Troubleshooting EKS Managed Node Group PodEvictionFailure Error
As mentioned in the previous article, in 2019 EKS released a new API that supports Managed Node Groups 1 and introduced the error Ec2SubnetInvalidConfiguration. This article will further explore the PodEvictionFailure error encountered during the Managed Node Group upgrade process.
The PodEvictionFailure error is a common error encountered during node group upgrades in EKS, typically when using the AWS Console, the aws eks update-nodegroup-version command or the UpdateNodegroupVersion API call. This article will further analyze the reasons, common scenarios, and solutions to this error.
How to Identify the Issue
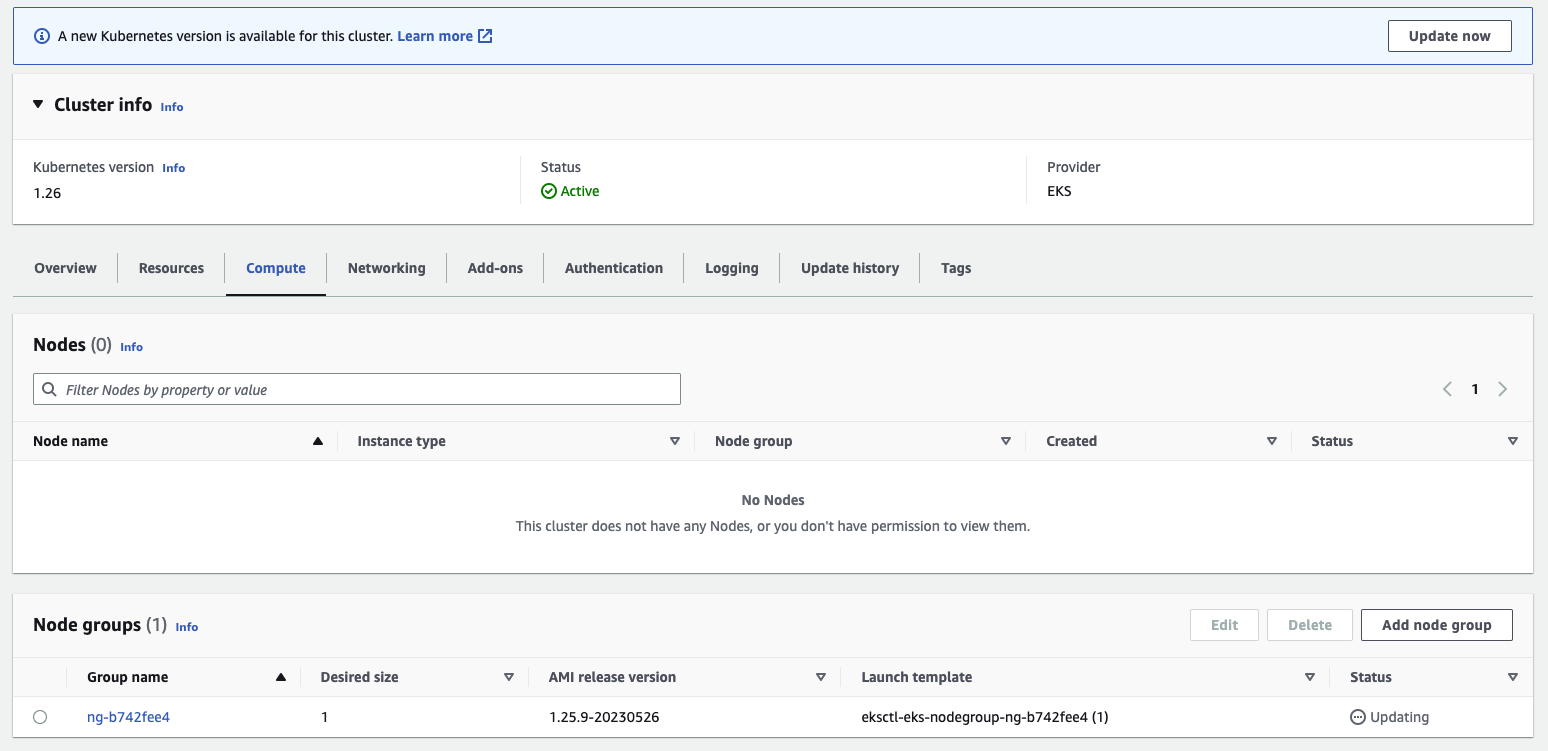
To check if there are any PodEvictionFailure errors in the EKS Managed Node Groups, you can use the EKS Console or AWS CLI command to check for any issues. For example, by clicking the Compute tab under Cluster, then clicking on Node groups, you can check if there are any error messages related to the upgrade events in the Update history tab:
