
JobSet Troubleshooting: Why Follower Pods Hit "node selector not set"
When you use JobSet to run distributed training on multi-slice TPU or GPU workloads, its leader-follower mechanism first schedules the leader Pod, then uses a mutating webhook to read the topology label from the leader’s node and patch the corresponding nodeSelector onto the follower Pods. This ensures that the Pods in the same group are scheduled into the same topology domain. The design works well under normal conditions. But when accelerator capacity is insufficient and the leader Pod stays stuck in Pending, you may see a confusing error:
admission webhook "vpod.kb.io" denied the request: follower pod node selector not set
Your first instinct may be to inspect the follower Pod’s node selector configuration, but that is not where the real problem lies. After spending several hours debugging this, I found that the error message is really a false lead. It hides the true root cause and makes you think something is wrong with the JobSet configuration, when in reality the cluster may simply lack the capacity needed to schedule the leader Pod. This misleading error appears because the validating webhook in pkg/webhooks/pod_webhook.go checks the follower’s NodeSelector before it verifies whether the leader has already been scheduled.
After tracking this down, I opened Issue #1187 and submitted two PRs to address it from different angles. This article draws on that real debugging experience to explain JobSet’s leader-follower scheduling model, clarify how the mutating and validating webhooks interact, and show why changing the validation order turns a misleading error into useful diagnostic information.
The code excerpts in this article are based on the JobSet
mainbranch after the refactor in PR #1159. That PR merged logic previously split acrosspod_mutating_webhook.goandpod_admission_webhook.gointo a singlepod_webhook.go, using the controller-runtimeadmission.Defaulterandadmission.Validatorinterfaces. Inrelease-0.11and earlier, the same logic lives in two separate files, but the validation-order issue is the same.
Overview of the JobSet Leader-Follower Mechanism
When JobSet handles TPU multi-slice workloads or any workload that requires exclusive placement, it uses a leader-follower scheduling model. The core idea is simple: the leader Pod (completion index 0) is scheduled first, and then, when follower Pods are created and enter the admission flow, the mutating webhook reads the topology label from the leader’s node and patches the corresponding nodeSelector onto the follower Pods. This ensures that the followers are scheduled into the same topology domain.
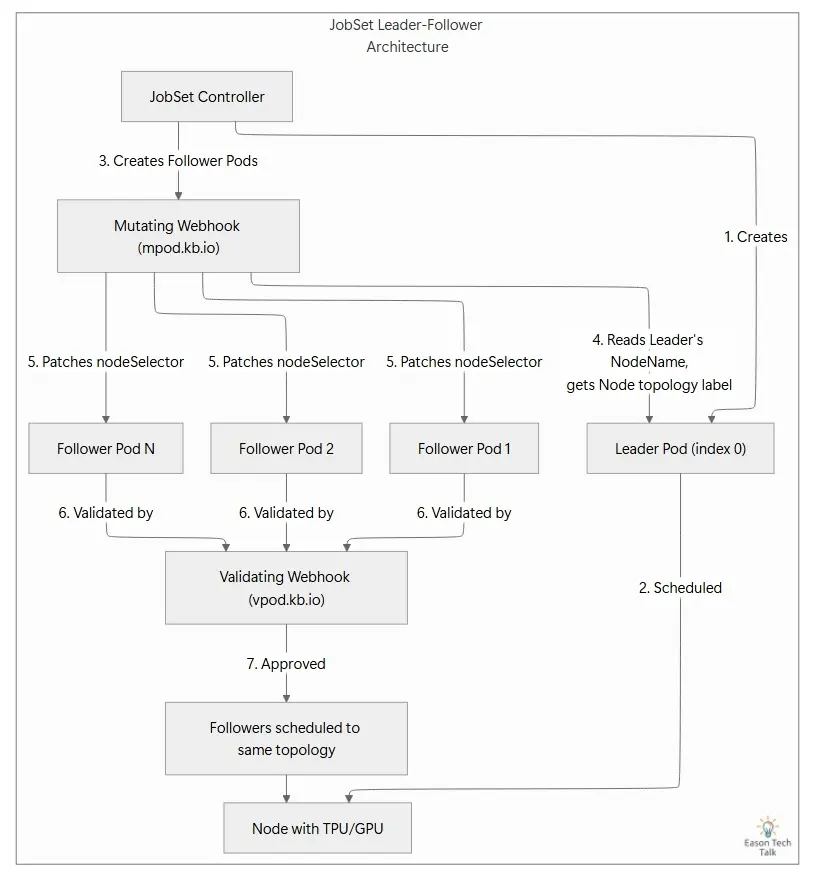
Mutating Webhook: Patching the Node Selector
JobSet’s mutating webhook (mpod.kb.io) intercepts every Pod creation request. For a follower Pod that uses exclusive placement, it calls setNodeSelector:
- It first calls
leaderPodForFollowerto find the corresponding leader Pod, then checks whether the leader’sSpec.NodeNamehas been set. - If the leader has already been scheduled, the webhook calls
topologyFromPodto read the topology label from the leader’s node, such as the node pool name, and patches that value into the follower Pod’snodeSelector. - But if the leader is still
PendingandSpec.NodeNameis empty, the mutating webhook returnsnilimmediately and does not patch anything. The code comments explicitly say that rejecting the follower is left to the validating webhook.
