 時,外掛會先檢查 warm pool 是否有預先配置好的 IP。如果有,就立刻指派;如果沒有,就會回傳 "no available IP addresses":
{"level":"error","ts":"2024-02-21T20:39:45.367Z","caller":"datastore/data_store.go:607","msg":"DataStore has no available IP/Prefix addresses"}
{"level":"info","ts":"2024-02-21T20:39:45.367Z","caller":"rpc/rpc.pb.go:863","msg":"Send AddNetworkReply: IPv4Addr: , IPv6Addr: , DeviceNumber: -1, err: AssignPodIPv4Address: no available IP/Prefix addresses"}
週期性 IP Hydration
- CNI 外掛會每 5 秒 做一次檢查,確認目前可用 IP 是否符合設定目標:
WARM_IP_TARGET:希望保留的 warm IP 數量WARM_ENI_TARGET:希望保留的 warm ENI 數量
- 如果可用 IP 低於目標,外掛就會:
- 先嘗試在既有 ENI 上配置更多 secondary IP
- 必要時再替節點掛上新的 ENI
- 在快速擴縮時,由於 hydration 速度慢於 IP 指派,Pod 會先看到
"ip address not available"之類的錯誤,直到新 IP 補上
- 這整個流程需要時間,因為背後涉及 EC2 API 呼叫。這也是為什麼 warm pool 很重要,它可以:
- 降低 Pod 啟動延遲
- 讓擴縮更平順
- 避免在突發流量時撞上 IP 耗盡
下面這張圖可以幫助理解 Pod IP 指派和 hydration 之間的關係。CNI 外掛中的 ipamd 會同時管理這兩條流程。
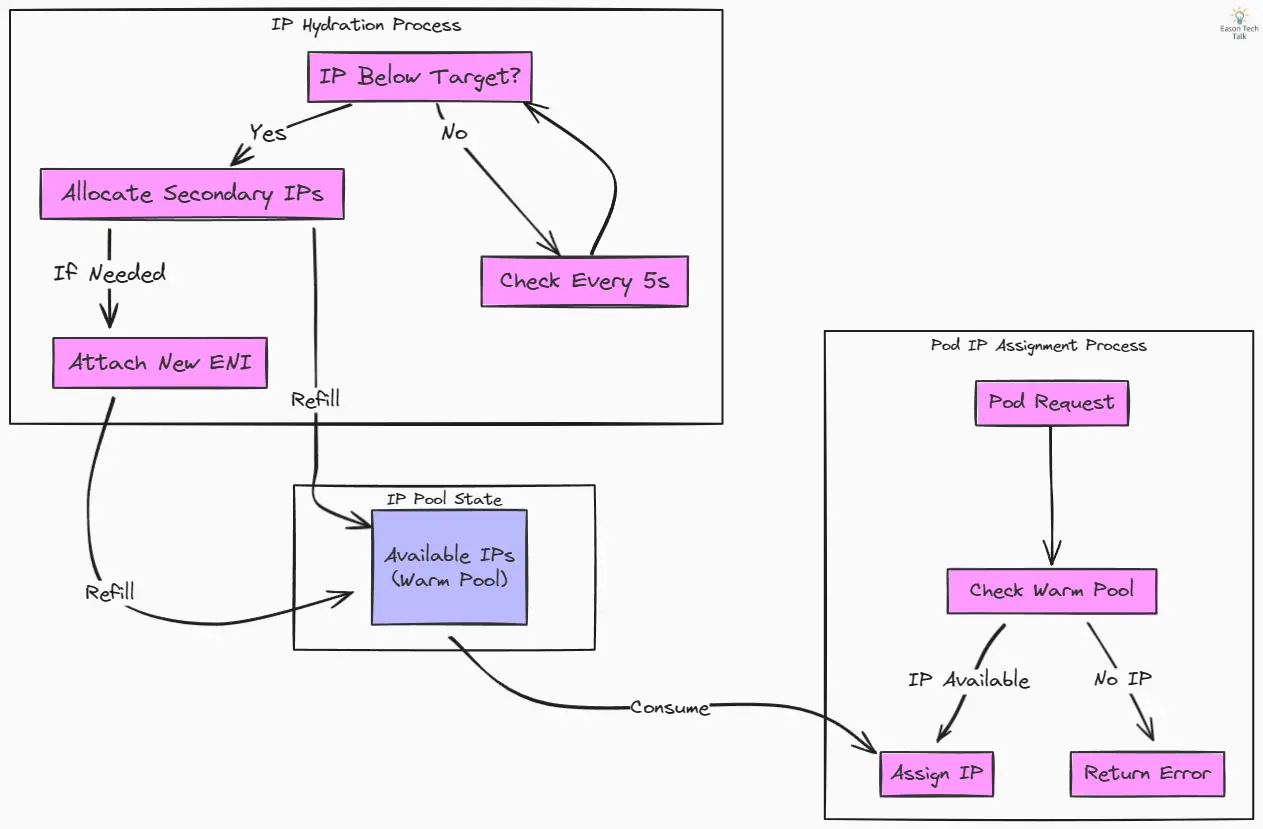
這張圖可以把整體關係說得更清楚:warm pool 很像 token bucket 裡的桶子,一邊被 Pod IP 指派流程持續消耗,一邊又由 hydration 流程不斷補回。hydration 的任務是讓池子維持在目標水位,而 Pod 指派流程則是從這個池子裡即時取用 IP。
重要提醒: 處於 cooldown period 的 IP,在 CNI 外掛眼中仍會被算成「available」。這樣設計的原因,是避免系統因為一有 IP 進入 cooldown 就立刻去補新 IP,進而製造更多 EC2 API 呼叫。對大多數場景來說,這種做法能讓整體資源利用維持平衡,因為預設 30 秒後,這批 IP 就會重新回到可用狀態。
冷卻期帶來的挑戰
這次分析讓我學到一件文件裡不太容易直接看出來的事:cooldown period 其實會帶來一種很微妙的副作用。當 Pod 被快速建立、刪除、再建立時,剛釋放的 IP 雖然從帳面上看「存在」,但因為還在 cooldown,所以暫時不能重複使用。這種行為在自動化部署或高頻率滾動替換時,特別容易放大問題。
其中一種最棘手的情況,就是 Pod churn rate 很高,卻又把 WARM_ENI_TARGET 設得很低。這時候,某個節點在每次 Pod 被移除後,都可能有長達 30 秒無法讓新 Pod 啟動。原因如下:
- IP 被解除指派後,會先進入 30 秒 cooldown
- cooldown 中的 IP 仍然會被算進 warm target
- 系統誤以為 warm IP 仍然足夠,但實際上根本沒有能立即使用的 IP
在 Neon 的事故4 中,工程團隊也曾反覆調整 WARM_IP_TARGET,想要解決 Pod 啟動失敗與 IP 耗盡問題。但從生產現場的觀察來看,當 Pod 已經啟動失敗時才去改 CNI 參數,其實沒有辦法有效止血。單純調整 WARM_IP_TARGET,並不能處理真正的容量限制。