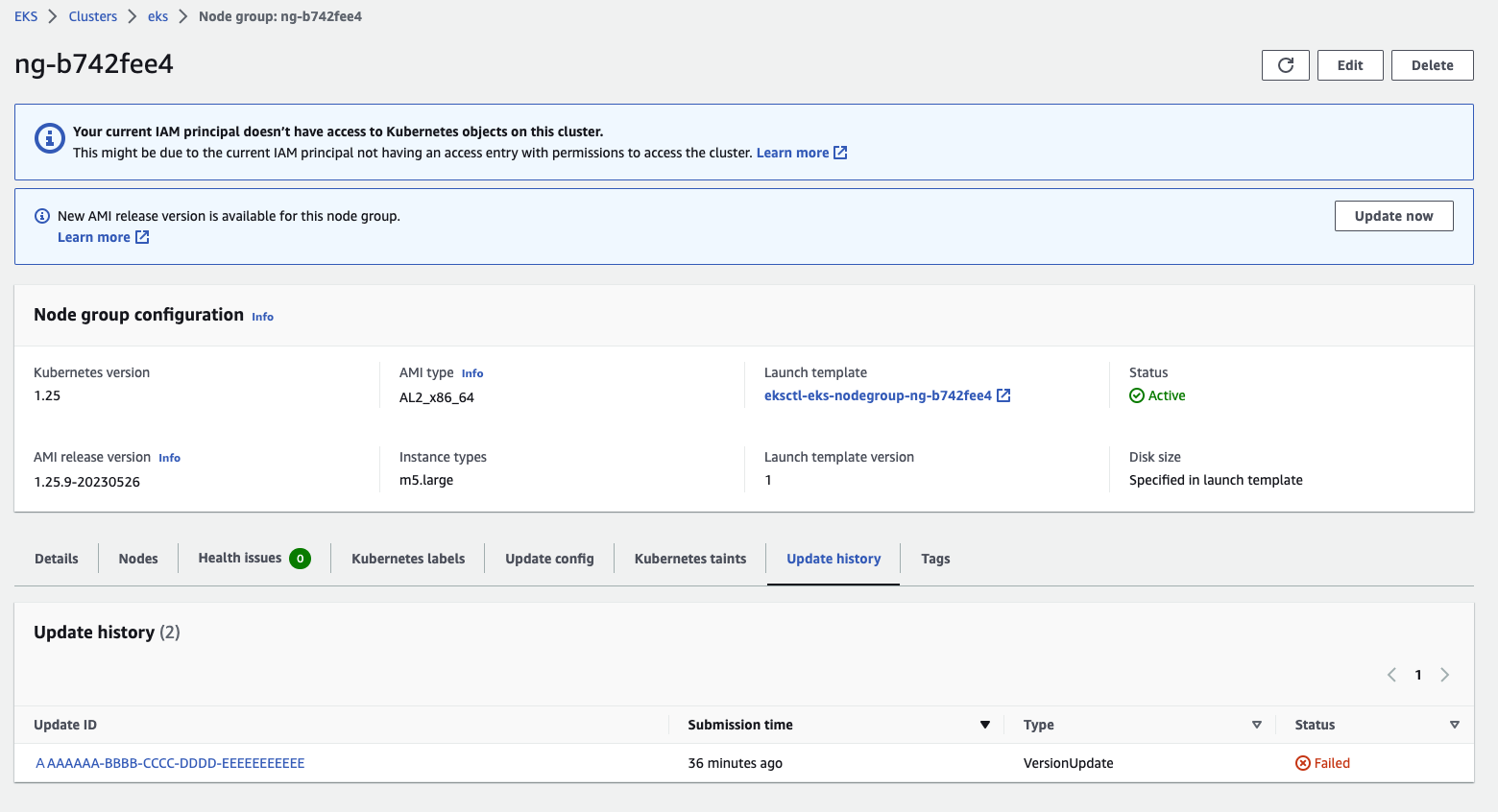
By clicking on an individual upgrade event, you can see more detailed information about the error:
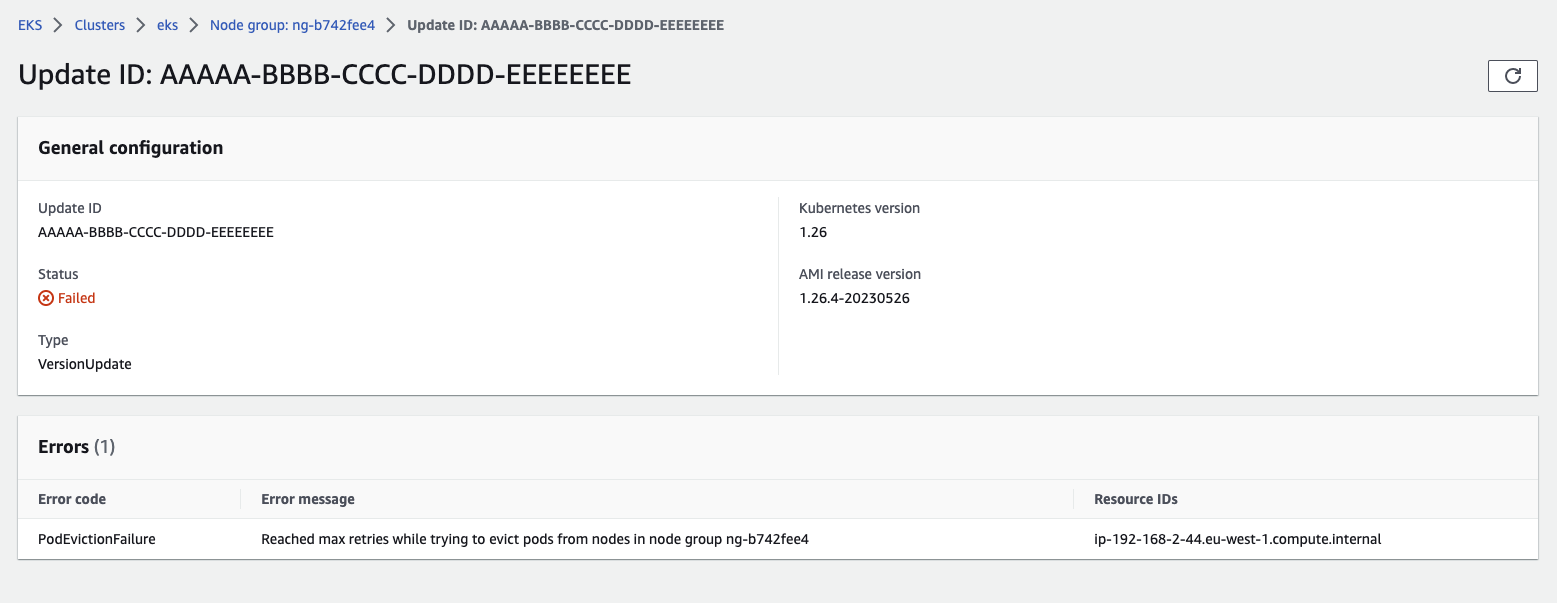
According to the EKS Managed Node Group upgrade process 2, if the upgrade or creation of a node takes more than 15-20 minutes, it is likely that there are problems with the working nodes. After a period of time, it is usually possible to further investigate the possible causes using this information. Here’s an example of using an AWS CLI command:
$ aws eks list-updates --name <CLUSTER_NAME> --nodegroup-name <NODE_GROUP_NAME>
{
"updateIds": [
"AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEEE"
]
}
$ aws eks describe-update --name <CLUSTER_NAME> --nodegroup-name <NODE_GROUP_NAME> --update-id AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEEE
{
"update": {
"id": "AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEEE",
"status": "Failed",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "ReleaseVersion",
"value": "1.26.4-20230526"
}
],
"createdAt": "2023-06-03T17:19:38.068000+00:00",
"errors": [
{
"errorCode": "PodEvictionFailure",
"errorMessage": "Reached max retries while trying to evict pods from nodes in node group <NODE_GROUP_NAME>",
"resourceIds": [
"ip-192-168-2-44.eu-west-1.compute.internal"
]
}
]
}
}
In the example above, the upgrade failed due to exceeding the maximum number of retries when trying to stop Pods during the upgrade, and the upgrade status is Failed.
Common Scenarios and Causes
Pod Disruption Budget (PDB)
Pod Disruption Budget (PDB) 3 is a Kubernetes resource object used to ensure that the availability of a particular deployment is not disrupted during maintenance, upgrades, rollbacks, etc. PDB is typically used to set the minimum number of Pods running. When performing maintenance operations, Kubernetes ensures that the number of Pods running in the current cluster is not less than this number. This ensures that the availability of the service is not affected or interrupted during maintenance.