func (p *podWebhook) setNodeSelector(ctx context.Context, pod *corev1.Pod) error {
log := ctrl.LoggerFrom(ctx)
// Find leader pod (completion index 0) for this job.
leaderPod, err := p.leaderPodForFollower(ctx, pod)
if err != nil {
log.Error(err, "finding leader pod for follower")
// Return no error, validation webhook will reject creation of this follower pod.
return nil
}
// If leader pod is not scheduled yet, return error to retry pod creation until leader is scheduled.
if leaderPod.Spec.NodeName == "" {
// Return no error, validation webhook will reject creation of this follower pod.
return nil
}
// Get the exclusive topology value for the leader pod (i.e. name of nodepool, rack, etc.)
topologyKey, ok := pod.Annotations[jobset.ExclusiveKey]
if !ok {
return fmt.Errorf("pod missing annotation: %s", jobset.ExclusiveKey)
}
topologyValue, err := p.topologyFromPod(ctx, leaderPod, topologyKey)
if err != nil {
log.Error(err, "getting topology from leader pod")
return err
}
// Set node selector of follower pod so it's scheduled on the same topology as the leader.
if pod.Spec.NodeSelector == nil {
pod.Spec.NodeSelector = make(map[string]string)
}
log.V(2).Info(fmt.Sprintf("setting nodeSelector %s: %s to follow leader pod %s", topologyKey, topologyValue, leaderPod.Name))
pod.Spec.NodeSelector[topologyKey] = topologyValue
return nil
}
This behavior is expected. If the leader has not been scheduled yet, there is no way to know the topology label of the node it will land on, so there is nothing to patch.
Validating Webhook: Verifying Follower Pod Validity
After the mutating webhook finishes, the vpod.kb.io validating webhook runs ValidateCreate. In pkg/webhooks/pod_webhook.go, that validation flow contains two important checks:
- NodeSelector check: verifies that the follower Pod already has a node selector
- Leader scheduling check: verifies that the leader Pod has already been scheduled
// ValidateCreate validates that follower pods (job completion index != 0) part of a JobSet using exclusive
// placement are only admitted after the leader pod (job completion index == 0) has been scheduled.
func (p *podWebhook) ValidateCreate(ctx context.Context, pod *corev1.Pod) (admission.Warnings, error) {
...
// Do not validate anything else for leader pods, proceed with creation immediately.
if placement.IsLeaderPod(pod) {
return nil, nil
}
// If a follower pod node selector has not been set, reject the creation.
if pod.Spec.NodeSelector == nil {
return nil, fmt.Errorf("follower pod node selector not set")
}
if _, exists := pod.Spec.NodeSelector[topologyKey]; !exists {
return nil, fmt.Errorf("follower pod node selector for topology domain not found. missing selector: %s", topologyKey)
}
// For follower pods, validate leader pod exists and is scheduled.
leaderScheduled, err := p.leaderPodScheduled(ctx, pod)
if err != nil {
return nil, err
}
if !leaderScheduled {
return nil, fmt.Errorf("leader pod not yet scheduled, not creating follower pod. this is an expected, transient error")
}
return nil, nil
}
The core problem is the order of these checks. If the validating webhook checks whether NodeSelector exists before it checks whether the leader has been scheduled, the error message no longer reflects the real problem. A more useful transient error is completely masked, and what the user sees instead is a misleading failure.
The Validation Order Hides the Real Error
What the Failure Looks Like
While running a multi-slice TPU training job on GKE, all follower Pods were rejected with the following message:
admission webhook "vpod.kb.io" denied the request: follower pod node selector not set
At the same time, the webhook server logs from the mutating webhook sometimes contained a much more informative message. When the leader Pod had not yet been created, leaderPodForFollower returned an error that was logged as:
ERROR admission finding leader pod for follower
{"error": "expected 1 leader pod (example-job-0-0), but got 0. this is an expected, transient error"}
The difference matters. In most event output, users see only the first error returned by the validating webhook and assume the follower Pod is misconfigured. The second message, which comes from the mutating webhook, is the one with real diagnostic value. In stricter environments, detailed mutating webhook logs may be visible only to cluster admins, which makes it even easier for ordinary users to be misled by the admission error.