WARM_IP_TARGET 的迷思
CNI 外掛支援 WARM_IP_TARGET,用來定義所有已掛載 ENI 上,希望額外保留多少個可立即使用的 warm IP。它的本意是告訴外掛:warm pool 至少要維持在某個水位。
乍看之下,從 ipamd 釋放一些 IP,似乎可以節省資源、避免過度消耗子網路 IP;但這個策略其實很容易製造「看起來有 IP、實際上不能用」的錯覺。因為 cooldown 中的 IP 仍會被算進 warm target,外掛就不會主動補新 IP,即使這些 IP 此刻根本拿來不了。結果就是在高 Pod churn 的場景中,特別是 Pod 一邊刪除、一邊建立時,IP 配置失敗反而更容易發生。
當你把 WARM_IP_TARGET 設為很低,甚至是 0,再搭配:
WARM_IP_TARGET: 0MINIMUM_IP_TARGET: 0WARM_ENI_TARGET: 0
ipamd 就會變得非常被動,只有在節點上完全沒有可用 IP 時,才會去補新的 IP。這代表它只會在以下兩個條件同時成立時,才開始新增 IP:
- 節點上的所有 IP 都已經分配給 Pod
- 這台節點在過去 30 秒內沒有任何 Pod 結束,因此沒有 IP 處於 cooldown 狀態
此外,如果你本來就預期會有突發流量,並且同時會有大量 Pod 併發啟動,那麼把這些值設得太低,還會提高撞上 EC2 API 限流的風險,最終甚至更容易把子網路裡的 IP 提前耗掉。這種設定只適合在真的很需要節省 IP,而且 Pod churn 很低的情況下使用。
講白一點,WARM_IP_TARGET 比較適合用在小型叢集,或是 Pod churn 極低的叢集。除此之外,也建議把 MINIMUM_IP_TARGET 設成略高於你預期每台節點會承載的 Pod 數量。6
長期解法
VPC 設計改善
如果你要支撐可持續擴縮,從架構上可以考慮以下幾個方向:
- 使用更大的 CIDR block:VPC 一開始就要把未來成長空間規劃進去
- 使用 secondary CIDR:如果子網路 IP 快用完,可以利用 VPC secondary CIDR 來擴充子網路容量。這種方式會加入不可路由的位址範圍(RFC 6598:
100.64.0.0/10),讓工作負載可以部署到新的子網路 - 為 Kubernetes Pod 工作負載使用獨立子網路:把 Pod IP 和其他 VPC 資源使用的位址空間分開,可以降低衝突、讓 IP 管理更單純,也更利於容量規劃與故障排查
快速擴縮的建議設定
如果你想降低快速擴縮時的瓶頸與 IP 配置錯誤,建議這樣做:
- 提高 warm pool 目標:對於已經出現擴縮問題的叢集,建議
WARM_ENI_TARGET至少設為 2。如果你預期會在短時間內擴到數百個 Pod:- 先確認你的執行個體類型每張 ENI 可以提供多少 IP
- 視情況增加節點數,或提高
WARM_ENI_TARGET
- 設定
MINIMUM_IP_TARGET:建議設成略高於每台節點預期的 Pod 數量6
範例
在沒有啟用 Prefix Delegation 的情況下,m5.large 每台節點最多能用 10 個 IP,並支援 3 張 ENI,因此單一節點最多能跑 29 個 Pod。如果你希望在 30 秒內,以理想效能突發建立 100 個 Pod,建議至少準備:
- EC2 執行個體數量(
m5.large):4 台 WARM_ENI_TARGET:3
先把節點預先擴到這個規模後,你就會有 116 個可用 IP(29 個 IP x 4 台節點),足以支撐這種快速部署需求。
Prefix Delegation 模式
在預設情況下,IP 配置能力仍然受限於各種 EC2 執行個體類型所能支援的 ENI 數量。若想進一步提高可用 IP,AWS VPC CNI 外掛還支援 Prefix Delegation 模式,也就是改用 subnet prefix,而不是逐一配置單獨 IP。