Here’s an example of a PDB:
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: my-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: my-app
In this example, we set a PDB with a minimum availability of 2, and the selector is app=my-app. This means that when performing maintenance operations, Kubernetes ensures that at least 2 Pods that match the selector are available.
PDB configuration can help ensure the availability of Pods during maintenance operations and can reduce the likelihood of PodEvictionFailure errors. When designing applications, it is recommended that PDB be used to ensure the availability of the application.
Relationship between PodEvictionFailure and PDB
The PodEvictionFailure error is usually caused by EKS being unable to stop Pods on the nodes to be updated. When performing Managed Node Group upgrade and replacement operations, if the number of target Pods running on the nodes to be updated is less than the minimum value set in PDB, Kubernetes will refuse to delete Pods. In this case, the PodEvictionFailure error may occur during the upgrade process. For example, the following environment deploys a Kubernetes Deployment (nginx-deploymnet) and runs it on the only node ip-192-168-2-44.eu-west-1.compute.internal in the current environment:
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default pod/nginx-deployment-ff6774dc6-dntfm 1/1 Running 0 45m 192.168.7.16 ip-192-168-2-44.eu-west-1.compute.internal
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS
default deployment.apps/nginx-deployment 1/1 1 1 49m nginx
At the same time, the following PodDisruptionBudget resource is set in the environment (all Pods of this nginx-deployment have the app=nginx label):
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: nginx-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: nginx
When performing update or replacement node processes, we usually need to mark the nodes as unscheduled and stop the applications running on them. Kubernetes provides methods like kubectl drain to support this operation 4. Once kubectl drain marks the node as being in maintenance mode, it triggers Kubernetes Scheduler to reschedule the Pods on the node.
In addition, before rescheduling, the kubectl drain command marks the node as unscheduled so that new Pods are not scheduled on the node. At the same time, the Pods that are already running on the node will be stopped one by one. However, in the case of violating the PodDisruptionBudget, such an operation is likely to fail. For example, the following is an example that cannot be stopped correctly in the presence of PDB:
$ kubectl drain ip-192-168-2-44.eu-west-1.compute.internal --ignore-daemonsets --delete-emptydir-data
node/ip-192-168-2-44.eu-west-1.compute.internal already cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/aws-node-n9lc5, kube-system/kube-proxy-lwxcb
evicting pod kube-system/coredns-6866f5c8b4-r96z8
evicting pod default/nginx-deployment-ff6774dc6-dntfm
evicting pod kube-system/coredns-6866f5c8b4-h296r
pod/coredns-6866f5c8b4-r96z8 evicted
pod/coredns-6866f5c8b4-h296r evicted
evicting pod default/nginx-deployment-ff6774dc6-dntfm
error when evicting pods/"nginx-deployment-ff6774dc6-dntfm" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod default/nginx-deployment-ff6774dc6-dntfm
error when evicting pods/"nginx-deployment-ff6774dc6-dntfm" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
evicting pod default/nginx-deployment-ff6774dc6-dntfm
error when evicting pods/"nginx-deployment-ff6774dc6-dntfm" -n "default" (will retry after 5s): Cannot evict pod as it would violate the pod's disruption budget.
...
Deployment allows deployment on nodes with taints
In Kubernetes, Taints and Tolerations are mechanisms used to control whether Pods can be scheduled on specific nodes. Taints are labels applied to nodes that indicate specific restrictions or requirements for the node. Tolerations, defined by the Pod, tell Kubernetes which taints the Pod can tolerate, allowing or preventing the Pod from being scheduled on nodes that meet certain conditions. 5
However, incorrect tolerations settings can result in applications being continuously scheduled to nodes where they are expected to be replaced. For example, the following example ignores the Taint settings associated with the Node:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
...
template:
...
spec:
containers:
- name: nginx
image: nginx
tolerations:
- operator: "Exists"
...
As mentioned earlier, the kubectl drain command marks the node as unschedulable before rescheduling, so new Pods are not scheduled to that node. During this operation, Kubernetes also sets a Taint on the node: node.kubernetes.io/unschedulable:NoSchedule.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-2-44.eu-west-1.compute.internal Ready,SchedulingDisabled <none> 126m v1.25.9-eks-0a21954
$ kubectl describe node
Name: ip-192-168-2-44.eu-west-1.compute.internal
...