Root Cause: The Validation Order
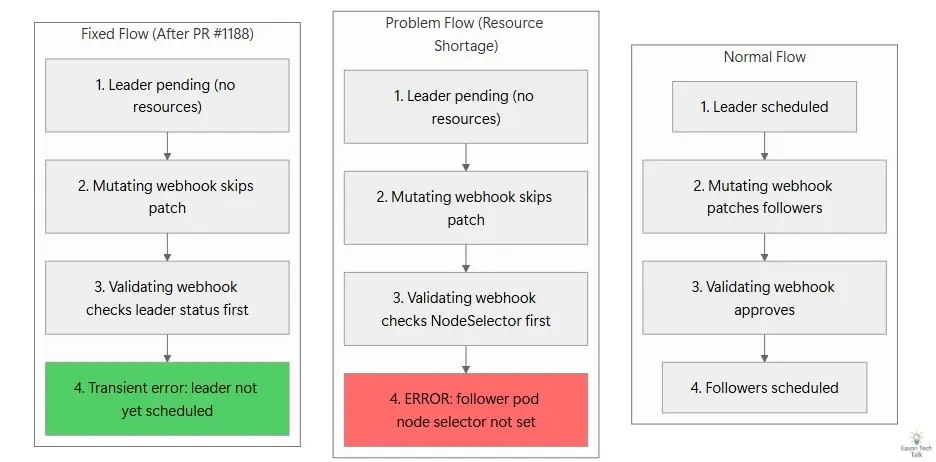
Here is what happens when the leader Pod is stuck in Pending because the cluster does not have enough accelerator capacity:
- A follower Pod is created and enters the admission flow.
- The mutating webhook’s
setNodeSelectorsees thatleaderPod.Spec.NodeNameis empty and returnsnil, so no patch is applied. Rejection is intentionally left to the validating webhook. - The follower Pod enters the validating webhook via
ValidateCreate. - The validating webhook checks
NodeSelectorfirst, sees that it is missing, and immediately rejects the Pod withfollower pod node selector not set. - The leader scheduling check never runs, because execution already stopped at step 4.
As a result, the error message ends up pointing to a downstream symptom rather than the actual root cause:
Insufficient infrastructure capacity (not enough TPU/GPU resources)
└── Leader pod stays Pending (not scheduled)
└── Mutating webhook correctly skips the patch (expected behavior)
└── Follower pod is created without a node selector
└── Validating webhook checks NodeSelector first and rejects it
├── User sees: "follower pod node selector not set"
└── Useful transient error is completely masked ✘
JobSet already contains a well-designed transient error for this situation, but because of the validation order, it never gets surfaced. If the checks were reversed and the leader’s scheduling state were validated first, the user would see:
leader pod not yet scheduled, not creating follower pod. this is an expected, transient error
That message points you directly to the leader Pod’s scheduling state instead of sending you to the wrong place.
The diagram below compares three scenarios: the normal flow, where the leader is scheduled first; the current failure mode, where the validation order masks the useful error; and the corrected flow in the proposed PR, where reordering the checks surfaces the transient error properly.
Troubleshooting the Issue
If you run into this error yourself, the key is simple: do not let the error message send you in the wrong direction. Check the upstream leader Pod first.
First, confirm that the leader Pod exists and has been scheduled:
kubectl get pods -n <namespace> | grep <jobset-name>.*-0-0
If the leader Pod is still Pending, inspect it with describe to see why:
kubectl describe pod <leader-pod-name> -n <namespace>
You will usually find events like this, example:
Warning FailedScheduling 0/10 nodes are available: insufficient google.com/tpu resources
At that point, the root cause for this example becomes clear. The issue is not the follower Pod configuration. The cluster simply does not have enough infrastructure capacity, so the leader cannot be scheduled. The fix is straightforward: make sure the cluster has enough accelerator resources for the leader Pod. Once the leader is successfully scheduled, the mutating webhook will automatically patch the correct node selector onto the follower Pods, and the validating webhook will pass as expected.
The PRs: Improvements in Docs and Code
After identifying the real root cause, I opened Issue #11871 and submitted two PRs to address the problem from different angles:
- PR #11892 (Documentation): adds troubleshooting guidance to the official docs. It has already been merged.
- PR #11883 (Code fix): reorders the validating webhook checks so the more helpful transient error can be surfaced correctly.
PR #1189: Add Troubleshooting Documentation
The first PR improves the documentation. It adds a new troubleshooting section to the official JobSet guide4, explaining that when you see follower pod node selector not set, you should first inspect the leader Pod’s scheduling state instead of changing the follower configuration.
PR #1188: Reorder the Validation Checks
The second PR is the real code-level fix. In pkg/webhooks/pod_webhook.go, it changes the order of the checks inside ValidateCreate. Once merged, when the leader Pod has not been scheduled yet, users will see:
leader pod not yet scheduled, not creating follower pod. this is an expected, transient error
instead of the original misleading follower pod node selector not set.
Conclusion
In distributed systems, bugs with a long chain of cause and effect are common. In the Kubernetes ecosystem, the execution order and interaction between mutating and validating webhooks make it especially easy for the visible symptom to drift away from the real root cause. This example shows why that interaction matters, and how a small change in validation order can turn a misleading error into a much more useful diagnostic signal.
References
-
Issue #1187 - Pod validation webhook obscures leader scheduling state by validating follower NodeSelector too early ↩
-
PR #1189 - docs: add troubleshooting section for follower pod node selector errors ↩
-
PR #1188 - Reorder follower pod validation to surface leader scheduling status ↩
-
JobSet Troubleshooting Guide - 5. Follower pods rejected with “follower pod node selector not set” ↩