對於需要更高 Pod 密度的叢集,啟用 Prefix Delegation 後,可用 IP 數量可以顯著增加。當你設定 ENABLE_PREFIX_DELEGATION=true 時,VPC CNI 會配置 /28(也就是 16 個 IP)的 IPv4 prefix,而不是單一 IP。
若場景是快速擴縮,你也可以提高 WARM_PREFIX_TARGET,讓系統即使只用到現有 prefix 裡的一個 IP,也會預先再配置完整的 /28 prefix block。要注意的是,如果同時設定了 WARM_IP_TARGET 與 MINIMUM_IP_TARGET,它們會覆蓋 WARM_PREFIX_TARGET。
重要: Prefix Delegation 模式要求子網路中存在連續的 /28 區塊,並且還要符合其他前置條件。在啟用 Prefix Delegation 的情況下,將 WARM_PREFIX_TARGET 設為 0,或同時把 WARM_IP_TARGET 和 MINIMUM_IP_TARGET 設為 0,都是不支援的。
監控與可觀測性
AWS VPC CNI 外掛在每台節點上都提供了一個本地 metrics endpoint,可用來觀察 IP 配置、ENI 狀態與外掛健康度。你可以透過 http://localhost:61678/metrics 取得 Prometheus 格式的指標。
從這個 endpoint 可以看到的關鍵指標包括:
- awscni_assigned_ip_addresses:目前已經指派給 Pod 的 IP 數量
- awscni_eni_allocated:目前節點上已掛載的 ENI 數量
- awscni_eni_max:該執行個體類型最多可掛載的 ENI 數量
- awscni_total_ip_addresses:外掛目前管理的總 IP 數量
// get ipamd metrics
root@ip-192-168-188-7 bin]# curl http://localhost:61678/metrics
# HELP awscni_assigned_ip_addresses The number of IP addresses assigned
# TYPE awscni_assigned_ip_addresses gauge
awscni_assigned_ip_addresses 46
# HELP awscni_eni_allocated The number of ENI allocated
# TYPE awscni_eni_allocated gauge
awscni_eni_allocated 4
# HELP awscni_eni_max The number of maximum ENIs can be attached to the instance
# TYPE awscni_eni_max gauge
awscni_eni_max 4
# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 5.6955e-05
go_gc_duration_seconds{quantile="0.25"} 9.5069e-05
go_gc_duration_seconds{quantile="0.5"} 0.000120296
go_gc_duration_seconds{quantile="0.75"} 0.000265345
go_gc_duration_seconds{quantile="1"} 0.000560554
go_gc_duration_seconds_sum 0.03659199
go_gc_duration_seconds_count 211
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 20
...