Taints: node.kubernetes.io/unschedulable:NoSchedule
However, when using the above tolerations settings, the corresponding scheduling behavior for the application is ignored. For example, the following is the process of continuously scheduling Pods even after running kubectl drain on the Node:
NAME READY STATUS RESTARTS AGE IP NODE
nginx-deployment-6876484bcc-h28sn 1/1 Running 0 25s 192.168.9.175 ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-h28sn 1/1 Terminating 0 38s 192.168.9.175 ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-kbgw6 0/1 Pending 0 0s <none> ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-kbgw6 0/1 ContainerCreating 0 0s <none> ip-192-168-2-44.eu-west-1.compute.internal
nginx-deployment-6876484bcc-kbgw6 1/1 Running 0 2s 192.168.18.140 ip-192-168-2-44.eu-west-1.compute.internal
For EKS Managed Node Group upgrade operations, the node is not completely disabled for Pods and remains in an uncleared state, causing a PodEvictionFailure error during the update process.
Pod has an error
If the problem is not caused by the above, it may indicate that the Pod cannot be shut down for some reason, such as the application interacting with NFS but the operation is stuck in I/O behavior, network problems, or resource constraints (such as high CPU load causing the system to be unresponsive).
To determine the status and cause of the error Pod, you can use the following commands to view detailed Pod status or related log records to determine the cause of the problem:
$ kubectl describe pod
$ kubectl logs <POD_NAME>
Solution and Steps
Pod Disruption Budget (PDB)
To check if the upgrade was affected by Pod Disruption Budget (PDB), you can use the following command to confirm the current PDB settings:
kubectl get pdb --all-namespaces
If EKS Control Plane Logging is enabled, you can also use CloudWatch Log Insights to filter and check for any related failure events.
- Under
Cluster>Logging, selectAuditto open the Amazon CloudWatch Console. - In the Amazon CloudWatch console, select
Logsand then selectLog Insightsto filter the audit logs generated by EKS.
The following are examples of query sentence:
fields @timestamp, @message
| filter @logStream like "kube-apiserver-audit"
| filter ispresent(requestURI)
| filter objectRef.subresource = "eviction"
| display @logStream, requestURI, responseObject.message
| stats count(*) as retry by requestURI, responseObject.message
By viewing the audit logs, you can further confirm whether there is any specific information related to Pod Disruption Budget in the events of disabling the Pod:
If the upgrade fails due to PDB, you can modify or remove the PDB and try to upgrade again:
# Edit
$ kubectl edit pdb <PDB_NAME>
# Delete
$ kubectl delete pdb <PDB_NAME>
Incorrect Tolerations Configuration
As mentioned earlier, incorrect tolerations settings may cause the application to continue to be scheduled on nodes that are expected to be replaced. You can solve this problem by correcting the corresponding deployment settings:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
...
template:
...
spec:
containers:
- name: nginx
image: nginx
tolerations: <---- Corrected settings
- operator: "Exists"
...
Force Update
By default, EKS Managed Node Group upgrades use the Rolling update method, which will comply with the Pod Disruption Budget (PDB) settings during the upgrade process. If the upgrade process fails due to PDB, the upgrade process will fail.
If the upgrade cannot be completed correctly due to PDB or other reasons, you can also choose Force update during the upgrade process to upgrade. This option will ignore the PDB settings during the upgrade process. Regardless of whether PDB issues occur, the nodes will be forcibly restarted for the update.

The following are examples of using AWS CLI:
$ aws eks update-nodegroup-version --cluster-name <CLUSTER_NAME> --nodegroup-name <NODE_GROUP_NAME> --force
The following are examples of using eksctl:
$ eksctl upgrade nodegroup --cluster <CLUSTER_NAME> --name <NODE_GROUP_NAME> --force-upgrade
Summary
In this article, we mentioned the common scenarios and causes of the PodEvictionFailure error encountered during the Managed Node Group upgrade process in EKS, and put forward relevant solutions, such as:
- Check whether the PodDisruptionBudget (PDB) settings are incorrect. If the upgrade fails due to PDB, you can modify or remove the PDB and try to upgrade again.
- Check whether the Tolerations settings are incorrect. Incorrect Tolerations settings may cause the application to continue to be scheduled on nodes that are expected to be replaced, and the corresponding deployment settings need to be corrected.
Finally, if the above methods still cannot solve the problem, you can choose Force update to upgrade. This option will ignore the PDB settings during the upgrade process and forcibly restart the nodes for the update6 7.
By following the above solutions and related steps, I hope to help you read this article more directionally to troubleshoot and solve this error.
References