雖然外掛本身提供了 introspection endpoint,但若要及早發現 IP 配置風險,還是需要把完整監控做好。下面兩個方案很實用:
- AWS CNI Metrics(Grafana dashboard):可觀察 ENI 掛載速率、IP 配置模式、擴縮表現,以及 warm pool 狀態
- CNI Metrics Helper(CloudWatch metrics):可把 ENI 掛載率與 IP pool 利用率送進 CloudWatch
FAQ
會不會太浪費 Private IP?
把 warm pool 參數往上調,的確會更積極占用 private IP,但多數情況下,這個成本其實遠低於生產事故帶來的代價:
- 不會額外收費:AWS 不會對 private IP 位址本身另外計價
- 能避免可預防的 outage:比起節省少量 IP,更值得優先避免部署中斷與生產事故
- 提升擴縮可靠性:遇到突發流量時,叢集更有機會穩定撐住
在大型 EKS 叢集中,低峰期保留一批暫時閒置的 IP,確實是一種取捨;但比起一味追求 private IP 的極致利用率,先規劃足夠大的 CIDR 與專用子網路,帶來的效益通常更高。更何況,CNI 外掛配置出去的 private IP 本身並不額外收費。
重點整理
把 AWS VPC CNI 外掛與 IP 配置問題拆解之後,我會把實務重點濃縮成下面幾點:
- 主動做容量規劃:子網路與 CIDR block 最好至少以預估需求的兩倍來規劃,這個緩衝對可持續擴縮非常重要。如果真的遇到 IP 耗盡,也還能用新增子網路、導入 secondary CIDR 等方式降低對生產環境的衝擊
- 優化 warm pool:較高的
WARM_ENI_TARGET通常會帶來更好的擴縮穩定性與效能。維持充足的 warm pool、並在需要時預先多掛幾張 ENI,有幾個明顯好處:- 減少 EC2 API 呼叫:降低擴縮過程中被節流的風險
- 加快 Pod 啟動:Pod 可直接取得 IP,不必等待新 ENI 掛載完成
- 提升叢集穩定性:避免快速擴縮時出現連鎖失敗
- 監控不可少:務必把指標監控做好,才能及早發現並預防 IP 耗盡
結論
add cmd: failed to assign an IP address to container 這個錯誤,本質上是 EKS 叢集擴縮時的一個關鍵瓶頸,足以直接影響應用程式部署與服務可用性。要在快速擴縮期間維持叢集穩定,關鍵就在於理解 WARM_ENI_TARGET、WARM_IP_TARGET 和 MINIMUM_IP_TARGET 之間是如何互相作用的。
預設的 CNI 設定對很多場景來說已經夠用,但如果你的生產環境本來就會頻繁快速擴縮,就應該提早調整這些參數。像是把 WARM_ENI_TARGET 提高到 2 以上,再搭配合適的 IP target,通常就能提供足夠緩衝,降低 IP 配置失敗的機率。
隨著容器化工作負載規模越來越大、型態越來越複雜,這些 CNI 配置細節對平台穩定性的影響也只會越來越大。把 IP 配置規劃做好,最終換來的是更少的 outage、更高的部署成功率,以及更穩定的整體叢集表現。
致謝
特別感謝 Neon Engineering 團隊分享寶貴的生產實戰經驗與觀察。他們在大規模 EKS 部署上的經驗,以及實際回饋,幫助我驗證了文中的很多判斷,也讓這篇文章能加入更多有價值的實務視角。
我也很感謝 EKS networking 團隊,以及我的同事 Maicon 和 Robin,在調查與釐清這起複雜問題的過程中提供協助。他們的專業與投入,是這次找出根因並整理出可行解法的關鍵。
這篇分析之所以能兼顧深度與實用性,很大一部分要歸功於大家願意提供詳細的技術意見,也願意分享來自生產環境的一手經驗。
文中的建議主要來自我個人的觀察與實務經驗。如果你也遇過類似情況,歡迎分享你的經驗,或直接到 GitHub issue 參與討論。這篇對 EKS CNI IP 配置問題的深入分析,源自我親自參與調查的一起真實事件。這次經驗不只讓我更理解 AWS CNI 的內部運作,也促使我把這些整理成文。希望這些內容能幫助你在 Amazon EKS 上打造更可靠的基礎設施。
參考資料
